
流计算框架
流计算框架
IoTDB 流处理框架允许用户实现自定义的流处理逻辑,可以实现对存储引擎变更的监听和捕获、实现对变更数据的变形、实现对变形后数据的向外推送等逻辑。
我们将。一个流处理任务(Pipe)包含三个子任务:
- 抽取(Source)
- 处理(Process)
- 发送(Sink)
流处理框架允许用户使用 Java 语言自定义编写三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。
在一个 Pipe 中,上述的三个子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:
Pipe Source 用于抽取数据,Pipe Processor 用于处理数据,Pipe Sink 用于发送数据,最终数据将被发至外部系统。
Pipe 任务的模型如下:
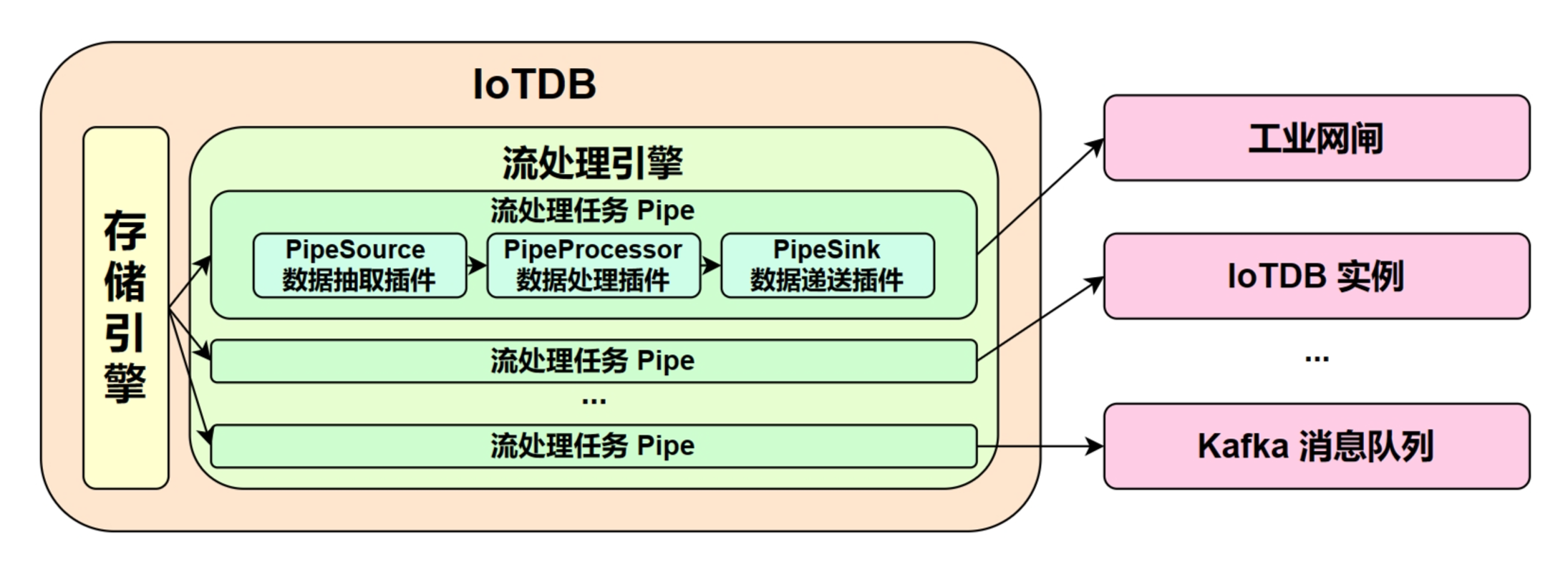
描述一个数据流处理任务,本质就是描述 Pipe Source、Pipe Processor 和 Pipe Sink 插件的属性。
用户可以通过 SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
利用流处理框架,可以搭建完整的数据链路来满足端边云同步、异地灾备、读写负载分库等需求。
1. 自定义流处理插件开发
1.1 编程开发依赖
推荐采用 maven 构建项目,在pom.xml中添加以下依赖。请注意选择和 IoTDB 服务器版本相同的依赖版本。
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>pipe-api</artifactId>
<version>1.3.1</version>
<scope>provided</scope>
</dependency>1.2 事件驱动编程模型
流处理插件的用户编程接口设计,参考了事件驱动编程模型的通用设计理念。事件(Event)是用户编程接口中的数据抽象,而编程接口与具体的执行方式解耦,只需要专注于描述事件(数据)到达系统后,系统期望的处理方式即可。
在流处理插件的用户编程接口中,事件是数据库数据写入操作的抽象。事件由单机流处理引擎捕获,按照流处理三个阶段的流程,依次传递至 PipeSource 插件,PipeProcessor 插件和 PipeSink 插件,并依次在三个插件中触发用户逻辑的执行。
为了兼顾端侧低负载场景下的流处理低延迟和端侧高负载场景下的流处理高吞吐,流处理引擎会动态地在操作日志和数据文件中选择处理对象,因此,流处理的用户编程接口要求用户提供下列两类事件的处理逻辑:操作日志写入事件 TabletInsertionEvent 和数据文件写入事件 TsFileInsertionEvent。
操作日志写入事件(TabletInsertionEvent)
操作日志写入事件(TabletInsertionEvent)是对用户写入请求的高层数据抽象,它通过提供统一的操作接口,为用户提供了操纵写入请求底层数据的能力。
对于不同的数据库部署方式,操作日志写入事件对应的底层存储结构是不一样的。对于单机部署的场景,操作日志写入事件是对写前日志(WAL)条目的封装;对于分布式部署的场景,操作日志写入事件是对单个节点共识协议操作日志条目的封装。
对于数据库不同写入请求接口生成的写入操作,操作日志写入事件对应的请求结构体的数据结构也是不一样的。IoTDB 提供了 InsertRecord、InsertRecords、InsertTablet、InsertTablets 等众多的写入接口,每一种写入请求都使用了完全不同的序列化方式,生成的二进制条目也不尽相同。
操作日志写入事件的存在,为用户提供了一种统一的数据操作视图,它屏蔽了底层数据结构的实现差异,极大地降低了用户的编程门槛,提升了功能的易用性。
/** TabletInsertionEvent is used to define the event of data insertion. */
public interface TabletInsertionEvent extends Event {
/**
* The consumer processes the data row by row and collects the results by RowCollector.
*
* @return {@code Iterable<TabletInsertionEvent>} a list of new TabletInsertionEvent contains the
* results collected by the RowCollector
*/
Iterable<TabletInsertionEvent> processRowByRow(BiConsumer<Row, RowCollector> consumer);
/**
* The consumer processes the Tablet directly and collects the results by RowCollector.
*
* @return {@code Iterable<TabletInsertionEvent>} a list of new TabletInsertionEvent contains the
* results collected by the RowCollector
*/
Iterable<TabletInsertionEvent> processTablet(BiConsumer<Tablet, RowCollector> consumer);
}数据文件写入事件(TsFileInsertionEvent)
数据文件写入事件(TsFileInsertionEvent) 是对数据库文件落盘操作的高层抽象,它是若干操作日志写入事件(TabletInsertionEvent)的数据集合。
IoTDB 的存储引擎是 LSM 结构的。数据写入时会先将写入操作落盘到日志结构的文件里,同时将写入数据保存在内存里。当内存达到控制上限,则会触发刷盘行为,即将内存中的数据转换为数据库文件,同时删除之前预写的操作日志。当内存中的数据转换为数据库文件中的数据时,会经过编码压缩和通用压缩两次压缩处理,因此数据库文件的数据相比内存中的原始数据占用的空间更少。
在极端的网络情况下,直接传输数据文件相比传输数据写入的操作要更加经济,它会占用更低的网络带宽,能实现更快的传输速度。当然,天下没有免费的午餐,对文件中的数据进行计算处理,相比直接对内存中的数据进行计算处理时,需要额外付出文件 I/O 的代价。但是,正是磁盘数据文件和内存写入操作两种结构各有优劣的存在,给了系统做动态权衡调整的机会,也正是基于这样的观察,插件的事件模型中才引入了数据文件写入事件。
综上,数据文件写入事件出现在流处理插件的事件流中,存在下面两种情况:
(1)历史数据抽取:一个流处理任务开始前,所有已经落盘的写入数据都会以 TsFile 的形式存在。一个流处理任务开始后,采集历史数据时,历史数据将以 TsFileInsertionEvent 作为抽象;
(2)实时数据抽取:一个流处理任务进行时,当数据流中实时处理操作日志写入事件的速度慢于写入请求速度一定进度之后,未来得及处理的操作日志写入事件会被被持久化至磁盘,以 TsFile 的形式存在,这一些数据被流处理引擎抽取到后,会以 TsFileInsertionEvent 作为抽象。
/**
* TsFileInsertionEvent is used to define the event of writing TsFile. Event data stores in disks,
* which is compressed and encoded, and requires IO cost for computational processing.
*/
public interface TsFileInsertionEvent extends Event {
/**
* The method is used to convert the TsFileInsertionEvent into several TabletInsertionEvents.
*
* @return {@code Iterable<TabletInsertionEvent>} the list of TabletInsertionEvent
*/
Iterable<TabletInsertionEvent> toTabletInsertionEvents();
}1.3 自定义流处理插件编程接口定义
基于自定义流处理插件编程接口,用户可以轻松编写数据抽取插件、数据处理插件和数据发送插件,从而使得流处理功能灵活适配各种工业场景。
数据抽取插件接口
数据抽取是流处理数据从数据抽取到数据发送三阶段的第一阶段。数据抽取插件(PipeSource)是流处理引擎和存储引擎的桥梁,它通过监听存储引擎的行为,捕获各种数据写入事件。
/**
* PipeSource
*
* <p>PipeSource is responsible for capturing events from sources.
*
* <p>Various data sources can be supported by implementing different PipeSource classes.
*
* <p>The lifecycle of a PipeSource is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH SOURCE` clause in SQL are
* parsed and the validation method {@link PipeSource#validate(PipeParameterValidator)} will
* be called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} will be called to
* config the runtime behavior of the PipeSource.
* <li>Then the method {@link PipeSource#start()} will be called to start the PipeSource.
* <li>While the collaboration task is in progress, the method {@link PipeSource#supply()} will be
* called to capture events from sources and then the events will be passed to the
* PipeProcessor.
* <li>The method {@link PipeSource#close()} will be called when the collaboration task is
* cancelled (the `DROP PIPE` command is executed).
* </ul>
*/
public interface PipeSource extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeSource. In this method, the user can do the
* following things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeSourceRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link PipeSource#validate(PipeParameterValidator)}
* is called.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeSource
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeSourceRuntimeConfiguration configuration)
throws Exception;
/**
* Start the Source. After this method is called, events should be ready to be supplied by
* {@link PipeSource#supply()}. This method is called after {@link
* PipeSource#customize(PipeParameters, PipeSourceRuntimeConfiguration)} is called.
*
* @throws Exception the user can throw errors if necessary
*/
void start() throws Exception;
/**
* Supply single event from the Source and the caller will send the event to the processor.
* This method is called after {@link PipeSource#start()} is called.
*
* @return the event to be supplied. the event may be null if the Source has no more events at
* the moment, but the Source is still running for more events.
* @throws Exception the user can throw errors if necessary
*/
Event supply() throws Exception;
}数据处理插件接口
数据处理是流处理数据从数据抽取到数据发送三阶段的第二阶段。数据处理插件(PipeProcessor)主要用于过滤和转换由数据抽取插件(PipeSource)捕获的各种事件。
/**
* PipeProcessor
*
* <p>PipeProcessor is used to filter and transform the Event formed by the PipeSource.
*
* <p>The lifecycle of a PipeProcessor is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH PROCESSOR` clause in SQL are
* parsed and the validation method {@link PipeProcessor#validate(PipeParameterValidator)}
* will be called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} will be called
* to config the runtime behavior of the PipeProcessor.
* <li>While the collaboration task is in progress:
* <ul>
* <li>PipeSource captures the events and wraps them into three types of Event instances.
* <li>PipeProcessor processes the event and then passes them to the PipeSink. The
* following 3 methods will be called: {@link
* PipeProcessor#process(TabletInsertionEvent, EventCollector)}, {@link
* PipeProcessor#process(TsFileInsertionEvent, EventCollector)} and {@link
* PipeProcessor#process(Event, EventCollector)}.
* <li>PipeSink serializes the events into binaries and send them to sinks.
* </ul>
* <li>When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeProcessor#close() } method will be called.
* </ul>
*/
public interface PipeProcessor extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeProcessor#customize(PipeParameters, PipeProcessorRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeProcessor. In this method, the user can do the
* following things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeProcessorRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link
* PipeProcessor#validate(PipeParameterValidator)} is called and before the beginning of the
* events processing.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeProcessor
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeProcessorRuntimeConfiguration configuration)
throws Exception;
/**
* This method is called to process the TabletInsertionEvent.
*
* @param tabletInsertionEvent TabletInsertionEvent to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
void process(TabletInsertionEvent tabletInsertionEvent, EventCollector eventCollector)
throws Exception;
/**
* This method is called to process the TsFileInsertionEvent.
*
* @param tsFileInsertionEvent TsFileInsertionEvent to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
default void process(TsFileInsertionEvent tsFileInsertionEvent, EventCollector eventCollector)
throws Exception {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
process(tabletInsertionEvent, eventCollector);
}
}
/**
* This method is called to process the Event.
*
* @param event Event to be processed
* @param eventCollector used to collect result events after processing
* @throws Exception the user can throw errors if necessary
*/
void process(Event event, EventCollector eventCollector) throws Exception;
}数据发送插件接口
数据发送是流处理数据从数据抽取到数据发送三阶段的第三阶段。数据发送插件(PipeSink)主要用于发送经由数据处理插件(PipeProcessor)处理过后的各种事件,它作为流处理框架的网络实现层,接口上应允许接入多种实时通信协议和多种连接器。
/**
* PipeSink
*
* <p>PipeSink is responsible for sending events to sinks.
*
* <p>Various network protocols can be supported by implementing different PipeSink classes.
*
* <p>The lifecycle of a PipeSink is as follows:
*
* <ul>
* <li>When a collaboration task is created, the KV pairs of `WITH SINK` clause in SQL are
* parsed and the validation method {@link PipeSink#validate(PipeParameterValidator)} will be
* called to validate the parameters.
* <li>Before the collaboration task starts, the method {@link PipeSink#customize(PipeParameters,
* PipeSinkRuntimeConfiguration)} will be called to config the runtime behavior of the
* PipeSink and the method {@link PipeSink#handshake()} will be called to create a connection
* with sink.
* <li>While the collaboration task is in progress:
* <ul>
* <li>PipeSource captures the events and wraps them into three types of Event instances.
* <li>PipeProcessor processes the event and then passes them to the PipeSink.
* <li>PipeSink serializes the events into binaries and send them to sinks. The following 3
* methods will be called: {@link PipeSink#transfer(TabletInsertionEvent)}, {@link
* PipeSink#transfer(TsFileInsertionEvent)} and {@link PipeSink#transfer(Event)}.
* </ul>
* <li>When the collaboration task is cancelled (the `DROP PIPE` command is executed), the {@link
* PipeSink#close() } method will be called.
* </ul>
*
* <p>In addition, the method {@link PipeSink#heartbeat()} will be called periodically to check
* whether the connection with sink is still alive. The method {@link PipeSink#handshake()} will be
* called to create a new connection with the sink when the method {@link PipeSink#heartbeat()}
* throws exceptions.
*/
public interface PipeSink extends PipePlugin {
/**
* This method is mainly used to validate {@link PipeParameters} and it is executed before {@link
* PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called.
*
* @param validator the validator used to validate {@link PipeParameters}
* @throws Exception if any parameter is not valid
*/
void validate(PipeParameterValidator validator) throws Exception;
/**
* This method is mainly used to customize PipeSink. In this method, the user can do the following
* things:
*
* <ul>
* <li>Use PipeParameters to parse key-value pair attributes entered by the user.
* <li>Set the running configurations in PipeSinkRuntimeConfiguration.
* </ul>
*
* <p>This method is called after the method {@link PipeSink#validate(PipeParameterValidator)} is
* called and before the method {@link PipeSink#handshake()} is called.
*
* @param parameters used to parse the input parameters entered by the user
* @param configuration used to set the required properties of the running PipeSink
* @throws Exception the user can throw errors if necessary
*/
void customize(PipeParameters parameters, PipeSinkRuntimeConfiguration configuration)
throws Exception;
/**
* This method is used to create a connection with sink. This method will be called after the
* method {@link PipeSink#customize(PipeParameters, PipeSinkRuntimeConfiguration)} is called or
* will be called when the method {@link PipeSink#heartbeat()} throws exceptions.
*
* @throws Exception if the connection is failed to be created
*/
void handshake() throws Exception;
/**
* This method will be called periodically to check whether the connection with sink is still
* alive.
*
* @throws Exception if the connection dies
*/
void heartbeat() throws Exception;
/**
* This method is used to transfer the TabletInsertionEvent.
*
* @param tabletInsertionEvent TabletInsertionEvent to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
void transfer(TabletInsertionEvent tabletInsertionEvent) throws Exception;
/**
* This method is used to transfer the TsFileInsertionEvent.
*
* @param tsFileInsertionEvent TsFileInsertionEvent to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
default void transfer(TsFileInsertionEvent tsFileInsertionEvent) throws Exception {
try {
for (final TabletInsertionEvent tabletInsertionEvent :
tsFileInsertionEvent.toTabletInsertionEvents()) {
transfer(tabletInsertionEvent);
}
} finally {
tsFileInsertionEvent.close();
}
}
/**
* This method is used to transfer the generic events, including HeartbeatEvent.
*
* @param event Event to be transferred
* @throws PipeConnectionException if the connection is broken
* @throws Exception the user can throw errors if necessary
*/
void transfer(Event event) throws Exception;
}2. 自定义流处理插件管理
为了保证用户自定义插件在实际生产中的灵活性和易用性,系统还需要提供对插件进行动态统一管理的能力。
本章节介绍的流处理插件管理语句提供了对插件进行动态统一管理的入口。
2.1 加载插件语句
在 IoTDB 中,若要在系统中动态载入一个用户自定义插件,则首先需要基于 PipeSource、 PipeProcessor 或者 PipeSink 实现一个具体的插件类,然后需要将插件类编译打包成 jar 可执行文件,最后使用加载插件的管理语句将插件载入 IoTDB。
加载插件的管理语句的语法如图所示。
CREATE PIPEPLUGIN [IF NOT EXISTS] <别名>
AS <全类名>
USING <JAR 包的 URI>IF NOT EXISTS 语义:用于创建操作中,确保当指定 Pipe Plugin 不存在时,执行创建命令,防止因尝试创建已存在的 Pipe Plugin 而导致报错。
示例:假如用户实现了一个全类名为edu.tsinghua.iotdb.pipe.ExampleProcessor 的数据处理插件,打包后的jar包为 pipe-plugin.jar ,用户希望在流处理引擎中使用这个插件,将插件标记为 example。插件包有两种使用方式,一种为上传到URI服务器,一种为上传到集群本地目录,两种方法任选一种即可。
【方式一】上传到URI服务器
准备工作:使用该种方式注册,您需要提前将 JAR 包上传到 URI 服务器上并确保执行注册语句的IoTDB实例能够访问该 URI 服务器。例如 https://example.com:8080/iotdb/pipe-plugin.jar 。
创建语句:
CREATE PIPEPLUGIN IF NOT EXISTS example
AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
USING URI <https://example.com:8080/iotdb/pipe-plugin.jar>【方式二】上传到集群本地目录
准备工作:使用该种方式注册,您需要提前将 JAR 包放置到DataNode节点所在机器的任意路径下,推荐您将JAR包放在IoTDB安装路径的/ext/pipe目录下(安装包中已有,无需新建)。例如:iotdb-1.x.x-bin/ext/pipe/pipe-plugin.jar。(注意:如果您使用的是集群,那么需要将 JAR 包放置到每个 DataNode 节点所在机器的该路径下)
创建语句:
CREATE PIPEPLUGIN IF NOT EXISTS example
AS 'edu.tsinghua.iotdb.pipe.ExampleProcessor'
USING URI <file:/iotdb安装路径/iotdb-1.x.x-bin/ext/pipe/pipe-plugin.jar>2.2 删除插件语句
当用户不再想使用一个插件,需要将插件从系统中卸载时,可以使用如图所示的删除插件语句。
DROP PIPEPLUGIN [IF EXISTS] <别名>IF EXISTS 语义:用于删除操作中,确保当指定 Pipe Plugin 存在时,执行删除命令,防止因尝试删除不存在的 Pipe Plugin 而导致报错。
2.3 查看插件语句
用户也可以按需查看系统中的插件。查看插件的语句如图所示。
SHOW PIPEPLUGINS3. 系统预置的流处理插件
3.1 预置 source 插件
iotdb-source
作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
| key | value | value 取值范围 | required or optional with default |
|---|---|---|---|
| source | iotdb-source | String: iotdb-source | required |
| source.pattern | 用于筛选时间序列的路径前缀 | String: 任意的时间序列前缀 | optional: root |
| source.history.start-time | 抽取的历史数据的开始 event time,包含 start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
| source.history.end-time | 抽取的历史数据的结束 event time,包含 end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
| start-time(V1.3.1+) | start of synchronizing all data event time,including start-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
| end-time(V1.3.1+) | end of synchronizing all data event time,including end-time. Will disable "history.start-time" "history.end-time" if configured | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
| source.realtime.mode | 实时数据的抽取模式 | String: hybrid, log, file | optional: hybrid |
| source.forwarding-pipe-requests | 是否抽取由其他 Pipe (通常是数据同步)写入的数据 | Boolean: true, false | optional: true |
🚫 source.pattern 参数说明
Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.`a@b` 或者 root.`123`,应设置 pattern 为 root.`a@b` 或者 root.`123`(具体参考 单双引号和反引号的使用时机)
在底层实现中,当检测到 pattern 为 root(默认值)时,抽取效率较高,其他任意格式都将降低性能
路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'source.pattern'='root.aligned.1' 的 pipe 时:
- root.aligned.1TS
- root.aligned.1TS.`1`
- root.aligned.100T
的数据会被抽取;
- root.aligned.`1`
- root.aligned.`123`
的数据不会被抽取。
❗️source.history 的 start-time,end-time 参数说明
- start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或 2011-12-03T10:15:30+01:00
✅ 一条数据从生产到落库 IoTDB,包含两个关键的时间概念
- event time: 数据实际生产时的时间(或者数据生产系统给数据赋予的生成时间,是数据点中的时间项),也称为事件时间。
- arrival time: 数据到达 IoTDB 系统内的时间。
我们常说的乱序数据,指的是数据到达时,其 event time 远落后于当前系统时间(或者已经落库的最大 event time)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 arrival time 都是会随着数据到达 IoTDB 的顺序递增的。
💎 iotdb-source 的工作可以拆分成两个阶段
- 历史数据抽取:所有 arrival time < 创建 pipe 时当前系统时间的数据称为历史数据
- 实时数据抽取:所有 arrival time >= 创建 pipe 时当前系统时间的数据称为实时数据
历史数据传输阶段和实时数据传输阶段,两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。
📌 source.realtime.mode:数据抽取的模式
- log:该模式下,任务仅使用操作日志进行数据处理、发送
- file:该模式下,任务仅使用数据文件进行数据处理、发送
- hybrid:该模式,考虑了按操作日志逐条目发送数据时延迟低但吞吐低的特点,以及按数据文件批量发送时发送吞吐高但延迟高的特点,能够在不同的写入负载下自动切换适合的数据抽取方式,首先采取基于操作日志的数据抽取方式以保证低发送延迟,当产生数据积压时自动切换成基于数据文件的数据抽取方式以保证高发送吞吐,积压消除时自动切换回基于操作日志的数据抽取方式,避免了采用单一数据抽取算法难以平衡数据发送延迟或吞吐的问题。
🍕 source.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据
- 如果要使用 pipe 构建 A -> B -> C 的数据同步,那么 B -> C 的 pipe 需要将该参数为 true 后,A -> B 中 A 通过 pipe 写入 B 的数据才能被正确转发到 C
- 如果要使用 pipe 构建 A <-> B 的双向数据同步(双活),那么 A -> B 和 B -> A 的 pipe 都需要将该参数设置为 false,否则将会造成数据无休止的集群间循环转发
3.2 预置 processor 插件
do-nothing-processor
作用:不对 source 传入的事件做任何的处理。
| key | value | value 取值范围 | required or optional with default |
|---|---|---|---|
| processor | do-nothing-processor | String: do-nothing-processor | required |
3.3 预置 sink 插件
do-nothing-sink
作用:不对 processor 传入的事件做任何的处理。
| key | value | value 取值范围 | required or optional with default |
|---|---|---|---|
| sink | do-nothing-sink | String: do-nothing-sink | required |
4. 流处理任务管理
4.1 创建流处理任务
使用 CREATE PIPE 语句来创建流处理任务。以数据同步流处理任务的创建为例,示例 SQL 语句如下:
CREATE PIPE <PipeId> -- PipeId 是能够唯一标定流处理任务的名字
WITH SOURCE (
-- 默认的 IoTDB 数据抽取插件
'source' = 'iotdb-source',
-- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
'source.pattern' = 'root.timecho',
-- 是否抽取历史数据
'source.history.enable' = 'true',
-- 描述被抽取的历史数据的时间范围,表示最早时间
'source.history.start-time' = '2011.12.03T10:15:30+01:00',
-- 描述被抽取的历史数据的时间范围,表示最晚时间
'source.history.end-time' = '2022.12.03T10:15:30+01:00',
-- 是否抽取实时数据
'source.realtime.enable' = 'true',
-- 描述实时数据的抽取方式
'source.realtime.mode' = 'hybrid',
)
WITH PROCESSOR (
-- 默认的数据处理插件,即不做任何处理
'processor' = 'do-nothing-processor',
)
WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
'sink.port' = '6667',
)创建流处理任务时需要配置 PipeId 以及三个插件部分的参数:
| 配置项 | 说明 | 是否必填 | 默认实现 | 默认实现说明 | 是否允许自定义实现 |
|---|---|---|---|---|---|
| PipeId | 全局唯一标定一个流处理任务的名称 | - | - | - | |
| source | Pipe Source 插件,负责在数据库底层抽取流处理数据 | 选填 | iotdb-source | 将数据库的全量历史数据和后续到达的实时数据接入流处理任务 | 否 |
| processor | Pipe Processor 插件,负责处理数据 | 选填 | do-nothing-processor | 对传入的数据不做任何处理 | |
| sink | Pipe Sink 插件,负责发送数据 | - | - |
示例中,使用了 iotdb-source、do-nothing-processor 和 iotdb-thrift-sink 插件构建数据流处理任务。IoTDB 还内置了其他的流处理插件,请查看“系统预置流处理插件”一节。
一个最简的 CREATE PIPE 语句示例如下:
CREATE PIPE <PipeId> -- PipeId 是能够唯一标定流处理任务的名字
WITH SINK (
-- IoTDB 数据发送插件,目标端为 IoTDB
'sink' = 'iotdb-thrift-sink',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
'sink.ip' = '127.0.0.1',
-- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
'sink.port' = '6667',
)其表达的语义是:将本数据库实例中的全量历史数据和后续到达的实时数据,同步到目标为 127.0.0.1:6667 的 IoTDB 实例上。
注意:
SOURCE 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
SINK 为必填配置,需要在 CREATE PIPE 语句中声明式配置
SINK 具备自复用能力。对于不同的流处理任务,如果他们的 SINK 具备完全相同 KV 属性的(所有属性的 key 对应的 value 都相同),那么系统最终只会创建一个 SINK 实例,以实现对连接资源的复用。
- 例如,有下面 pipe1, pipe2 两个流处理任务的声明:
CREATE PIPE pipe1 WITH SINK ( 'sink' = 'iotdb-thrift-sink', 'sink.ip' = 'localhost', 'sink.port' = '9999', ) CREATE PIPE pipe2 WITH SINK ( 'sink' = 'iotdb-thrift-sink', 'sink.port' = '9999', 'sink.ip' = 'localhost', )- 因为它们对 SINK 的声明完全相同(即使某些属性声明时的顺序不同),所以框架会自动对它们声明的 SINK 进行复用,最终 pipe1, pipe2 的 SINK 将会是同一个实例。
在 source 为默认的 iotdb-source,且 source.forwarding-pipe-requests 为默认值 true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
- IoTDB A -> IoTDB B -> IoTDB A
- IoTDB A -> IoTDB A
4.2 启动流处理任务
CREATE PIPE 语句成功执行后,流处理任务相关实例会被创建,但整个流处理任务的运行状态会被置为 STOPPED,即流处理任务不会立刻处理数据(V1.3.0)。在 1.3.1 及以上的版本,流处理任务的运行状态在创建后将被立即置为 RUNNING。
可以使用 START PIPE 语句使流处理任务开始处理数据:
START PIPE <PipeId>4.3 停止流处理任务
使用 STOP PIPE 语句使流处理任务停止处理数据:
STOP PIPE <PipeId>4.4 删除流处理任务
使用 DROP PIPE 语句使流处理任务停止处理数据(当流处理任务状态为 RUNNING 时),然后删除整个流处理任务流处理任务:
DROP PIPE <PipeId>用户在删除流处理任务前,不需要执行 STOP 操作。
4.5 展示流处理任务
使用 SHOW PIPES 语句查看所有流处理任务:
SHOW PIPES查询结果如下:
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
| ID| CreationTime | State|PipeSource|PipeProcessor|PipeSink|ExceptionMessage|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| {}|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+
|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
+-----------+-----------------------+-------+----------+-------------+--------+----------------+可以使用 <PipeId> 指定想看的某个流处理任务状态:
SHOW PIPE <PipeId>您也可以通过 where 子句,判断某个 <PipeId> 使用的 Pipe Sink 被复用的情况。
SHOW PIPES
WHERE SINK USED BY <PipeId>4.6 流处理任务运行状态迁移
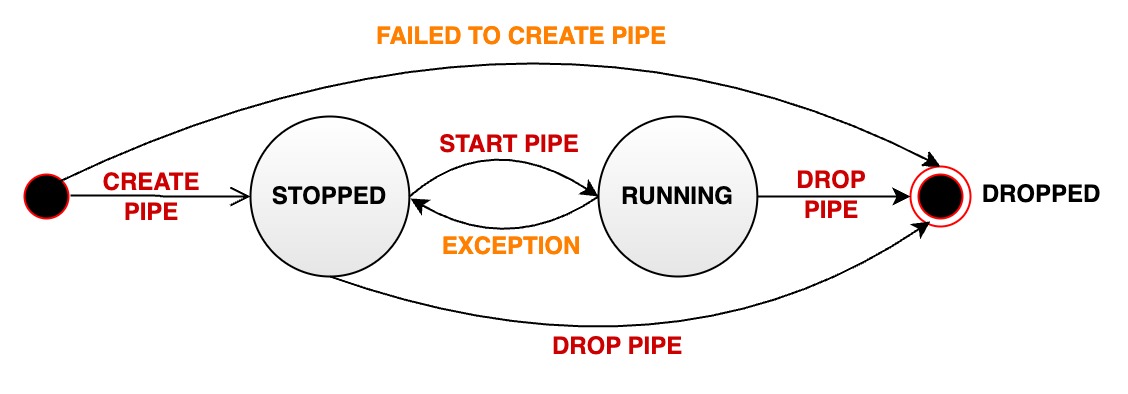
一个流处理 pipe 在其的生命周期中会经过多种状态:
- RUNNING: pipe 正在正常工作
- 当一个 pipe 被成功创建之后,其初始状态为工作状态(V1.3.1+)
- STOPPED: pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- 当一个 pipe 被成功创建之后,其初始状态为暂停状态(V1.3.0)
- 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
- DROPPED: pipe 任务被永久删除
下图表明了所有状态以及状态的迁移:
5. 权限管理
5.1 流处理任务
| 权限名称 | 描述 |
|---|---|
| USE_PIPE | 注册流处理任务。路径无关。 |
| USE_PIPE | 开启流处理任务。路径无关。 |
| USE_PIPE | 停止流处理任务。路径无关。 |
| USE_PIPE | 卸载流处理任务。路径无关。 |
| USE_PIPE | 查询流处理任务。路径无关。 |
5.2 流处理任务插件
| 权限名称 | 描述 |
|---|---|
| USE_PIPE | 注册流处理任务插件。路径无关。 |
| USE_PIPE | 卸载流处理任务插件。路径无关。 |
| USE_PIPE | 查询流处理任务插件。路径无关。 |
6. 配置参数
在 iotdb-system.properties 中:
V1.3.0+:
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
# pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
# The maximum number of selectors that can be used in the async connector.
# pipe_async_connector_selector_number=1
# The core number of clients that can be used in the async connector.
# pipe_async_connector_core_client_number=8
# The maximum number of clients that can be used in the async connector.
# pipe_async_connector_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# pipe_air_gap_receiver_port=9780V1.3.1+:
# Uncomment the following field to configure the pipe lib directory.
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
# pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# pipe_sink_timeout_ms=900000
# The maximum number of selectors that can be used in the sink.
# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
# pipe_sink_selector_number=4
# The maximum number of clients that can be used in the sink.
# pipe_sink_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# pipe_air_gap_receiver_port=9780