
运维语句
运维语句
Explain/Explain Analyze 语句
查询分析的意义在于帮助用户理解查询的执行机制和性能瓶颈,从而实现查询优化和性能提升。这不仅关乎到查询的执行效率,也直接影响到应用的用户体验和资源的有效利用。为了进行有效的查询分析,IoTDB V1.3.2及以上版本提供了查询分析语句:Explain 和 Explain Analyze。
- Explain 语句:允许用户预览查询 SQL 的执行计划,包括 IoTDB 如何组织数据检索和处理。
- Explain Analyze 语句:在 Explain 语句基础上增加了性能分析,完整执行SQL并展示查询执行过程中的时间和资源消耗。为IoTDB用户深入理解查询详情以及进行查询优化提供了详细的相关信息。与其他常用的 IoTDB 排查手段相比,Explain Analyze 没有部署负担,同时能够针对单条 sql 进行分析,能够更好定位问题。各类方法对比如下:
| 方法 | 安装难度 | 业务影响 | 功能范围 |
|---|---|---|---|
| Explain Analyze语句 | 低。无需安装额外组件,为IoTDB内置SQL语句 | 低。只会影响当前分析的单条查询,对线上其他负载无影响 | 支持分布式,可支持对单条SQL进行追踪 |
| 监控面板 | 中。需要安装IoTDB监控面板工具(企业版工具),并开启IoTDB监控服务 | 中。IoTDB监控服务记录指标会带来额外耗时 | 支持分布式,仅支持对数据库整体查询负载和耗时进行分析 |
| Arthas抽样 | 中。需要安装Java Arthas工具(部分内网无法直接安装Arthas,且安装后,有时需要重启应用) | 高。CPU 抽样可能会影响线上业务的响应速度 | 不支持分布式,仅支持对数据库整体查询负载和耗时进行分析 |
Explain 语句
语法
Explain命令允许用户查看SQL查询的执行计划。执行计划以算子的形式展示,描述了IoTDB会如何执行查询。其语法如下,其中SELECT_STATEMENT是查询相关的SQL语句:
EXPLAIN <SELECT_STATEMENT>Explain的返回结果包括了数据访问策略、过滤条件是否下推以及查询计划在不同节点的分配等信息,为用户提供了一种手段,以可视化查询的内部执行逻辑。
示例
# 插入数据
insert into root.explain.data(timestamp, column1, column2) values(1710494762, "hello", "explain")
# 执行explain语句
explain select * from root.explain.data执行上方SQL,会得到如下结果。不难看出,IoTDB分别通过两个SeriesScan节点去获取column1和column2的数据,最后通过fullOuterTimeJoin将其连接。
+-----------------------------------------------------------------------+
| distribution plan|
+-----------------------------------------------------------------------+
| ┌───────────────────┐ |
| │FullOuterTimeJoin-3│ |
| │Order: ASC │ |
| └───────────────────┘ |
| ┌─────────────────┴─────────────────┐ |
| │ │ |
|┌─────────────────────────────────┐ ┌─────────────────────────────────┐|
|│SeriesScan-4 │ │SeriesScan-5 │|
|│Series: root.explain.data.column1│ │Series: root.explain.data.column2│|
|│Partition: 3 │ │Partition: 3 │|
|└─────────────────────────────────┘ └─────────────────────────────────┘|
+-----------------------------------------------------------------------+Explain Analyze 语句
语法
Explain Analyze 是 IOTDB 查询引擎自带的性能分析 SQL,与 Explain 不同,它会执行对应的查询计划并统计执行信息,可以用于追踪一条查询的具体性能分布,用于对资源进行观察,进行性能调优与异常分析。其语法如下:
EXPLAIN ANALYZE [VERBOSE] <SELECT_STATEMENT>其中SELECT_STATEMENT对应需要分析的查询语句;VERBOSE为打印详细分析结果,不填写VERBOSE时EXPLAIN ANALYZE将会省略部分信息。
在EXPLAIN ANALYZE的结果集中,会包含如下信息:
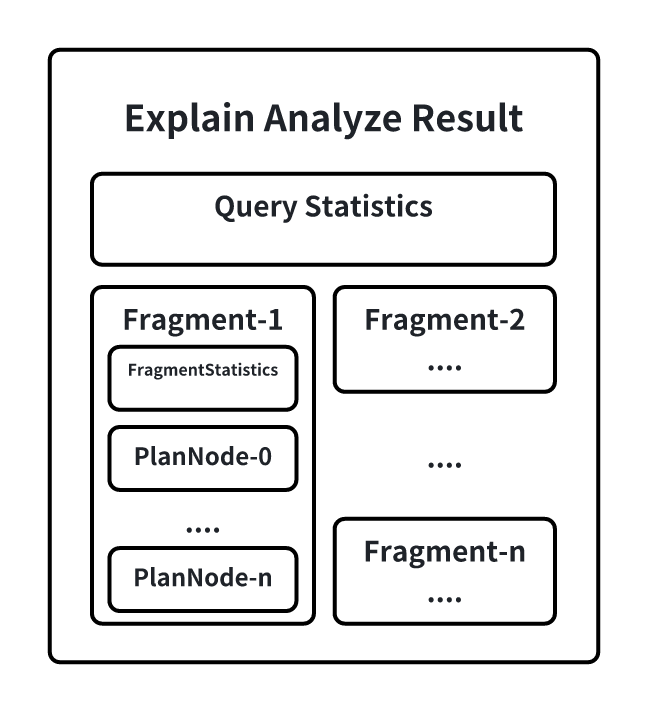
其中:
- QueryStatistics包含查询层面进的统计信息,主要包含规划解析阶段耗时,Fragment元数据等信息。
- FragmentInstance是IoTDB在一个节点上查询计划的封装,每一个节点都会在结果集中输出一份Fragment信息,主要包含FragmentStatistics和算子信息。FragmentStastistics包含Fragment的统计信息,包括总实际耗时(墙上时间),所涉及到的TsFile,调度信息等情况。在一个Fragment的信息输出同时会以节点树层级的方式展示该Fragment下计划节点的统计信息,主要包括:CPU运行时间、输出的数据行数、指定接口被调用的次数、所占用的内存、节点专属的定制信息。
特别说明
- Explain Analyze 语句的结果简化
由于在 Fragment 中会输出当前节点中执行的所有节点信息,当一次查询涉及的序列过多时,每个节点都被输出,会导致 Explain Analyze 返回的结果集过大,因此当相同类型的节点超过 10 个时,系统会自动合并当前 Fragment 下所有相同类型的节点,合并后统计信息也被累积,对于一些无法合并的定制信息会直接丢弃(如下图)。
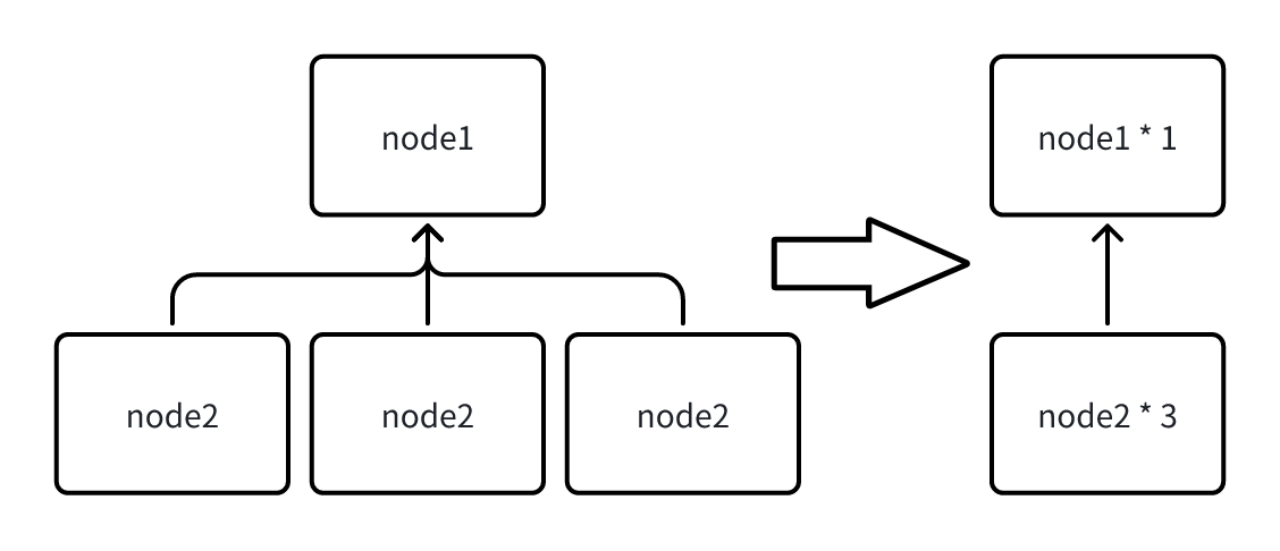
用户也可以自行修改 iotdb-system.properties 中的配置项merge_threshold_of_explain_analyze来设置触发合并的节点阈值,该参数支持热加载。
- 查询超时场景使用 Explain Analyze 语句
Explain Analyze 本身是一种特殊的查询,当执行超时的时候,无法使用Explain Analyze语句进行分析。为了在查询超时的情况下也可以通过分析结果排查超时原因,Explain Analyze还提供了定时日志机制(无需用户配置),每经过一定的时间间隔会将 Explain Analyze 的当前结果以文本的形式输出到专门的日志中。当查询超时时,用户可以前往logs/log_explain_analyze.log中查看对应的日志进行排查。
日志的时间间隔基于查询的超时时间进行计算,可以保证在超时的情况下至少会有两次的结果记录。
示例
下面是Explain Analyze的一个例子:
# 插入数据
insert into root.explain.analyze.data(timestamp, column1, column2, column3) values(1710494762, "hello", "explain", "analyze")
insert into root.explain.analyze.data(timestamp, column1, column2, column3) values(1710494862, "hello2", "explain2", "analyze2")
insert into root.explain.analyze.data(timestamp, column1, column2, column3) values(1710494962, "hello3", "explain3", "analyze3")
# 执行explain analyze语句
explain analyze select column2 from root.explain.analyze.data order by column1得到输出如下:
+-------------------------------------------------------------------------------------------------+
| Explain Analyze|
+-------------------------------------------------------------------------------------------------+
|Analyze Cost: 1.739 ms |
|Fetch Partition Cost: 0.940 ms |
|Fetch Schema Cost: 0.066 ms |
|Logical Plan Cost: 0.000 ms |
|Logical Optimization Cost: 0.000 ms |
|Distribution Plan Cost: 0.000 ms |
|Fragment Instances Count: 1 |
| |
|FRAGMENT-INSTANCE[Id: 20240315_115800_00030_1.2.0][IP: 127.0.0.1][DataRegion: 4][State: FINISHED]|
| Total Wall Time: 25 ms |
| Cost of initDataQuerySource: 0.175 ms |
| Seq File(unclosed): 0, Seq File(closed): 1 |
| UnSeq File(unclosed): 0, UnSeq File(closed): 0 |
| ready queued time: 0.280 ms, blocked queued time: 2.456 ms |
| [PlanNodeId 10]: IdentitySinkNode(IdentitySinkOperator) |
| CPU Time: 0.780 ms |
| output: 1 rows |
| HasNext() Called Count: 3 |
| Next() Called Count: 2 |
| Estimated Memory Size: : 1245184 |
| [PlanNodeId 5]: TransformNode(TransformOperator) |
| CPU Time: 0.764 ms |
| output: 1 rows |
| HasNext() Called Count: 3 |
| Next() Called Count: 2 |
| Estimated Memory Size: : 1245184 |
| [PlanNodeId 4]: SortNode(SortOperator) |
| CPU Time: 0.721 ms |
| output: 1 rows |
| HasNext() Called Count: 3 |
| Next() Called Count: 2 |
| sortCost/ns: 1125 |
| sortedDataSize: 272 |
| prepareCost/ns: 610834 |
| [PlanNodeId 3]: FullOuterTimeJoinNode(FullOuterTimeJoinOperator) |
| CPU Time: 0.706 ms |
| output: 1 rows |
| HasNext() Called Count: 5 |
| Next() Called Count: 1 |
| [PlanNodeId 7]: SeriesScanNode(SeriesScanOperator) |
| CPU Time: 1.085 ms |
| output: 1 rows |
| HasNext() Called Count: 2 |
| Next() Called Count: 1 |
| SeriesPath: root.explain.analyze.data.column2 |
| [PlanNodeId 8]: SeriesScanNode(SeriesScanOperator) |
| CPU Time: 1.091 ms |
| output: 1 rows |
| HasNext() Called Count: 2 |
| Next() Called Count: 1 |
| SeriesPath: root.explain.analyze.data.column1 |
+-------------------------------------------------------------------------------------------------+触发合并后的部分结果示例如下:
Analyze Cost: 143.679 ms
Fetch Partition Cost: 22.023 ms
Fetch Schema Cost: 63.086 ms
Logical Plan Cost: 0.000 ms
Logical Optimization Cost: 0.000 ms
Distribution Plan Cost: 0.000 ms
Fragment Instances Count: 2
FRAGMENT-INSTANCE[Id: 20240311_041502_00001_1.2.0][IP: 192.168.130.9][DataRegion: 14]
Total Wall Time: 39964 ms
Cost of initDataQuerySource: 1.834 ms
Seq File(unclosed): 0, Seq File(closed): 3
UnSeq File(unclosed): 0, UnSeq File(closed): 0
ready queued time: 504.334 ms, blocked queued time: 25356.419 ms
[PlanNodeId 20793]: IdentitySinkNode(IdentitySinkOperator) Count: * 1
CPU Time: 24440.724 ms
input: 71216 rows
HasNext() Called Count: 35963
Next() Called Count: 35962
Estimated Memory Size: : 33882112
[PlanNodeId 10385]: FullOuterTimeJoinNode(FullOuterTimeJoinOperator) Count: * 8
CPU Time: 41437.708 ms
input: 243011 rows
HasNext() Called Count: 41965
Next() Called Count: 41958
Estimated Memory Size: : 33882112
[PlanNodeId 11569]: SeriesScanNode(SeriesScanOperator) Count: * 1340
CPU Time: 1397.822 ms
input: 134000 rows
HasNext() Called Count: 2353
Next() Called Count: 1340
Estimated Memory Size: : 32833536
[PlanNodeId 20778]: ExchangeNode(ExchangeOperator) Count: * 7
CPU Time: 109.245 ms
input: 71891 rows
HasNext() Called Count: 1431
Next() Called Count: 1431
FRAGMENT-INSTANCE[Id: 20240311_041502_00001_1.3.0][IP: 192.168.130.9][DataRegion: 11]
Total Wall Time: 39912 ms
Cost of initDataQuerySource: 15.439 ms
Seq File(unclosed): 0, Seq File(closed): 2
UnSeq File(unclosed): 0, UnSeq File(closed): 0
ready queued time: 152.988 ms, blocked queued time: 37775.356 ms
[PlanNodeId 20786]: IdentitySinkNode(IdentitySinkOperator) Count: * 1
CPU Time: 2020.258 ms
input: 48800 rows
HasNext() Called Count: 978
Next() Called Count: 978
Estimated Memory Size: : 42336256
[PlanNodeId 20771]: FullOuterTimeJoinNode(FullOuterTimeJoinOperator) Count: * 8
CPU Time: 5255.307 ms
input: 195800 rows
HasNext() Called Count: 2455
Next() Called Count: 2448
Estimated Memory Size: : 42336256
[PlanNodeId 11867]: SeriesScanNode(SeriesScanOperator) Count: * 1680
CPU Time: 1248.080 ms
input: 168000 rows
HasNext() Called Count: 3198
Next() Called Count: 1680
Estimated Memory Size: : 41287680
......常见问题
WALL TIME(墙上时间)和 CPU TIME(CPU时间)的区别?
CPU 时间也称为处理器时间或处理器使用时间,指的是程序在执行过程中实际占用 CPU 进行计算的时间,显示的是程序实际消耗的处理器资源。
墙上时间也称为实际时间或物理时间,指的是从程序开始执行到程序结束的总时间,包括了所有等待时间。
- WALL TIME < CPU TIME 的场景:比如一个查询分片最后被调度器使用两个线程并行执行,真实物理世界上是 10s 过去了,但两个线程,可能一直占了两个 cpu 核跑了 10s,那 cpu time 就是 20s,wall time就是 10s
- WALL TIME > CPU TIME 的场景:因为系统内可能会存在多个查询并行执行,但查询的执行线程数和内存是固定的,
- 所以当查询分片被某些资源阻塞住时(比如没有足够的内存进行数据传输、或等待上游数据)就会放入Blocked Queue,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
- 或者当查询线程资源不足时,比如当前共有16个查询线程,但系统内并发有20个查询分片,即使所有查询都没有被阻塞,也只会同时并行运行16个查询分片,另外四个会被放入 READY QUEUE,等待被调度执行,此时查询分片并不会占用 CPU TIME,但WALL TIME(真实物理时间的时间)是在向前流逝的
Explain Analyze 是否有额外开销,测出的耗时是否与查询真实执行时有差别?
几乎没有,因为 explain analyze operator 是单独的线程执行,收集原查询的统计信息,且这些统计信息,即使不explain analyze,原来的查询也会生成,只是没有人去取。并且 explain analyze 是纯 next 遍历结果集,不会打印,所以与原来查询真实执行时的耗时不会有显著差别。
IO 耗时主要关注几个指标?
可能涉及 IO 耗时的主要有个指标,loadTimeSeriesMetadataDiskSeqTime, loadTimeSeriesMetadataDiskUnSeqTime 以及 construct[NonAligned/Aligned]ChunkReadersDiskTime
TimeSeriesMetadata 的加载分别统计了顺序和乱序文件,但 Chunk 的读取暂时未分开统计,但顺乱序比例可以通过TimeseriesMetadata 顺乱序的比例计算出来。
乱序数据对查询性能的影响能否有一些指标展示出来?
乱序数据产生的影响主要有两个:
- 需要在内存中多做一个归并排序(一般认为这个耗时是比较短的,毕竟是纯内存的 cpu 操作)
- 乱序数据会产生数据块间的时间范围重叠,导致统计信息无法使用
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
- 一般用户的查询都是只包含时间过滤条件,则不会有影响
- 无法利用统计信息直接计算出聚合值,无需读取数据
- 无法利用统计信息直接 skip 掉整个不满足值过滤要求的 chunk
单独对于乱序数据的性能影响,目前并没有有效的观测手段,除非就是在有乱序数据的时候,执行一遍查询耗时,然后等乱序合完了,再执行一遍,才能对比出来。
因为即使乱序这部分数据进了顺序,也是需要 IO、加压缩、decode,这个耗时少不了,不会因为乱序数据被合并进乱序了,就减少了。
执行 explain analyze 时,查询超时后,为什么结果没有输出在 log_explain_analyze.log 中?
升级时,只替换了 lib 包,没有替换 conf/logback-datanode.xml,需要替换一下 conf/logback-datanode.xml,然后不需要重启(该文件内容可以被热加载),大约等待 1 分钟后,重新执行 explain analyze verbose。
实战案例
案例一:查询涉及文件数量过多,磁盘IO成为瓶颈,导致查询速度变慢
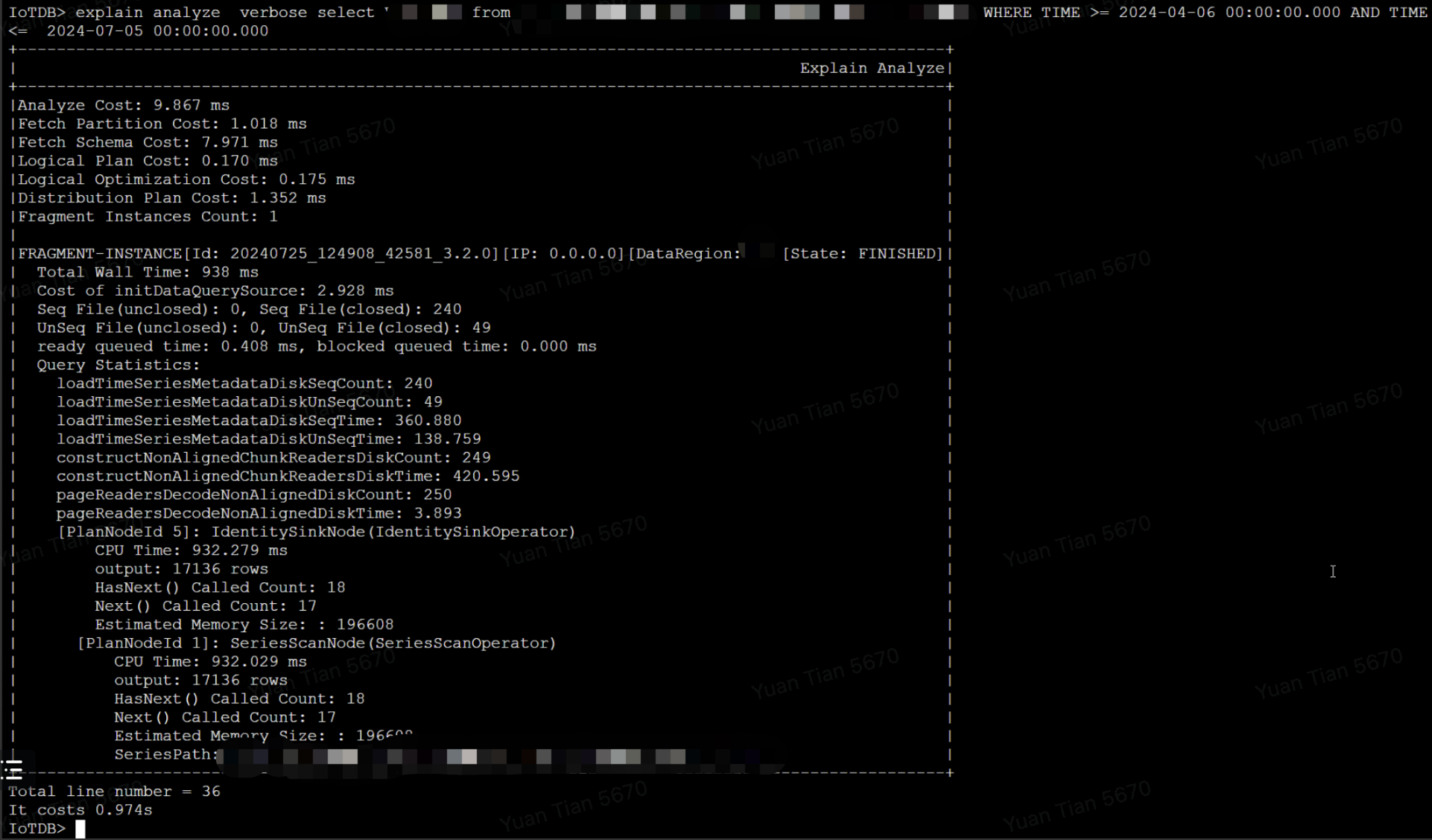
查询总耗时为 938 ms,其中从文件中读取索引区和数据区的耗时占据 918 ms,涉及了总共 289 个文件,假设查询涉及 N 个 TsFile,磁盘单次 seek 耗时为 t_seek,读取文件尾部索引的耗时为 t_index,读取文件的数据块的耗时为 t_chunk,则首次查询(未命中缓存)的理论耗时为 cost = N * (t_seek + t_index + t_seek + t_chunk),按经验值,HDD 磁盘的一次 seek 耗时约为 5-10ms,所以查询涉及的文件数越多,查询延迟会越大。
最终优化方案为:
- 调整合并参数,降低文件数量
- 更换 HDD 为 SSD,降低磁盘单次 IO 的延迟
案例二:like 谓词执行慢导致查询超时
执行如下 sql 时,查询超时(默认超时时间为 60s)
select count(s1) as total from root.db.d1 where s1 like '%XXXXXXXX%'执行 explain analyze verbose 时,即使查询超时,也会每隔 15s,将阶段性的采集结果输出到 log_explain_analyze.log 中,从 log_explain_analyze.log 中得到最后两次的输出结果如下:
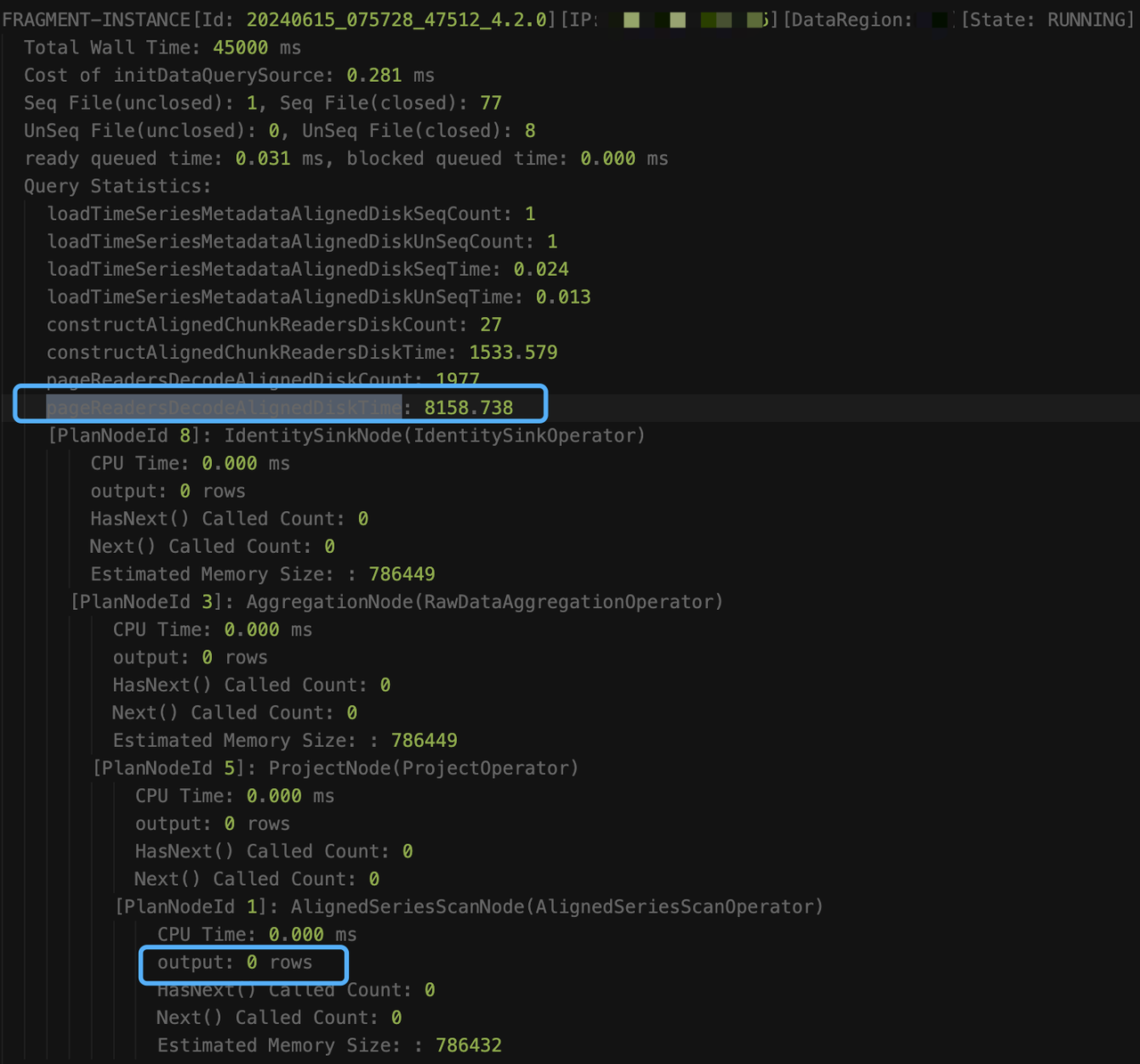
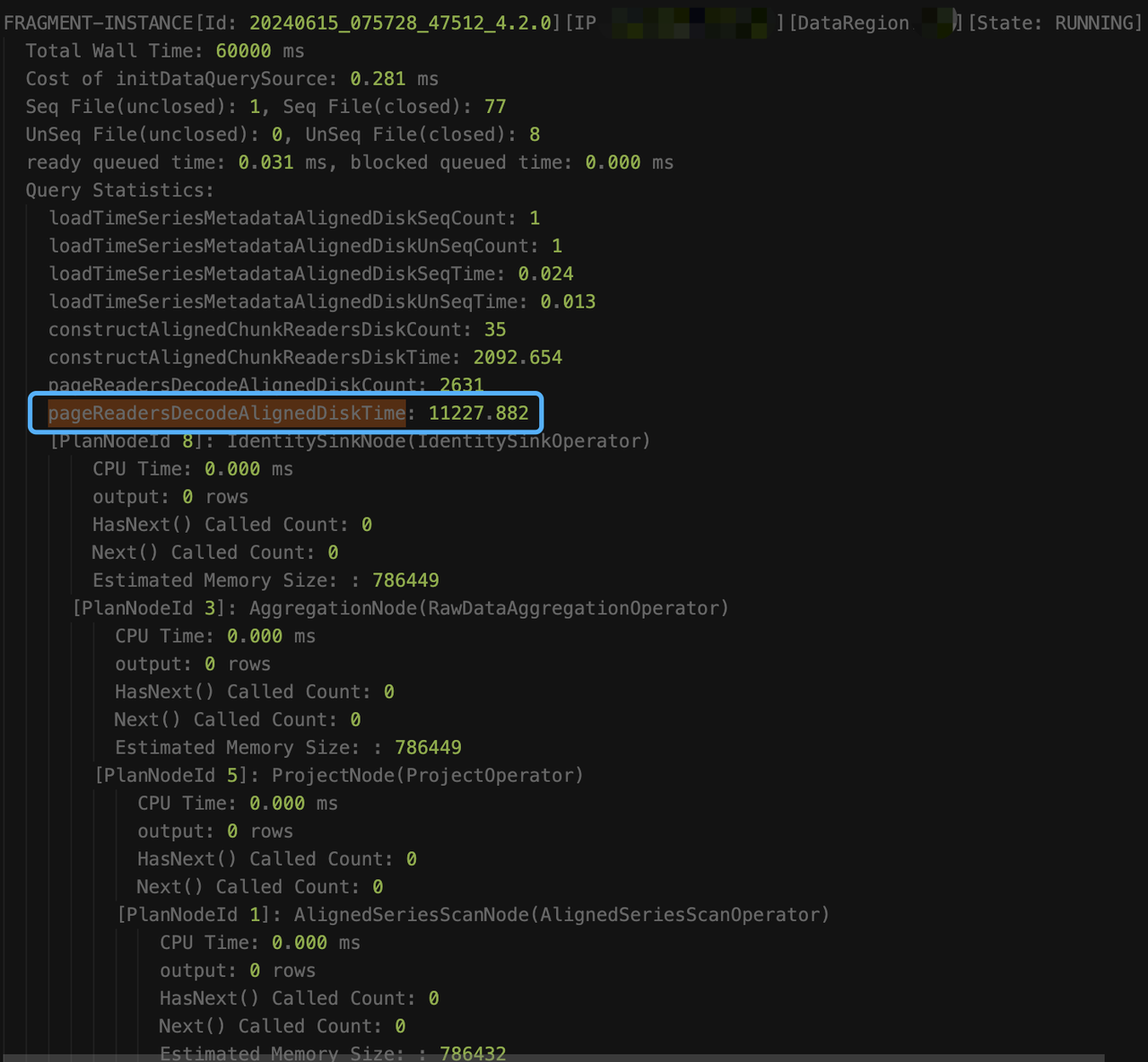
观察结果,我们发现是因为查询未加时间条件,涉及的数据太多 constructAlignedChunkReadersDiskTime 和 pageReadersDecodeAlignedDiskTime的耗时一直在涨,意味着一直在读新的 chunk。但 AlignedSeriesScanNode 的输出信息一直是 0,这是因为算子只有在输出至少一行满足条件的数据时,才会让出时间片,并更新信息。从总的读取耗时(loadTimeSeriesMetadataAlignedDiskSeqTime + loadTimeSeriesMetadataAlignedDiskUnSeqTime + constructAlignedChunkReadersDiskTime + pageReadersDecodeAlignedDiskTime=约13.4秒)来看,其他耗时(60s - 13.4 = 46.6)应该都是在执行过滤条件上(like 谓词的执行很耗时)。
最终优化方案为:增加时间过滤条件,避免全表扫描
region 迁移
region 迁移功能具有一定操作成本,建议完整阅读本节后再使用 region 迁移功能。如对方案设计有疑问请联系 IoTDB 团队寻求技术支持。
功能介绍
IoTDB 是一个分布式数据库,数据的均衡分布对集群的磁盘空间、写入压力的负载均衡有着重要作用,region 是数据在 IoTDB 集群中进行分布式存储的基本单元,具体概念可见region。
集群正常运行情况下,IoTDB 内核将会自动对数据进行负载均衡,但在集群新加入 DataNode 节点、DataNode 所在机器硬盘损坏需要恢复数据等场景下,会涉及到对 region 的手动迁移,以达到更精细化的调整集群负载的目标。
下面是一次region迁移过程的示意图:
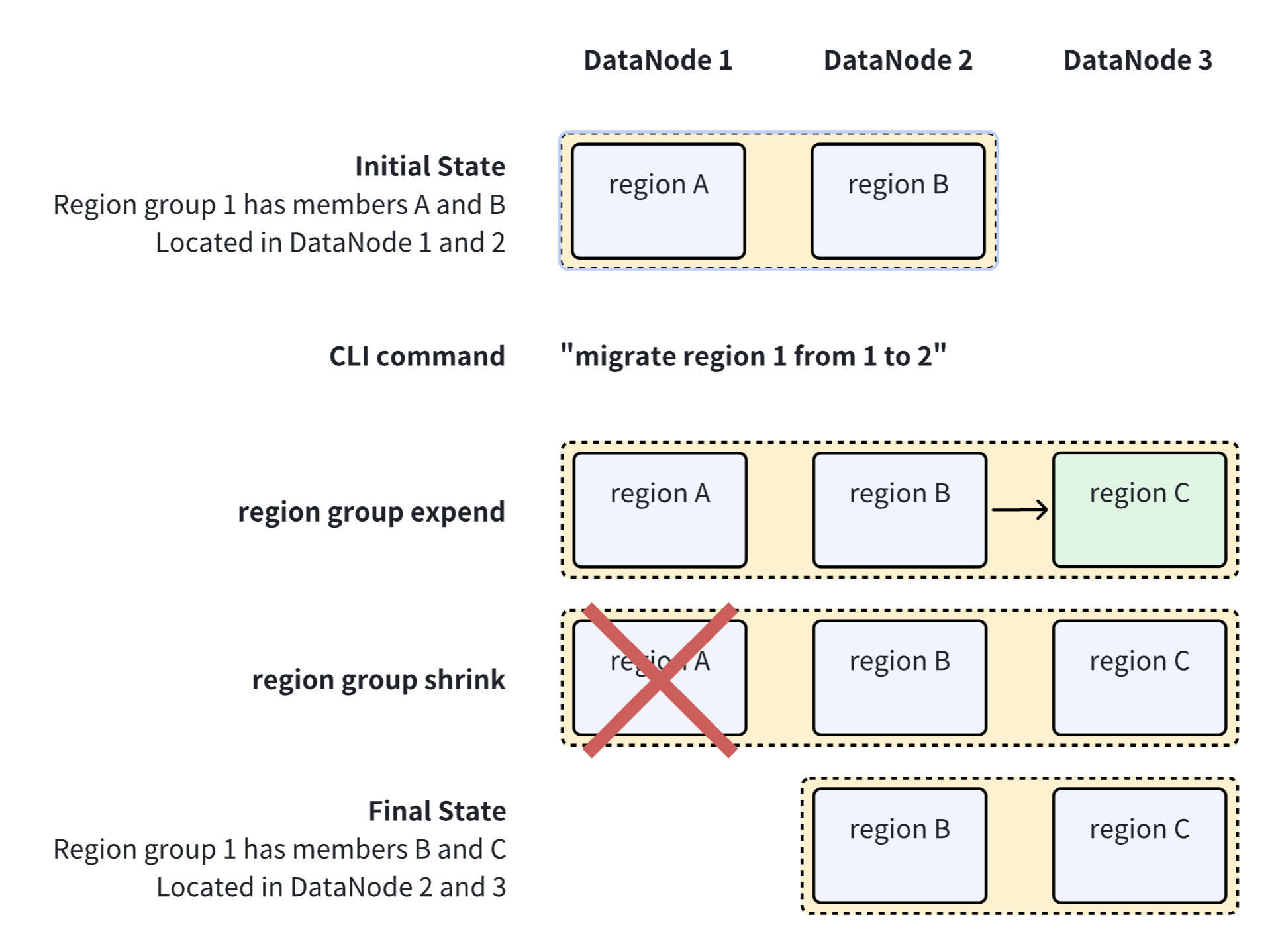
注意事项
- 仅支持在 IoTDB 1.3.3 以及更高版本使用 region 迁移功能。
- 目前支持 IoTConsensus、Ratis 协议。见 iotdb-system.properties 中的schema_region_consensus_protocol_class 和 data_region_consensus_protocol_class。
- region 迁移需要占用硬盘和网络带宽等系统资源,尽管过程不阻塞读取和写入,但可能影响读写速度。
- region 迁移过程会阻塞本共识组 WAL 文件的删除,如果 WAL 文件总量达到
wal_file_size_threshold_in_byte,则会阻塞写入。
使用说明
语法定义:
migrateRegion : MIGRATE REGION regionId=INTEGER_LITERAL FROM fromId=INTEGER_LITERAL TO toId=INTEGER_LITERAL ;含义:将 region 从一个 DataNode 迁移到另一个 DataNode。
示例:将 region 1 从 DataNode 2 迁移至 DataNode 3:
IoTDB> migrate region 1 from 2 to 3 Msg: The statement is executed successfully.“The statement is executed successfully” 仅代表region迁移任务提交成功,不代表执行完毕。任务执行情况通过 CLI 指令
show regions查看。相关配置项:
- 迁移速度控制:修改
iotdb-system.properties参数region_migration_speed_limit_bytes_per_second控制 region 迁移速度。
- 迁移速度控制:修改
耗时估算:
- 如果迁移过程无并发写入,那么耗时可以简单通过 region 数据量除以数据传输速度来估算。例如对于 1TB 的 region,硬盘网络带宽和限速参数共同决定数据传输速度是 100MB/s,那么需要约 3 小时完成迁移。
- 如果迁移过程有并发写入,那么耗时会有所上升,具体耗时取决于写入压力、系统资源等多方面因素,可简单按
无并发写入耗时×1.5来估算。
迁移进度观察:迁移过程中可通过 CLI 指令
show regions观察状态变化,以 2 副本为例,region 所在共识组的状态会经历如下过程:迁移开始前:
Running,Running。扩容阶段:
Running,Running,Adding。由于涉及到大量文件传输,可能耗时较长,具体进度在 DataNode 日志中搜索[SNAPSHOT TRANSMISSION]。缩容阶段:
Removing,Running,Running。迁移完成:
Running,Running。
以扩容阶段为例,
show regions的结果可能为:IoTDB> show regions +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ |RegionId| Type| Status|Database|SeriesSlotNum|TimeSlotNum|DataNodeId|RpcAddress|RpcPort|InternalAddress| Role| CreateTime| +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ | 0|SchemaRegion|Running| root.ln| 1| 0| 1| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 0|SchemaRegion|Running| root.ln| 1| 0| 2| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 0|SchemaRegion|Running| root.ln| 1| 0| 3| 0.0.0.0| 6668| 127.0.0.1| Leader|2024-04-15T18:55:17.691| | 1| DataRegion|Running| root.ln| 1| 1| 1| 0.0.0.0| 6667| 127.0.0.1| Leader|2024-04-15T18:55:19.457| | 1| DataRegion|Running| root.ln| 1| 1| 2| 0.0.0.0| 6668| 127.0.0.1|Follower|2024-04-15T18:55:19.457| | 1| DataRegion| Adding| root.ln| 1| 1| 3| 0.0.0.0| 6668| 127.0.0.1|Follower|2024-04-15T18:55:19.457| +--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+--------+-----------------------+ Total line number = 3 It costs 0.003s
Start/Stop Repair Data 语句
用于修复由于系统 bug 导致的乱序
START REPAIR DATA
启动一个数据修复任务,扫描创建修复任务的时间之前产生的 tsfile 文件并修复有乱序错误的文件。
IoTDB> START REPAIR DATA
IoTDB> START REPAIR DATA ON LOCAL
IoTDB> START REPAIR DATA ON CLUSTERSTOP REPAIR DATA
停止一个进行中的修复任务。如果需要再次恢复一个已停止的数据修复任务的进度,可以重新执行 START REPAIR DATA.
IoTDB> STOP REPAIR DATA
IoTDB> STOP REPAIR DATA ON LOCAL
IoTDB> STOP REPAIR DATA ON CLUSTER