
Data Sync
Data Sync
Data synchronization is a typical requirement in industrial Internet of Things (IoT). Through data synchronization mechanisms, it is possible to achieve data sharing between IoTDB, and to establish a complete data link to meet the needs for internal and external network data interconnectivity, edge-cloud synchronization, data migration, and data backup.
1. Function Overview
1.1 Data Synchronization
A data synchronization task consists of three stages:
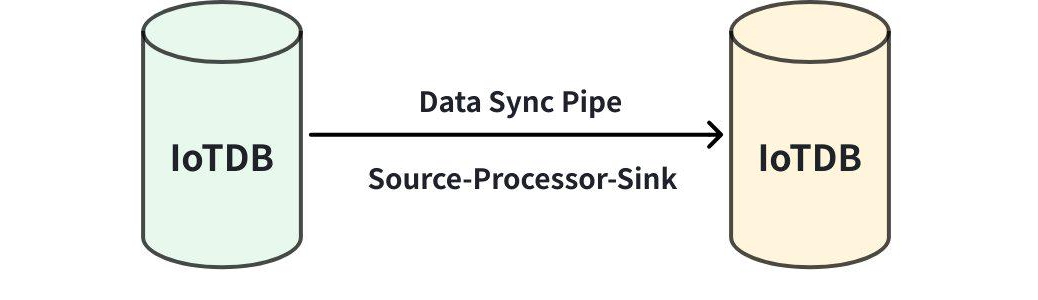
- Source Stage:This part is used to extract data from the source IoTDB, defined in the source section of the SQL statement.
- Process Stage:This part is used to process the data extracted from the source IoTDB, defined in the processor section of the SQL statement.
- Sink Stage:This part is used to send data to the target IoTDB, defined in the sink section of the SQL statement.
By declaratively configuring the specific content of the three parts through SQL statements, flexible data synchronization capabilities can be achieved. Currently, data synchronization supports the synchronization of the following information, and you can select the synchronization scope when creating a synchronization task (the default is data.insert, which means synchronizing newly written data):
| Synchronization Scope | Synchronization Content | Description |
|---|---|---|
| all | All scopes | |
| data(Data) | insert | Synchronize newly written data |
| delete | Synchronize deleted data | |
| schema | database | Synchronize database creation, modification or deletion operations |
| timeseries | Synchronize the definition and attributes of time series | |
| TTL | Synchronize the data retention time | |
| auth | - | Synchronize user permissions and access control |
1.2 Functional limitations and instructions
- The schema and auth synchronization functions have the following limitations:
When using schema synchronization, it is required that the consensus protocol for
Schema regionandConfigNodemust be the default ratis protocol. This means that theiotdb-system.propertiesconfiguration file should contain the settingsconfig_node_consensus_protocol_class=org.apache.iotdb.consensus.ratis.RatisConsensusandschema_region_consensus_protocol_class=org.apache.iotdb.consensus.ratis.RatisConsensus. If these are not specified, the default ratis protocol is used.To prevent potential conflicts, please disable the automatic creation of schema on the receiving end when enabling schema synchronization. This can be done by setting the
enable_auto_create_schemaconfiguration in theiotdb-system.propertiesfile to false.When schema synchronization is enabled, the use of custom plugins is not supported.
In a dual-active cluster, schema synchronization should avoid simultaneous operations on both ends.
During data synchronization tasks, please avoid performing any deletion operations to prevent inconsistent states between the two ends.
- Pipe Permission Control Specifications
When creating a pipe, a username and password can be specified for the extraction/write‑back plugins. If the password is incorrect, creation is prohibited. If not specified, the current user is used for synchronization by default.
During data/metadata synchronization, filtering is first performed according to the path pattern (pattern/path) configured in the Pipe, followed by authentication based on the user’s read permissions:
- If the permission scope is greater than or equal to the write path: full synchronization.
- If the permission scope has no intersection with the write path: no synchronization.
- If the permission scope is smaller than the write path or overlaps partially: synchronize only the intersecting part.
When encountering data for which the user lacks permission:
- If the sender’s skipIf=no‑privileges, the unauthorized data is skipped.
- If skipIf is left empty (unconfigured), the task reports an error (Error 803).
- Note: This skipIf configuration is independent of the receiver’s skipIf setting (which defaults to empty).
Data under root.__system and root.__audit will not be synchronized.
- Automatic Type Conversion for Pipe Sink
When Pipe fails to write data to the sink due to field type mismatches, IoTDB automatically converts the data to the field types defined in the existing sink schema and retries the write operation to improve synchronization success rate. This feature is controlled by the parameter sink.exception.data.convert-on-type-mismatch. Refer to the subsequent sink parameter table for detailed parameter descriptions.
The conversion rules for type mismatches are as follows:
| Source Type | Target Type | Conversion Rule |
|---|---|---|
| Numeric Type | Numeric Type | Convert to the target numeric type. Truncation, precision loss or overflow may occur. |
| Numeric Type | BOOLEAN | 0 is converted to false; non-zero values are converted to true. |
| BOOLEAN | Numeric Type | true is converted to 1; false is converted to 0. |
| TEXT, STRING, BLOB | BOOLEAN | Parse the string into a BOOLEAN value. |
| TEXT, STRING, BLOB | Numeric Type | Parse the string into the target numeric type. If parsing fails, write the default value 0, 0L or 0.0. |
| TEXT, STRING, BLOB | TIMESTAMP | Parse the string into a TIMESTAMP value. If parsing fails, write the default value 0L. |
| TEXT, STRING, BLOB | DATE | Parse the string into a DATE value. If parsing fails, write the default date 1970-01-01. |
| Invalid Numeric Value | DATE | If conversion to a valid DATE fails, write the default date 1970-01-01. |
| DATE | TIMESTAMP | Convert to the timestamp of 00:00 (UTC) on the same day. |
| TIMESTAMP | DATE | Convert to the corresponding date in UTC. |
Note: Automatic conversion is performed based on the existing sink schema and will not modify the sink schema. This feature prioritizes continuous data synchronization, which may result in precision loss or writing of default values.
2. Usage Instructions
Data synchronization tasks have three states: RUNNING, STOPPED, and DROPPED. The task state transitions are shown in the following diagram:
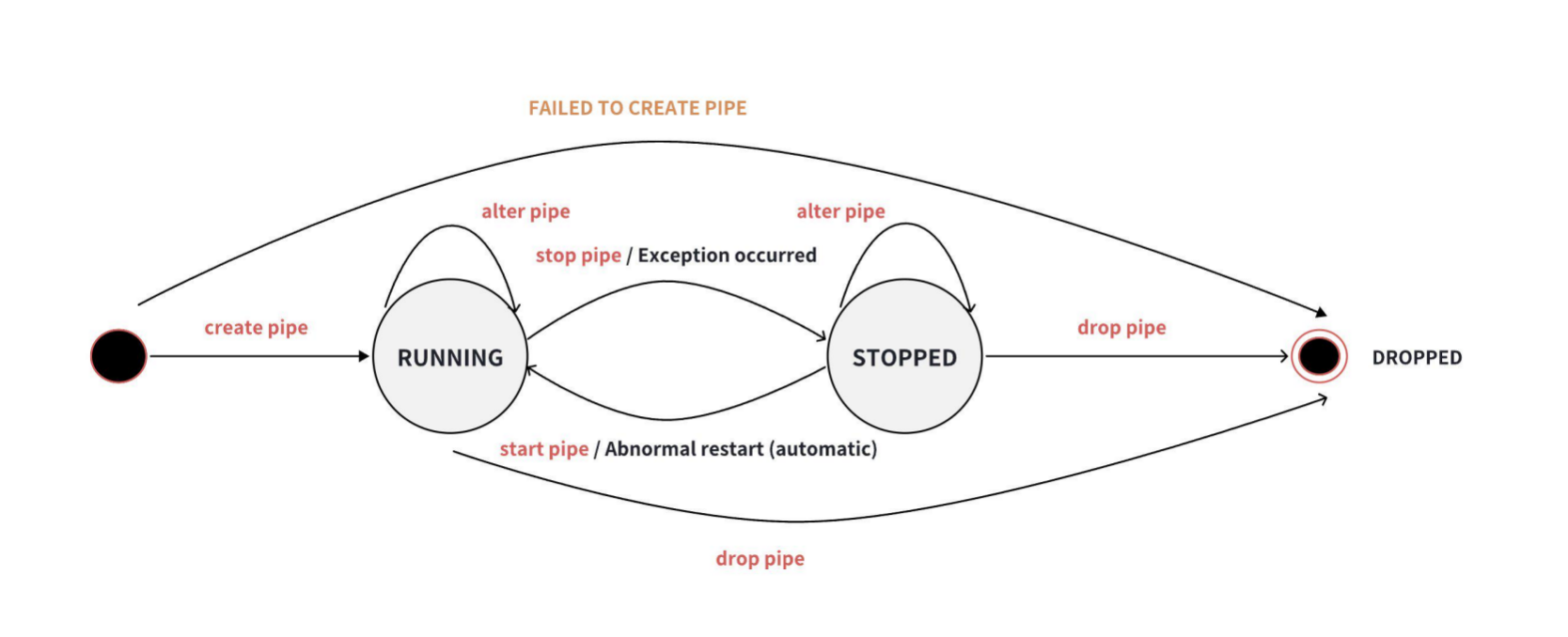
After creation, the task will start directly, and when the task stops abnormally, the system will automatically attempt to restart the task.
Provide the following SQL statements for state management of synchronization tasks.
2.1 Create Task
Use the CREATE PIPE statement to create a data synchronization task. The PipeId and sink attributes are required, while source and processor are optional. When entering the SQL, note that the order of the SOURCE and SINK plugins cannot be swapped.
The SQL example is as follows:
CREATE PIPE [IF NOT EXISTS] <PipeId> -- PipeId is the name that uniquely identifies the task.
-- Data extraction plugin, optional plugin
WITH SOURCE (
[<parameter> = <value>,],
)
-- Data processing plugin, optional plugin
WITH PROCESSOR (
[<parameter> = <value>,],
)
-- Data connection plugin, required plugin
WITH SINK (
[<parameter> = <value>,],
)IF NOT EXISTS semantics: Used in creation operations to ensure that the create command is executed when the specified Pipe does not exist, preventing errors caused by attempting to create an existing Pipe.
Note:
Starting from V2.0.8, when creating a full data synchronization Pipe (e.g. Pipeid: alldatapipe), the system will automatically split it into two independent Pipes:
- History Pipe: The PipeId is the original name plus the suffix
_history(e.g.alldatapipe_history). The source parameter carries the default configurations:'realtime.enable'='false', 'inclusion'='data.insert', 'inclusion.exclusion'='' - Realtime Pipe: The PipeId is the original name plus the suffix
_realtime(e.g.alldatapipe_realtime). The source parameter carries the default configuration:'history.enable'='false'. If metadata synchronization is configured, the Realtime Pipe will be responsible for sending the data.
After successful creation, the original PipeId (e.g. alldatapipe) will no longer be a valid identifier. When performing task operations such as starting, stopping, deleting, or viewing, you must use the split independent PipeId (i.e. *_history or *_realtime). For operation examples, see the View Task section
2.2 Start Task
Start processing data:
START PIPE<PipeId>2.3 Stop Task
Stop processing data:
STOP PIPE <PipeId>2.4 Delete Task
Deletes the specified task:
DROP PIPE [IF EXISTS] <PipeId>IF EXISTS semantics: Used in deletion operations to ensure that when a specified Pipe exists, the delete command is executed to prevent errors caused by attempting to delete non-existent Pipes.
Deleting a task does not require stopping the synchronization task first.
2.5 View Task
View all tasks:
SHOW PIPESTo view a specified task:
SHOW PIPE <PipeId>Example of the show pipes result for a pipe:
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
+--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+The meanings of each column are as follows:
- ID:The unique identifier for the synchronization task
- CreationTime:The time when the synchronization task was created
- State:The state of the synchronization task
- PipeSource:The source of the synchronized data stream
- PipeProcessor:The processing logic of the synchronized data stream during transmission
- PipeSink:The destination of the synchronized data stream
- ExceptionMessage:Displays the exception information of the synchronization task
- RemainingEventCount (Statistics with Delay): The number of remaining events, which is the total count of all events in the current data synchronization task, including data and schema synchronization events, as well as system and user-defined events.
- EstimatedRemainingSeconds (Statistics with Delay): The estimated remaining time, based on the current number of events and the rate at the pipe, to complete the transfer.
Example:
In V2.0.8 and later versions, create a full data synchronization task and view the task details.
IoTDB> create pipe alldatapipe with source('inclusion'='all','exclusion'='auth') with sink('node-urls'='127.0.0.1:6668')
IoTDB> show pipe alldatapipe_history
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State| PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
|alldatapipe_history|2025-12-18T15:06:16.697|RUNNING|{exclusion=auth, history.enable=true, inclusion=data.insert, inclusion.exclusion=, realtime.enable=false}| {}|{node-urls=127.0.0.1:6668}| | 0| 0.00|
+-------------------+-----------------------+-------+---------------------------------------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
IoTDB> show pipe alldatapipe_realtime
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
| ID| CreationTime| State| PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+
|alldatapipe_realtime|2025-12-18T15:06:16.312|RUNNING|{exclusion=auth, history.enable=false, inclusion=all, realtime.enable=true}| {}|{node-urls=127.0.0.1:6668}| | 0| 0.00|
+--------------------+-----------------------+-------+---------------------------------------------------------------------------+-------------+--------------------------+----------------+-------------------+-------------------------+2.6 Modify Task
The ALTER PIPE statement dynamically updates an existing PIPE and supports modifying or replacing the configuration of source, processor, and sink.
ALTER PIPE [IF EXISTS] <PipeId>
MODIFY/REPLACE SOURCE(...)
MODIFY/REPLACE PROCESSOR(...)
MODIFY/REPLACE SINK(...)Description:
- Executing this operation does not change the running state of the PIPE. It is equivalent to keeping the processing progress of the original PipeId and creating a new PIPE at the original progress position.
- The modify/replace parameters for source/processor/sink are all optional. If no modification parameter is specified, it is equivalent to deleting the current PIPE and recreating it with the original configuration and progress.
- For a plugin specified with modify, the plugin's other parameters are retained, and only the given parameters are replaced or added.
- For a plugin specified with replace, all parameters of the plugin are replaced directly.
- When the [IF EXISTS] keyword is used, execution succeeds even if no Pipe with the same name exists, but no operation is actually performed.
Example:
ALTER PIPE A2B REPLACE SINK ('sink'='iotdb-thrift-sink', 'node-urls' = '127.0.0.1:6668');2.7 Synchronization Plugins
To make the overall architecture more flexible to match different synchronization scenario requirements, we support plugin assembly within the synchronization task framework. The system comes with some pre-installed common plugins that you can use directly. At the same time, you can also customize processor plugins and Sink plugins, and load them into the IoTDB system for use. You can view the plugins in the system (including custom and built-in plugins) with the following statement:
SHOW PIPEPLUGINSThe return result is as follows (version 1.3.2):
IoTDB> SHOW PIPEPLUGINS
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| PluginName|PluginType| ClassName| PluginJar|
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.airgap.IoTDBAirGapConnector| |
| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
+------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+Detailed introduction of pre-installed plugins is as follows (for detailed parameters of each plugin, please refer to the Parameter Description section):
| Type | Custom Plugin | Plugin Name | Description | Applicable Version |
|---|---|---|---|---|
| source plugin | Not Supported | iotdb-source | The default extractor plugin, used to extract historical or real-time data from IoTDB | 1.2.x |
| processor plugin | Supported | do-nothing-processor | The default processor plugin, which does not process the incoming data | 1.2.x |
| sink plugin | Supported | do-nothing-sink | Does not process the data that is sent out | 1.2.x |
| iotdb-thrift-sink | The default sink plugin ( V1.3.1+ ), used for data transfer between IoTDB ( V1.2.0+ ) and IoTDB( V1.2.0+ ) . It uses the Thrift RPC framework to transfer data, with a multi-threaded async non-blocking IO model, high transfer performance, especially suitable for scenarios where the target end is distributed | 1.2.x | ||
| iotdb-air-gap-sink | Used for data synchronization across unidirectional data diodes from IoTDB ( V1.2.0+ ) to IoTDB ( V1.2.0+ ). Supported diode models include Nanrui Syskeeper 2000, etc | 1.2.x | ||
| iotdb-thrift-ssl-sink | Used for data transfer between IoTDB ( V1.3.1+ ) and IoTDB ( V1.2.0+ ). It uses the Thrift RPC framework to transfer data, with a single-threaded sync blocking IO model, suitable for scenarios with higher security requirements | 1.3.1+ |
For importing custom plugins, please refer to the Stream Processing section.
3. Use examples
3.1 Full data synchronisation
This example is used to demonstrate the synchronisation of all data from one IoTDB to another IoTDB with the data link as shown below:

In this example, we can create a synchronization task named A2B to synchronize the full data from A IoTDB to B IoTDB. The iotdb-thrift-sink plugin (built-in plugin) for the sink is required. The URL of the data service port of the DataNode node on the target IoTDB needs to be configured through node-urls, as shown in the following example statement:
create pipe A2B
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB3.2 Partial data synchronization
This example is used to demonstrate the synchronisation of data from a certain historical time range (8:00pm 23 August 2023 to 8:00pm 23 October 2023) to another IoTDB, the data link is shown below:

In this example, we can create a synchronization task named A2B. First, we need to define the range of data to be transferred in the source. Since the data being transferred is historical data (historical data refers to data that existed before the creation of the synchronization task), we need to configure the start-time and end-time of the data and the transfer mode mode. The URL of the data service port of the DataNode node on the target IoTDB needs to be configured through node-urls.
The detailed statements are as follows:
create pipe A2B
WITH SOURCE (
'source'= 'iotdb-source',
'realtime.mode' = 'stream' -- The extraction mode for newly inserted data (after pipe creation)
'path' = 'root.vehicle.**', -- Scope of Data Synchronization
'start-time' = '2023.08.23T08:00:00+00:00', -- The start event time for synchronizing all data, including start-time
'end-time' = '2023.10.23T08:00:00+00:00' -- The end event time for synchronizing all data, including end-time
)
with SINK (
'sink'='iotdb-thrift-async-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)3.3 Bidirectional data transfer
This example is used to demonstrate the scenario where two IoTDB act as active-active pairs, with the data link shown in the figure below:

In this example, to avoid infinite data loops, the forwarding-pipe-requests parameter on A and B needs to be set to false, indicating that data transmitted from another pipe is not forwarded, and to keep the data consistent on both sides, the pipe needs to be configured with inclusion=all to synchronize full data and metadata.
The detailed statement is as follows:
On A IoTDB, execute the following statement:
create pipe AB
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'forwarding-pipe-requests' = 'false' -- Do not forward data written by other Pipes
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)On B IoTDB, execute the following statement:
create pipe BA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'forwarding-pipe-requests' = 'false' -- Do not forward data written by other Pipes
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6667', -- The URL of the data service port of the DataNode node on the target IoTDB
)3.4 Edge-cloud data transfer
This example is used to demonstrate the scenario where data from multiple IoTDB is transferred to the cloud, with data from clusters B, C, and D all synchronized to cluster A, as shown in the figure below:
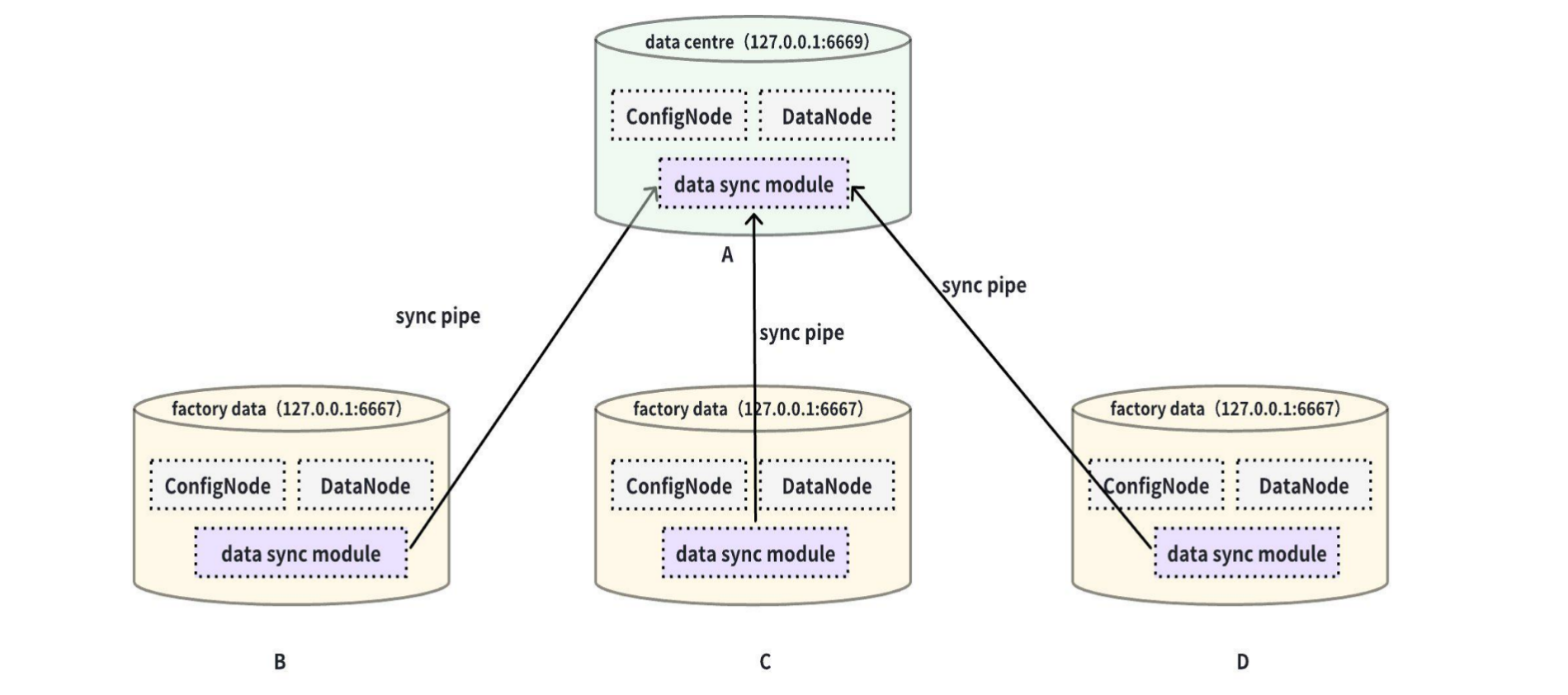
In this example, to synchronize the data from clusters B, C, and D to A, the pipe between BA, CA, and DA needs to configure the path to limit the range, and to keep the edge and cloud data consistent, the pipe needs to be configured with inclusion=all to synchronize full data and metadata. The detailed statement is as follows:
On B IoTDB, execute the following statement to synchronize data from B to A:
create pipe BA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)On C IoTDB, execute the following statement to synchronize data from C to A:
create pipe CA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)On D IoTDB, execute the following statement to synchronize data from D to A:
create pipe DA
with source (
'inclusion'='all', -- Indicates synchronization of full data, schema , and auth
'path'='root.db.**', -- Limit the range
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)3.5 Cascading data transfer
This example is used to demonstrate the scenario where data is transferred in a cascading manner between multiple IoTDB, with data from cluster A synchronized to cluster B, and then to cluster C, as shown in the figure below:
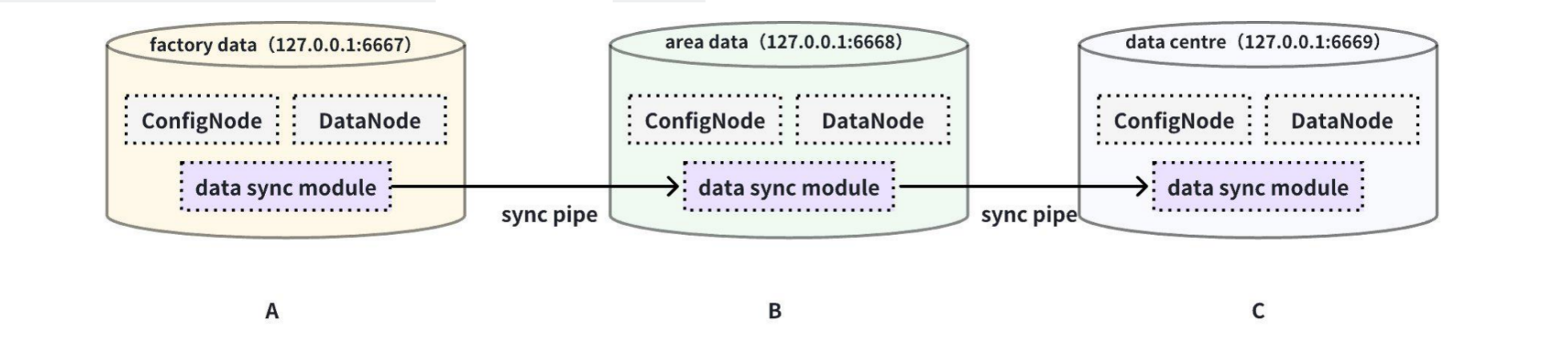
In this example, to synchronize the data from cluster A to C, the forwarding-pipe-requests needs to be set to true between BC. The detailed statement is as follows:
On A IoTDB, execute the following statement to synchronize data from A to B:
create pipe AB
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)On B IoTDB, execute the following statement to synchronize data from B to C:
create pipe BC
with source (
'forwarding-pipe-requests' = 'true' -- Whether to forward data written by other Pipes
)
with sink (
'sink'='iotdb-thrift-sink',
'node-urls' = '127.0.0.1:6669', -- The URL of the data service port of the DataNode node on the target IoTDB
)
)3.6 Cross-gate data transfer
This example is used to demonstrate the scenario where data from one IoTDB is synchronized to another IoTDB through a unidirectional gateway, as shown in the figure below:
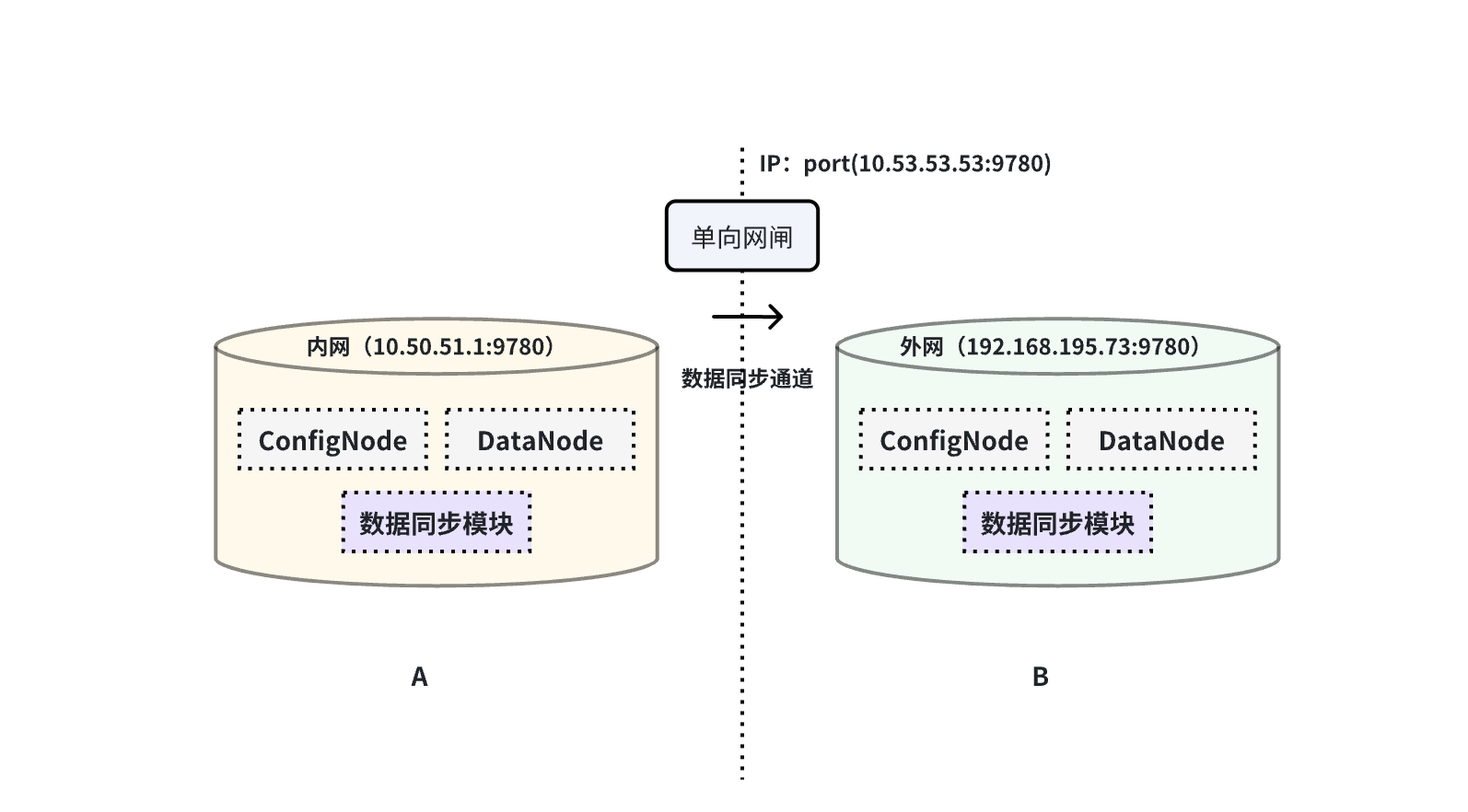
In this example, the iotdb-air-gap-sink plugin in the sink task needs to be used . After configuring the gateway, execute the following statement on A IoTDB. Fill in the node-urls with the URL of the data service port of the DataNode node on the target IoTDB configured by the gateway, as detailed below:
create pipe A2B
with sink (
'sink'='iotdb-air-gap-sink',
'node-urls' = '10.53.53.53:9780', -- The URL of the data service port of the DataNode node on the target IoTDBNote:
- When creating a pipe for synchronization across a network gap (data diode), you must ensure that the target user on the receiving end already exists. If the receiving-end user is missing at the time of pipe creation, data prior to the subsequent creation of that user will not be synchronized.
- Currently supported network gap device models are listed in the table below.
For other models of network gateway devices, Please contact timechodb staff to confirm compatibility.
| Gateway Type | Model | Return Packet Limit | Send Limit |
|---|---|---|---|
| Forward Gate | NARI Syskeeper-2000 Forward Gate | All 0 / All 1 bytes | No Limit |
| Forward Gate | XJ Self-developed Diaphragm | All 0 / All 1 bytes | No Limit |
| Unknown | WISGAP | No Limit | No Limit |
| Forward Gate | KEDONG StoneWall-2000 Network Security Isolation Device | No Limit | No Limit |
| Reverse Gate | NARI Syskeeper-2000 Reverse Direction | All 0 / All 1 bytes | Meet E Language Format |
| Unknown | DPtech ISG5000 | No Limit | No Limit |
| Unknown | GAP XL—GAP | No Limit | No Limit |
3.7 Compression Synchronization (V1.3.3+)
IoTDB supports specifying data compression methods during synchronization. Real time compression and transmission of data can be achieved by configuring the compressor parameter. Compressor currently supports 5 optional algorithms: snappy/gzip/lz4/zstd/lzma2, and can choose multiple compression algorithm combinations to compress in the order of configuration rate-limit-bytes-per-second(supported in V1.3.3 and later versions) is the maximum number of bytes allowed to be transmitted per second, calculated as compressed bytes. If it is less than 0, there is no limit.
For example, to create a synchronization task named A2B:
create pipe A2B
with sink (
'node-urls' = '127.0.0.1:6668', -- The URL of the data service port of the DataNode node on the target IoTDB
'compressor' = 'snappy,lz4' -- Compression algorithms
)3.8 Encrypted Synchronization (V1.3.1+)
IoTDB supports the use of SSL encryption during the synchronization process, ensuring the secure transfer of data between different IoTDB instances. By configuring SSL-related parameters, such as the certificate address and password (ssl.trust-store-path)、(ssl.trust-store-pwd), data can be protected by SSL encryption during the synchronization process.
For example, to create a synchronization task named A2B:
create pipe A2B
with sink (
'sink'='iotdb-thrift-ssl-sink',
'node-urls'='127.0.0.1:6667', -- The URL of the data service port of the DataNode node on the target IoTDB
'ssl.trust-store-path'='pki/trusted', -- The trust store certificate path required to connect to the target DataNode
'ssl.trust-store-pwd'='root' -- The trust store certificate password required to connect to the target DataNode
)4. Reference: Notes
You can adjust the parameters for data synchronization by modifying the IoTDB configuration file (iotdb-system.properties), such as the directory for storing synchronized data. The complete configuration is as follows:
V1.3.3+:
# pipe_receiver_file_dir
# If this property is unset, system will save the data in the default relative path directory under the IoTDB folder(i.e., %IOTDB_HOME%/${cn_system_dir}/pipe/receiver).
# If it is absolute, system will save the data in the exact location it points to.
# If it is relative, system will save the data in the relative path directory it indicates under the IoTDB folder.
# Note: If pipe_receiver_file_dir is assigned an empty string(i.e.,zero-size), it will be handled as a relative path.
# effectiveMode: restart
# For windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is absolute. Otherwise, it is relative.
# pipe_receiver_file_dir=data\\confignode\\system\\pipe\\receiver
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_receiver_file_dir=data/confignode/system/pipe/receiver
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# effectiveMode: first_start
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# effectiveMode: restart
# Datatype: int
pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# effectiveMode: restart
# Datatype: int
pipe_sink_timeout_ms=900000
# The maximum number of selectors that can be used in the sink.
# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
# effectiveMode: restart
# Datatype: int
pipe_sink_selector_number=4
# The maximum number of clients that can be used in the sink.
# effectiveMode: restart
# Datatype: int
pipe_sink_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# effectiveMode: restart
# Datatype: Boolean
pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# Datatype: int
# effectiveMode: restart
pipe_air_gap_receiver_port=9780
# The total bytes that all pipe sinks can transfer per second.
# When given a value less than or equal to 0, it means no limit.
# default value is -1, which means no limit.
# effectiveMode: hot_reload
# Datatype: double
pipe_all_sinks_rate_limit_bytes_per_second=-15. Reference: parameter description
5.1 source parameter(V1.3.3)
| Key | Value | Value range | Required | Default value |
|---|---|---|---|---|
| source | iotdb-source | String: iotdb-source | Yes | - |
| inclusion | Used to specify the range of data to be synchronized in the data synchronization task, including data, schema, and auth | String:all, data(insert,delete), schema(database,timeseries,ttl), auth | No | data.insert |
| inclusion.exclusion | Used to exclude specific operations from the range specified by inclusion, reducing the amount of data synchronized | String:all, data(insert,delete), schema(database,timeseries,ttl), auth | No | - |
| mode.streaming | Specifies the capture source for time-series data writes. Applicable when mode.streamingis false, determining the source for capturing data.insertspecified in inclusion. Offers two strategies:- true: Dynamic capture selection. The system adaptively chooses between capturing individual write requests or only TsFile sealing requests based on downstream processing speed. Prioritizes capturing write requests for lower latency when processing is fast; captures only file sealing requests to avoid backlog when slow. Suitable for most scenarios, balancing latency and throughput optimally.- false: Fixed batch capture. Captures only TsFile sealing requests. Suitable for resource-constrained scenarios to reduce system load. Note: The snapshot data captured upon pipe startup is only provided to downstream processing in file format. | Boolean: true / false | No | true |
| mode.strict | Determines the strictness when filtering data using time/ path/ database-name/ table-nameparameters:- true: Strict filtering. The system strictly filters captured data according to the given conditions, ensuring only matching data is selected.- false: Non-strict filtering. The system may include some extra data during filtering. Suitable for performance-sensitive scenarios to reduce CPU and I/O consumption. | Boolean: true / false | No | true |
| mode.snapshot | Determines the capture mode for time-series data, affecting the dataspecified in inclusion. Offers two modes:- true: Static data capture. Upon pipe startup, a one-time data snapshot is captured. The pipe will automatically terminate (DROP PIPE SQL is executed automatically) after the snapshot data is fully consumed.- false: Dynamic data capture. In addition to capturing a snapshot upon startup, the pipe continuously captures subsequent data changes. The pipe runs continuously to handle the dynamic data stream. | Boolean: true / false | No | false |
| path | Can be specified when the user connects with sql_dialectset to tree. For upgraded user pipes, the default sql_dialectis tree. This parameter determines the capture scope for time-series data, affecting the dataspecified in inclusion, as well as some sequence-related metadata. Data is selected into the streaming pipe if its tree model path matches the specified path. Starting from version V2.0.8.2, this parameter supports specifying multiple exact paths in a single pipe, e.g., 'path'='root.test.d0.s1,root.test.d0.s2,root.test.d0.s3'. | String: IoTDB-standard tree path pattern, wildcards allowed | No | root.** |
| start-time | The start event time for synchronizing all data, including start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | No | Long.MIN_VALUE |
| end-time | The end event time for synchronizing all data, including end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | No | Long.MAX_VALUE |
| forwarding-pipe-requests | Whether to forward data written by other Pipes (usually data synchronization) | Boolean: true / false | No | true |
| mods | Same as mods.enable, whether to send the MODS file for TSFile. | Boolean: true / false | No | false |
| skipIf | Which errors can be skipped? Currently only the insufficient privileges error. | String:no-privileges | No | no-privileges |
💎 Note: The difference between the values of true and false for the data extraction mode
mode.streaming
- True (recommended): Under this value, the task will process and send the data in real-time. Its characteristics are high timeliness and low throughput.
- False: Under this value, the task will process and send the data in batches (according to the underlying data files). Its characteristics are low timeliness and high throughput.
5.2 sink parameter
iotdb-thrift-sink
| Parameter | Description | Value Range | Required | Default Value |
|---|---|---|---|---|
| sink | iotdb-thrift-sink or iotdb-thrift-async-sink | String: iotdb-thrift-sink or iotdb-thrift-async-sink | Yes | - |
| node-urls | URLs of the DataNode service ports on the target IoTDB. (please note that the synchronization task does not support forwarding to its own service). | String. Example:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Yes | - |
| user/username | Username for connecting to the target IoTDB. Must have appropriate permissions. | String | No | root |
| password | Password for the username. | String | No | TimechoDB@2021 (Before V2.0.6.x it is root) |
| batch.enable | Enables batch mode for log transmission to improve throughput and reduce IOPS. | Boolean: true, false | No | true |
| batch.max-delay-seconds | Maximum delay (in seconds) for batch transmission. | Integer | No | 1 |
| batch.max-delay-ms | Maximum delay (in ms) for batch transmission. (Available since v2.0.5) | Integer | No | 1 |
| batch.size-bytes | Maximum batch size (in bytes) for batch transmission. | Long | No | 1610241024 |
| compressor | The selected RPC compression algorithm. Multiple algorithms can be configured and will be adopted in sequence for each request. | String: snappy / gzip / lz4 / zstd / lzma2 | No | "" |
| compressor.zstd.level | When the selected RPC compression algorithm is zstd, this parameter can be used to additionally configure the compression level of the zstd algorithm. | Int: [-131072, 22] | No | 3 |
| rate-limit-bytes-per-second | The maximum number of bytes allowed to be transmitted per second. The compressed bytes (such as after compression) are calculated. If it is less than 0, there is no limit. | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | No | -1 |
| load-tsfile-strategy | When synchronizing file data, whether the receiver waits for the local load tsfile operation to complete before responding to the sender: sync: Wait for the local load tsfile operation to complete before returning the response. async: Do not wait for the local load tsfile operation to complete; return the response immediately. | String: sync / async | No | sync |
| format | The payload formats for data transmission include the following options: - hybrid: The format depends on what is passed from the processor (either tsfile or tablet), and the sink performs no conversion. - tsfile: Data is forcibly converted to tsfile format before transmission. This is suitable for scenarios like data file backup. - tablet: Data is forcibly converted to tsfile format before transmission. This is useful for data synchronization when the sender and receiver have incompatible data types (to minimize errors). | String: hybrid / tsfile / tablet | No | hybrid |
| exception.data.convert-on-type-mismatch | Whether to enable automatic conversion when data types mismatch on the sink side | Boolean: true / false | No | true |
iotdb-air-gap-sink
| Key | Value | Value Range | Required | Default Value |
|---|---|---|---|---|
| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | Required | - |
| node-urls | The URL of the data service port of any DataNode nodes on the target IoTDB | String. Example: :'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Required | - |
| user/username | Username for connecting to the target IoTDB. Must have appropriate permissions. | String | No | root |
| password | Password for the username. | String | No | TimechoDB@2021 (Before V2.0.6.x it is root) |
| compressor | The selected RPC compression algorithm. Multiple algorithms can be configured and will be adopted in sequence for each request. | String: snappy / gzip / lz4 / zstd / lzma2 | No | "" |
| compressor.zstd.level | When the selected RPC compression algorithm is zstd, this parameter can be used to additionally configure the compression level of the zstd algorithm. | Int: [-131072, 22] | No | 3 |
| rate-limit-bytes-per-second | Maximum bytes allowed per second for transmission (calculated after compression). Set to a value less than 0 for no limit. | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | No | -1 |
| load-tsfile-strategy | When synchronizing file data, whether the receiver waits for the local load tsfile operation to complete before responding to the sender: sync: Wait for the local load tsfile operation to complete before returning the response. async: Do not wait for the local load tsfile operation to complete; return the response immediately. | String: sync / async | No | sync |
| air-gap.handshake-timeout-ms | The timeout duration of the handshake request when the sender and receiver first attempt to establish a connection, unit: ms | Integer | No | 5000 |
| exception.data.convert-on-type-mismatch | Whether to enable automatic conversion when data types mismatch on the sink side | Boolean: true / false | No | true |
iotdb-thrift-ssl-sink
| Parameter | Description | Value Range | Required | Default Value |
|---|---|---|---|---|
| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | Yes | - |
| node-urls | URLs of the DataNode service ports on the target IoTDB. (please note that the synchronization task does not support forwarding to its own service). | String. Example:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | Yes | - |
| user/username | Username for connecting to the target IoTDB. Must have appropriate permissions. | String | No | root |
| password | Password for the username. | String | No | TimechoDB@2021 (Before V2.0.6.x it is root) |
| batch.enable | Enables batch mode for log transmission to improve throughput and reduce IOPS. | Boolean: true, false | No | true |
| batch.max-delay-seconds | Maximum delay (in seconds) for batch transmission. | Integer | No | 1 |
| batch.max-delay-ms | Maximum delay (in ms) for batch transmission. (Available since v2.0.5) | Integer | No | 1 |
| batch.size-bytes | Maximum batch size (in bytes) for batch transmission. | Long | No | 1610241024 |
| compressor | The selected RPC compression algorithm. Multiple algorithms can be configured and will be adopted in sequence for each request. | String: snappy / gzip / lz4 / zstd / lzma2 | No | "" |
| compressor.zstd.level | When the selected RPC compression algorithm is zstd, this parameter can be used to additionally configure the compression level of the zstd algorithm. | Int: [-131072, 22] | No | 3 |
| rate-limit-bytes-per-second | Maximum bytes allowed per second for transmission (calculated after compression). Set to a value less than 0 for no limit. | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | No | -1 |
| load-tsfile-strategy | When synchronizing file data, whether the receiver waits for the local load tsfile operation to complete before responding to the sender: sync: Wait for the local load tsfile operation to complete before returning the response. async: Do not wait for the local load tsfile operation to complete; return the response immediately. | String: sync / async | No | sync |
| ssl.trust-store-path | Path to the trust store certificate for SSL connection. | String: 'pki/trusted' | Yes | - |
| ssl.trust-store-pwd | Password for the trust store certificate. | String: 'root' | Yes | - |
| format | The payload formats for data transmission include the following options: - hybrid: The format depends on what is passed from the processor (either tsfile or tablet), and the sink performs no conversion. - tsfile: Data is forcibly converted to tsfile format before transmission. This is suitable for scenarios like data file backup. - tablet: Data is forcibly converted to tsfile format before transmission. This is useful for data synchronization when the sender and receiver have incompatible data types (to minimize errors). | String: hybrid / tsfile / tablet | No | hybrid |
| exception.data.convert-on-type-mismatch | Whether to enable automatic conversion when data types mismatch on the sink side | Boolean: true / false | No | true |