
Stream Computing Framework
Stream Computing Framework
The IoTDB stream processing framework allows users to implement customized stream processing logic, which can monitor and capture storage engine changes, transform changed data, and push transformed data outward.
We call . A stream processing task (Pipe) contains three subtasks:
- Source task
- Processor task
- Sink task
The stream processing framework allows users to customize the processing logic of three subtasks using Java language and process data in a UDF-like manner.
In a Pipe, the above three subtasks are executed by three plugins respectively, and the data will be processed by these three plugins in turn:
Pipe Source is used to extract data, Pipe Processor is used to process data, Pipe Sink is used to send data, and the final data will be sent to an external system.
The model of the Pipe task is as follows:
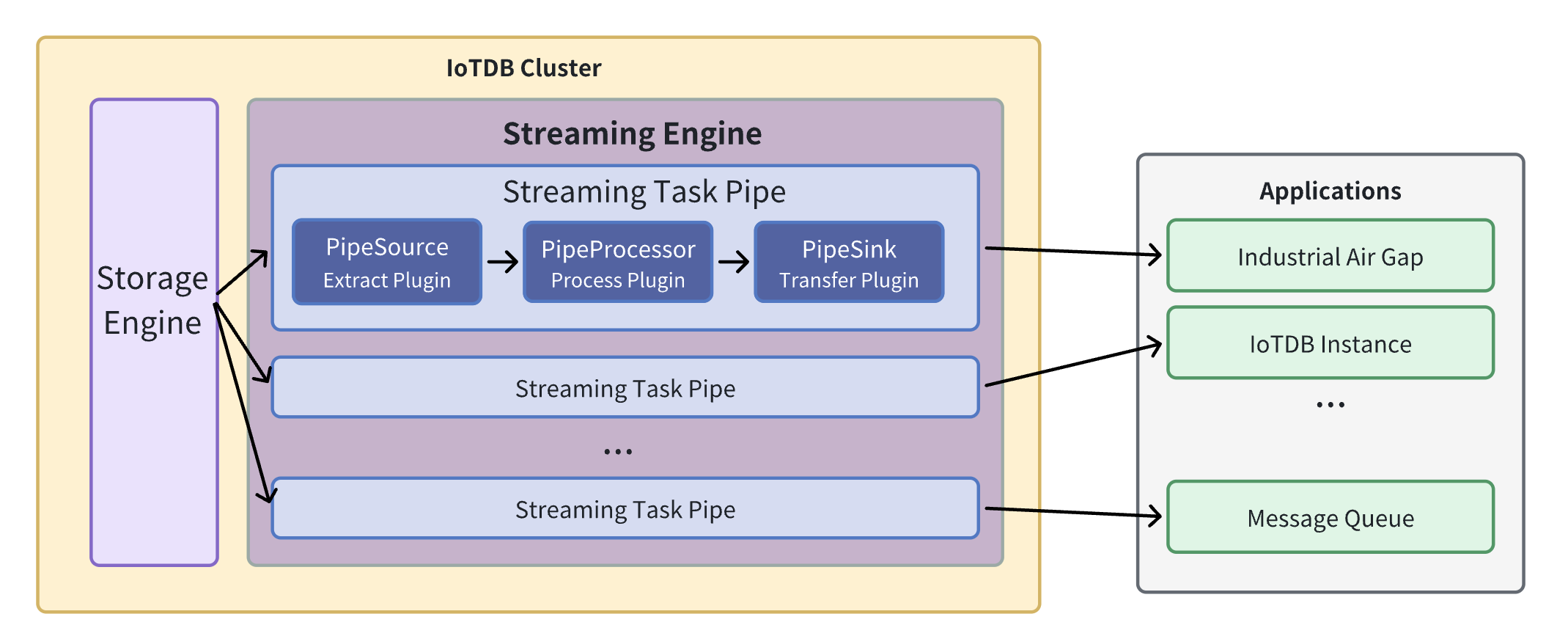
Describing a data flow processing task essentially describes the properties of Pipe Source, Pipe Processor and Pipe Sink plugins.
Users can declaratively configure the specific attributes of the three subtasks through SQL statements, and achieve flexible data ETL capabilities by combining different attributes.
Using the stream processing framework, a complete data link can be built to meet the needs of end-side-cloud synchronization, off-site disaster recovery, and read-write load sub-library*.
1. Custom stream processing plugin development
1.1 Programming development dependencies
It is recommended to use maven to build the project and add the following dependencies in pom.xml. Please be careful to select the same dependency version as the IoTDB server version.
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>pipe-api</artifactId>
<version>1.3.1</version>
<scope>provided</scope>
</dependency>1.2 Event-driven programming model
The user programming interface design of the stream processing plugin refers to the general design concept of the event-driven programming model. Events are data abstractions in the user programming interface, and the programming interface is decoupled from the specific execution method. It only needs to focus on describing the processing method expected by the system after the event (data) reaches the system.
In the user programming interface of the stream processing plugin, events are an abstraction of database data writing operations. The event is captured by the stand-alone stream processing engine, and is passed to the PipeSource plugin, PipeProcessor plugin, and PipeSink plugin in sequence according to the three-stage stream processing process, and triggers the execution of user logic in the three plugins in turn.
In order to take into account the low latency of stream processing in low load scenarios on the end side and the high throughput of stream processing in high load scenarios on the end side, the stream processing engine will dynamically select processing objects in the operation logs and data files. Therefore, user programming of stream processing The interface requires users to provide processing logic for the following two types of events: operation log writing event TabletInsertionEvent and data file writing event TsFileInsertionEvent.
Operation log writing event (TabletInsertionEvent)
The operation log write event (TabletInsertionEvent) is a high-level data abstraction for user write requests. It provides users with the ability to manipulate the underlying data of write requests by providing a unified operation interface.
For different database deployment methods, the underlying storage structures corresponding to operation log writing events are different. For stand-alone deployment scenarios, the operation log writing event is an encapsulation of write-ahead log (WAL) entries; for a distributed deployment scenario, the operation log writing event is an encapsulation of a single node consensus protocol operation log entry.
For write operations generated by different write request interfaces in the database, the data structure of the request structure corresponding to the operation log write event is also different. IoTDB provides numerous writing interfaces such as InsertRecord, InsertRecords, InsertTablet, InsertTablets, etc. Each writing request uses a completely different serialization method, and the generated binary entries are also different.
The existence of operation log writing events provides users with a unified view of data operations, which shields the implementation differences of the underlying data structure, greatly reduces the user's programming threshold, and improves the ease of use of the function.
/** TabletInsertionEvent is used to define the event of data insertion. */
public interface TabletInsertionEvent extends Event {
/**
* The consumer processes the data row by row and collects the results by RowCollector.
*
* @return {@code Iterable<TabletInsertionEvent>} a list of new TabletInsertionEvent contains the
* results collected by the RowCollector
*/
Iterable<TabletInsertionEvent> processRowByRow(BiConsumer<Row, RowCollector> consumer);
/**
* The consumer processes the Tablet directly and collects the results by RowCollector.
*
* @return {@code Iterable<TabletInsertionEvent>} a list of new TabletInsertionEvent contains the
* results collected by the RowCollector
*/
Iterable<TabletInsertionEvent> processTablet(BiConsumer<Tablet, RowCollector> consumer);
}Data file writing event (TsFileInsertionEvent)
The data file writing event (TsFileInsertionEvent) is a high-level abstraction of the database file writing operation. It is a data collection of several operation log writing events (TabletInsertionEvent).
The storage engine of IoTDB is LSM structured. When data is written, the writing operation will first be placed into a log-structured file, and the written data will be stored in the memory at the same time. When the memory reaches the control upper limit, the disk flushing behavior will be triggered, that is, the data in the memory will be converted into a database file, and the previously prewritten operation log will be deleted. When the data in the memory is converted into the data in the database file, it will undergo two compression processes: encoding compression and general compression. Therefore, the data in the database file takes up less space than the original data in the memory.
In extreme network conditions, directly transmitting data files is more economical than transmitting data writing operations. It will occupy lower network bandwidth and achieve faster transmission speeds. Of course, there is no free lunch. Computing and processing data in files requires additional file I/O costs compared to directly computing and processing data in memory. However, it is precisely the existence of two structures, disk data files and memory write operations, with their own advantages and disadvantages, that gives the system the opportunity to make dynamic trade-offs and adjustments. It is based on this observation that data files are introduced into the plugin's event model. Write event.
To sum up, the data file writing event appears in the event stream of the stream processing plugin, and there are two situations:
(1) Historical data extraction: Before a stream processing task starts, all written data that has been placed on the disk will exist in the form of TsFile. After a stream processing task starts, when collecting historical data, the historical data will be abstracted using TsFileInsertionEvent;
(2) Real-time data extraction: When a stream processing task is in progress, when the real-time processing speed of operation log write events in the data stream is slower than the write request speed, after a certain progress, the operation log write events that cannot be processed in the future will be persisted. to disk and exists in the form of TsFile. After this data is extracted by the stream processing engine, TsFileInsertionEvent will be used as an abstraction.
/**
* TsFileInsertionEvent is used to define the event of writing TsFile. Event data stores in disks,
* which is compressed and encoded, and requires IO cost for computational processing.
*/
public interface TsFileInsertionEvent extends Event {
/**
* The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
*
* @return {@code Iterable<TabletInsertionEvent>} the list of TabletInsertionEvent
*/
Iterable<TabletInsertionEvent> toTabletInsertionEvents();
}1.3 Custom stream processing plugin programming interface definition
Based on the custom stream processing plugin programming interface, users can easily write data extraction plugins, data processing plugins and data sending plugins, so that the stream processing function can be flexibly adapted to various industrial scenarios.
Data extraction plugin interface
Data extraction is the first stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data extraction plugin (PipeSource) serves as a bridge between the stream processing engine and the storage engine. It captures various data write events by listening to the behavior of the storage engine.
/**
* PipeSource
*
* <p>PipeSource is responsible for capturing events from sources.
*
* <p>Various data sources can be supported by implementing different PipeSource classes.
*
* <p>The lifecycle of a PipeSource is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH Source` clause in SQL are
* parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
* be called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
* configure the runtime behavior of the PipeSource.
* <li>Then the method {@link PipeSource#start()} will be called to start the PipeSource.
* <li>While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
* called to capture events from sources and then the events will be passed to the
* PipeProcessor.
* <li>The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
* </ul>
*/
public interface PipeSource extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeSource. In this method, the user can do the
* following things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeSourceRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
* is called.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
* Start the Source. After this method is called, events should be ready to be supplied by
* {@link PipeSource#supply()}. This method is called after {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
* Supply single event from the Source and the caller will send the event to the processor.
* This method is called after {@link PipeSource#start()} is called.
*
* @return the event to be supplied. the event may be null if the Source has no more events at
* the moment, but the Source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
}Data processing plugin interface
Data processing is the second stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data processing plugin (PipeProcessor) is primarily used for filtering and transforming the various events captured by the data extraction plugin (PipeSource).
/**
* PipeProcessor
*
* <p>PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
* <p>The lifecycle of a PipeProcessor is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH PROCESSOR` clause in SQL are
* parsed and the validation method {@link PipeProcessor#validate(PipeParameterValidator)}
* will be called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
* to configure the runtime behavior of the PipeProcessor.
* <li>While the collaboration task is in progress:
* <ul>
* <li>PipeSource captures the events and wraps them into three types of Event instances.
* <li>PipeProcessor processes the event and then passes them to the PipeSource. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
* <li>PipeSink serializes the events into binaries and send them to sinks.
* </ul>
* <li>When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
* </ul>
*/
public interface PipeProcessor extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeProcessor. In this method, the user can do the
* following things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeProcessorRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link
* PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
* events processing.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeProcessor
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
throws Exception;
/**
* This method is called to process the TabletInsertionEvent.
*
* @param tabletInsertionEvent TabletInsertionEvent to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
throws Exception;
/**
* This method is called to process the TsFileInsertionEvent.
*
* @param tsFileInsertionEvent TsFileInsertionEvent to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
throws Exception {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
process(tabletInsertionEvent, eventCollector);
}
}
/**
* This method is called to process the Event.
*
* @param event Event to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
void process(Event event, EventCollector eventCollector) throws Exception;
}Data sending plugin interface
Data sending is the third stage of the three-stage process of stream processing, which includes data extraction, data processing, and data sending. The data sending plugin (PipeSink) is responsible for sending the various events processed by the data processing plugin (PipeProcessor). It serves as the network implementation layer of the stream processing framework and should support multiple real-time communication protocols and connectors in its interface.
/**
* PipeSink
*
* <p>PipeSink is responsible for sending events to sinks.
*
* <p>Various network protocols can be supported by implementing different PipeSink classes.
*
* <p>The lifecycle of a PipeSink is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
* parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
* called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
* PipeSinkRuntimeConfiguration)} will be called to configure the runtime behavior of the
* PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
* with sink.
* <li>While the collaboration task is in progress:
* <ul>
* <li>PipeSource captures the events and wraps them into three types of Event instances.
* <li>PipeProcessor processes the event and then passes them to the PipeSink.
* <li>PipeSink serializes the events into binaries and send them to sinks. The following 3
* methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
* PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
* </ul>
* <li>When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeSink#close() } method will be called.
* </ul>
*
* <p>In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
* whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
* called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
* throws exceptions.
*/
public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeSink. In this method, the user can do the following
* things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeSinkRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
* called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
* method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
* will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
void handshake() throws Exception;
/**
* This method will be called periodically to check whether the connection with sink is still
* alive.
*
* @throws Exception if the connection dies
*/
void heartbeat() throws Exception;
/**
* This method is used to transfer the TabletInsertionEvent.
*
* @param tabletInsertionEvent TabletInsertionEvent to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
/**
* This method is used to transfer the TsFileInsertionEvent.
*
* @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
try {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
transfer(tabletInsertionEvent);
}
} finally {
tsFileInsertionEvent.close();
}
}
/**
* This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
void transfer(Event event) throws Exception;
}2. Custom stream processing plugin management
In order to ensure the flexibility and ease of use of user-defined plugins in actual production, the system also needs to provide the ability to dynamically and uniformly manage plugins.
The stream processing plugin management statements introduced in this chapter provide an entry point for dynamic unified management of plugins.
2.1 Load plugin statement
In IoTDB, if you want to dynamically load a user-defined plugin in the system, you first need to implement a specific plugin class based on PipeSource, PipeProcessor or PipeSink.
Then the plugin class needs to be compiled and packaged into a jar executable file, and finally the plugin is loaded into IoTDB using the management statement for loading the plugin.
The syntax of the management statement for loading the plugin is shown in the figure.
CREATE PIPEPLUGIN [IF NOT EXISTS] <alias>
AS <full class name>
USING <URI of JAR package>IF NOT EXISTS semantics: Used in creation operations to ensure that the create command is executed when the specified Pipe Plugin does not exist, preventing errors caused by attempting to create an existing Pipe Plugin.
Example: If you implement a data processing plugin named edu.tsinghua.iotdb.pipe.ExampleProcessor, and the packaged jar package is pipe-plugin.jar, you want to use this plugin in the stream processing engine, and mark the plugin as example. There are two ways to use the plugin package, one is to upload to the URI server, and the other is to upload to the local directory of the cluster.
Method 1: Upload to the URI server
Preparation: To register in this way, you need to upload the JAR package to the URI server in advance and ensure that the IoTDB instance that executes the registration statement can access the URI server. For example https://example.com:8080/iotdb/pipe-plugin.jar .
SQL:
CREATE PIPEPLUGIN IF NOT EXISTS example
AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
USING URI <https://example.com:8080/iotdb/pipe-plugin.jar>Method 2: Upload the data to the local directory of the cluster
Preparation: To register in this way, you need to place the JAR package in any path on the machine where the DataNode node is located, and we recommend that you place the JAR package in the /ext/pipe directory of the IoTDB installation path (the installation package is already in the installation package, so you do not need to create a new one). For example: iotdb-1.x.x-bin/ext/pipe/pipe-plugin.jar. (Note: If you are using a cluster, you will need to place the JAR package under the same path as the machine where each DataNode node is located)
SQL:
CREATE PIPEPLUGIN IF NOT EXISTS example
AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
USING URI <file:/IoTDB installation path/iotdb-1.x.x-bin/ext/pipe/pipe-plugin.jar>2.2 Delete plugin statement
When the user no longer wants to use a plugin and needs to uninstall the plugin from the system, he can use the delete plugin statement as shown in the figure.
DROP PIPEPLUGIN [IF EXISTS] <alias>IF EXISTS semantics: Used in deletion operations to ensure that when a specified Pipe Plugin exists, the delete command is executed to prevent errors caused by attempting to delete a non-existent Pipe Plugin.
2.3 View plugin statements
Users can also view plugins in the system on demand. View the statement of the plugin as shown in the figure.
SHOW PIPEPLUGINS3. System preset stream processing plugin
3.1 Pre-built Source Plugin
iotdb-source
Function: Extract historical or realtime data inside IoTDB into pipe.
| key | value | value range | required or optional with default |
|---|---|---|---|
| source | iotdb-source | String: iotdb-source | required |
| source.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
| source.history.start-time | start of synchronizing historical data event time,including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
| source.history.end-time | end of synchronizing historical data event time,including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
| source.realtime.mode | Extraction mode for real-time data | String: hybrid, stream, batch | optional:hybrid |
| source.forwarding-pipe-requests | Whether to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional:true |
🚫 source.pattern Parameter Description
Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.`a@b` or root.`123`, you should set the pattern to root.`a@b` or root.`123`(Refer specifically to Timing of single and double quotes and backquotes)
In the underlying implementation, when pattern is detected as root (default value) or a database name, synchronization efficiency is higher, and any other format will reduce performance.
The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'source.pattern'='root.aligned.1':
- root.aligned.1TS
- root.aligned.1TS.`1`
- root.aligned.100TS
the data will be synchronized;
- root.aligned.`1`
- root.aligned.`123`
the data will not be synchronized.
❗️start-time, end-time parameter description of source
- start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00. However, version 1.3.1+ supports timeStamp format like 1706704494000.
✅ A piece of data from production to IoTDB contains two key concepts of time
- event time: The time when the data is actually produced (or the generation time assigned to the data by the data production system, which is the time item in the data point), also called event time.
- arrival time: The time when data arrives in the IoTDB system.
The out-of-order data we often refer to refers to data whose event time is far behind the current system time (or the maximum event time that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their arrival time will increase with the order in which the data arrives at IoTDB.
💎 The work of iotdb-source can be split into two stages
- Historical data extraction: All data with arrival time < current system time when creating the pipe is called historical data
- Realtime data extraction: All data with arrival time >= current system time when the pipe is created is called realtime data
The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
📌 source.realtime.mode: Data extraction mode
- log: In this mode, the task only uses the operation log for data processing and sending
- file: In this mode, the task only uses data files for data processing and sending.
- hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data one by one in the operation log, and the characteristics of high throughput but high latency when sending in batches of data files. It can automatically operate under different write loads. Switch the appropriate data extraction method. First, adopt the data extraction method based on operation logs to ensure low sending delay. When a data backlog occurs, it will automatically switch to the data extraction method based on data files to ensure high sending throughput. When the backlog is eliminated, it will automatically switch back to the data extraction method based on data files. The data extraction method of the operation log avoids the problem of difficulty in balancing data sending delay or throughput using a single data extraction algorithm.
🍕 source.forwarding-pipe-requests: Whether to allow forwarding data transmitted from another pipe
- If you want to use pipe to build data synchronization of A -> B -> C, then the pipe of B -> C needs to set this parameter to true, so that the data written by A to B through the pipe in A -> B can be forwarded correctly. to C
- If you want to use pipe to build two-way data synchronization (dual-active) of A <-> B, then the pipes of A -> B and B -> A need to set this parameter to false, otherwise the data will be endless. inter-cluster round-robin forwarding
3.2 Preset processor plugin
do-nothing-processor
Function: No processing is done on the events passed in by the source.
| key | value | value range | required or optional with default |
|---|---|---|---|
| processor | do-nothing-processor | String: do-nothing-processor | required |
3.3 Preset sink plugin
do-nothing-sink
Function: No processing is done on the events passed in by the processor.
| key | value | value range | required or optional with default |
|---|---|---|---|
| sink | do-nothing-sink | String: do-nothing-sink | required |
4. Stream processing task management
4.1 Create a stream processing task
Use the CREATE PIPE statement to create a stream processing task. Taking the creation of a data synchronization stream processing task as an example, the sample SQL statement is as follows:
CREATE PIPE <PipeId> -- PipeId is the name that uniquely identifies the sync task
WITH SOURCE (
-- Default IoTDB Data Extraction Plugin
'source' = 'iotdb-source',
-- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
'source.pattern' = 'root.timecho',
-- Whether to extract historical data
'source.history.enable' = 'true',
-- Describes the time range of the historical data being extracted, indicating the earliest possible time
'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- Describes the time range of the extracted historical data, indicating the latest time
'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- Whether to extract realtime data
'source.realtime.enable' = 'true',
)
WITH PROCESSOR (
-- Default data processing plugin, means no processing
'processor' = 'do-nothing-processor',
)
WITH SINK (
-- IoTDB data sending plugin with target IoTDB
'sink' = 'iotdb-thrift-sink',
-- Data service for one of the DataNode nodes on the target IoTDB ip
'sink.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
'sink.port' = '6667',
)When creating a stream processing task, you need to configure the PipeId and the parameters of the three plugin parts:
| Configuration | Description | Required or not | Default implementation | Default implementation description | Default implementation description |
|---|---|---|---|---|---|
| PipeId | A globally unique name that identifies a stream processing | - | - | - | |
| source | Pipe Source plugin, responsible for extracting stream processing data at the bottom of the database | Optional | iotdb-source | Integrate the full historical data of the database and subsequent real-time data arriving into the stream processing task | No |
| processor | Pipe Processor plugin, responsible for processing data | Optional | do-nothing-processor | Does not do any processing on the incoming data | |
| sink | Pipe Sink plugin, responsible for sending data | - | - |
In the example, the iotdb-source, do-nothing-processor and iotdb-thrift-sink plugins are used to build the data flow processing task. IoTDB also has other built-in stream processing plugins, please check the "System Preset Stream Processing plugin" section.
A simplest example of the CREATE PIPE statement is as follows:
CREATE PIPE <PipeId> -- PipeId is a name that uniquely identifies the stream processing task
WITH SINK (
-- IoTDB data sending plugin, the target is IoTDB
'sink' = 'iotdb-thrift-sink',
--The data service IP of one of the DataNode nodes in the target IoTDB
'sink.ip' = '127.0.0.1',
-- The data service port of one of the DataNode nodes in the target IoTDB
'sink.port' = '6667',
)The semantics expressed are: synchronize all historical data in this database instance and subsequent real-time data arriving to the IoTDB instance with the target 127.0.0.1:6667.
Notice:
SOURCE and PROCESSOR are optional configurations. If you do not fill in the configuration parameters, the system will use the corresponding default implementation.
SINK is a required configuration and needs to be configured declaratively in the CREATE PIPE statement
SINK has self-reuse capability. For different stream processing tasks, if their SINKs have the same KV attributes (the keys corresponding to the values of all attributes are the same), then the system will only create one SINK instance in the end to realize the duplication of connection resources.
- For example, there are the following declarations of two stream processing tasks, pipe1 and pipe2:
CREATE PIPE pipe1 WITH SINK ( 'sink' = 'iotdb-thrift-sink', 'sink.ip' = 'localhost', 'sink.port' = '9999', ) CREATE PIPE pipe2 WITH SINK ( 'sink' = 'iotdb-thrift-sink', 'sink.port' = '9999', 'sink.ip' = 'localhost', )Because their declarations of SINK are exactly the same (even if the order of declaration of some attributes is different), the framework will automatically reuse the SINKs they declared, and ultimately the SINKs of pipe1 and pipe2 will be the same instance. .
When the source is the default iotdb-source, and source.forwarding-pipe-requests is the default value true, please do not build an application scenario that includes data cycle synchronization (it will cause an infinite loop):
- IoTDB A -> IoTDB B -> IoTDB A
- IoTDB A -> IoTDB A
4.2 Start the stream processing task
After the CREATE PIPE statement is successfully executed, the stream processing task-related instance will be created, but the running status of the entire stream processing task will be set to STOPPED(V1.3.0), that is, the stream processing task will not process data immediately. In version 1.3.1 and later, the status of the task will be set to RUNNING after CREATE.
You can use the START PIPE statement to cause a stream processing task to start processing data:
START PIPE <PipeId>4.3 Stop the stream processing task
Use the STOP PIPE statement to stop the stream processing task from processing data:
STOP PIPE <PipeId>4.4 Delete stream processing tasks
Use the DROP PIPE statement to stop the stream processing task from processing data (when the stream processing task status is RUNNING), and then delete the entire stream processing task:
DROP PIPE <PipeId>Users do not need to perform a STOP operation before deleting the stream processing task.
4.5 Display stream processing tasks
Use the SHOW PIPES statement to view all stream processing tasks:
SHOW PIPESThe query results are as follows:
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
| ID| CreationTime| State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+You can use <PipeId> to specify the status of a stream processing task you want to see:
SHOW PIPE <PipeId>You can also use the where clause to determine whether the Pipe Sink used by a certain <PipeId> is reused.
SHOW PIPES
WHERE SINK USED BY <PipeId>4.6 Stream processing task running status migration
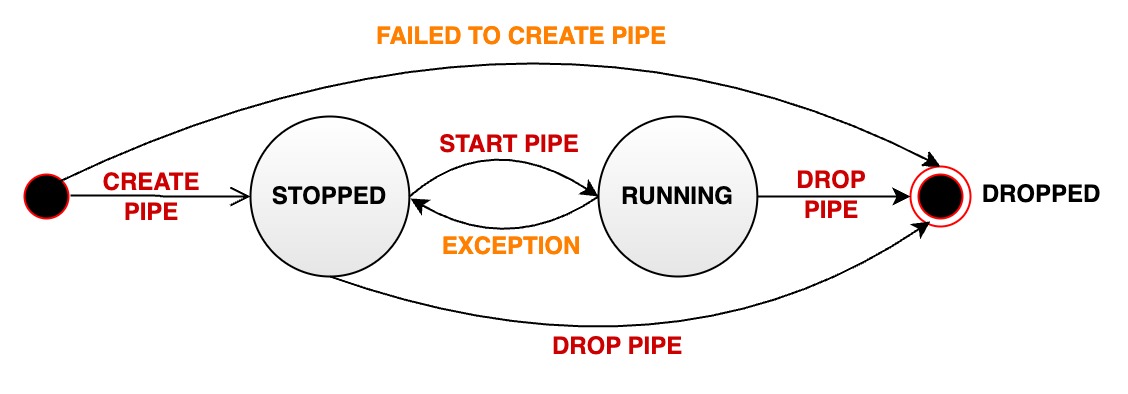
A stream processing pipe will pass through various states during its managed life cycle:
- RUNNING: pipe is working properly
- When a pipe is successfully created, its initial state is RUNNING.(V1.3.1+)
- STOPPED: The pipe is stopped. When the pipeline is in this state, there are several possibilities:
- When a pipe is successfully created, its initial state is STOPPED.(V1.3.0)
- The user manually pauses a pipe that is in normal running status, and its status will passively change from RUNNING to STOPPED.
- When an unrecoverable error occurs during the running of a pipe, its status will automatically change from RUNNING to STOPPED
- DROPPED: The pipe task was permanently deleted
The following diagram shows all states and state transitions:
5. authority management
5.1 Stream processing tasks
| Permission name | Description |
|---|---|
| USE_PIPE | Register a stream processing task. The path is irrelevant. |
| USE_PIPE | Start the stream processing task. The path is irrelevant. |
| USE_PIPE | Stop the stream processing task. The path is irrelevant. |
| USE_PIPE | Offload stream processing tasks. The path is irrelevant. |
| USE_PIPE | Query stream processing tasks. The path is irrelevant. |
5.2 Stream processing task plugin
| Permission name | Description |
|---|---|
| USE_PIPE | Register stream processing task plugin. The path is irrelevant. |
| USE_PIPE | Uninstall the stream processing task plugin. The path is irrelevant. |
| USE_PIPE | Query stream processing task plugin. The path is irrelevant. |
6. Configuration parameters
In iotdb-system.properties:
V1.3.0+:
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
# pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
# The maximum number of selectors that can be used in the async connector.
# pipe_async_connector_selector_number=1
# The core number of clients that can be used in the async connector.
# pipe_async_connector_core_client_number=8
# The maximum number of clients that can be used in the async connector.
# pipe_async_connector_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# pipe_air_gap_receiver_port=9780V1.3.1+:
# Uncomment the following field to configure the pipe lib directory.
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
# pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# pipe_sink_timeout_ms=900000
# The maximum number of selectors that can be used in the sink.
# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
# pipe_sink_selector_number=4
# The maximum number of clients that can be used in the sink.
# pipe_sink_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# pipe_air_gap_receiver_port=9780