
Data Sync
Data Sync
The IoTDB data sync transfers data from IoTDB to another data platform, and .
A Pipe consists of three subtasks (plugins):
- Extract
- Process
- Connect
Pipe allows users to customize the processing logic of these three subtasks, just like handling data using UDF (User-Defined Functions). Within a Pipe, the aforementioned subtasks are executed and implemented by three types of plugins. Data flows through these three plugins sequentially: Pipe Extractor is used to extract data, Pipe Processor is used to process data, and Pipe Connector is used to send data to an external system.
The model of a Pipe task is as follows:

It describes a data sync task, which essentially describes the attributes of the Pipe Extractor, Pipe Processor, and Pipe Connector plugins. Users can declaratively configure the specific attributes of the three subtasks through SQL statements. By combining different attributes, flexible data ETL (Extract, Transform, Load) capabilities can be achieved.
By utilizing the data sync functionality, a complete data pipeline can be built to fulfill various requirements such as edge-to-cloud sync, remote disaster recovery, and read-write workload distribution across multiple databases.
Quick Start
🎯 Goal: Achieve full data sync of IoTDB A -> IoTDB B
Start two IoTDBs,A(datanode -> 127.0.0.1:6667) B(datanode -> 127.0.0.1:6668)
create a Pipe from A -> B, and execute on A
create pipe a2b with connector ( 'connector'='iotdb-thrift-connector', 'connector.ip'='127.0.0.1', 'connector.port'='6668' )start a Pipe from A -> B, and execute on A
start pipe a2bWrite data to A
INSERT INTO root.db.d(time, m) values (1, 1)Checking data synchronised from A at B
SELECT ** FROM root
❗️Note: The current IoTDB -> IoTDB implementation of data sync does not support DDL sync
That is: ttl, trigger, alias, template, view, create/delete sequence, create/delete database, etc. are not supported.
IoTDB -> IoTDB data sync requires the target IoTDB:
- Enable automatic metadata creation: manual configuration of encoding and compression of data types to be consistent with the sender is required
- Do not enable automatic metadata creation: manually create metadata that is consistent with the source
Sync Task Management
Create a sync task
A data sync task can be created using the CREATE PIPE statement, a sample SQL statement is shown below:
CREATE PIPE <PipeId> -- PipeId is the name that uniquely identifies the sync task
WITH EXTRACTOR (
-- Default IoTDB Data Extraction Plugin
'extractor' = 'iotdb-extractor',
-- Path prefix, only data that can match the path prefix will be extracted for subsequent processing and delivery
'extractor.pattern' = 'root.timecho',
-- Whether to extract historical data
'extractor.history.enable' = 'true',
-- Describes the time range of the historical data being extracted, indicating the earliest possible time
'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
-- Describes the time range of the extracted historical data, indicating the latest time
'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
-- Whether to extract realtime data
'extractor.realtime.enable' = 'true',
)
WITH PROCESSOR (
-- Default data processing plugin, means no processing
'processor' = 'do-nothing-processor',
)
WITH CONNECTOR (
-- IoTDB data sending plugin with target IoTDB
'connector' = 'iotdb-thrift-connector',
-- Data service for one of the DataNode nodes on the target IoTDB ip
'connector.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
'connector.port' = '6667',
)To create a sync task it is necessary to configure the PipeId and the parameters of the three plugin sections:
| configuration item | description | Required or not | default implementation | Default implementation description | Whether to allow custom implementations |
|---|---|---|---|---|---|
| pipeId | Globally uniquely identifies the name of a sync task | - | - | - | |
| extractor | pipe Extractor plugin, for extracting synchronized data at the bottom of the database | Optional | iotdb-extractor | Integrate all historical data of the database and subsequent realtime data into the sync task | no |
| processor | Pipe Processor plugin, for processing data | Optional | do-nothing-processor | no processing of incoming data | |
| connector | Pipe Connector plugin,for sending data | - | - |
In the example, the iotdb-extractor, do-nothing-processor, and iotdb-thrift-connector plugins are used to build the data sync task. iotdb has other built-in data sync plugins, see the section "System Pre-built Data Sync Plugin".
An example of a minimalist CREATE PIPE statement is as follows:
CREATE PIPE <PipeId> -- PipeId is a name that uniquely identifies the task.
WITH CONNECTOR (
-- IoTDB data sending plugin with target IoTDB
'connector' = 'iotdb-thrift-connector',
-- Data service for one of the DataNode nodes on the target IoTDB ip
'connector.ip' = '127.0.0.1',
-- Data service port of one of the DataNode nodes of the target IoTDB
'connector.port' = '6667',
)The expressed semantics are: synchronise the full amount of historical data and subsequent arrivals of realtime data from this database instance to the IoTDB instance with target 127.0.0.1:6667.
Note:
EXTRACTOR and PROCESSOR are optional, if no configuration parameters are filled in, the system will use the corresponding default implementation.
The CONNECTOR is a mandatory configuration that needs to be declared in the CREATE PIPE statement for configuring purposes.
The CONNECTOR exhibits self-reusability. For different tasks, if their CONNECTOR possesses identical KV properties (where the value corresponds to every key), the system will ultimately create only one instance of the CONNECTOR to achieve resource reuse for connections.
- For example, there are the following pipe1, pipe2 task declarations:
CREATE PIPE pipe1 WITH CONNECTOR ( 'connector' = 'iotdb-thrift-connector', 'connector.thrift.host' = 'localhost', 'connector.thrift.port' = '9999', ) CREATE PIPE pipe2 WITH CONNECTOR ( 'connector' = 'iotdb-thrift-connector', 'connector.thrift.port' = '9999', 'connector.thrift.host' = 'localhost', )Since they have identical CONNECTOR declarations (even if the order of some properties is different), the framework will automatically reuse the CONNECTOR declared by them. Hence, the CONNECTOR instances for pipe1 and pipe2 will be the same.
When extractor is the default iotdb-extractor, and extractor.forwarding-pipe-requests is the default value true, please do not build an application scenario that involve data cycle sync (as it can result in an infinite loop):
IoTDB A -> IoTDB B -> IoTDB A
IoTDB A -> IoTDB A
START TASK
After the successful execution of the CREATE PIPE statement, task-related instances will be created. However, the overall task's running status will be set to STOPPED, meaning the task will not immediately process data.
You can use the START PIPE statement to begin processing data for a task:
START PIPE <PipeId>STOP TASK
the STOP PIPE statement can be used to halt the data processing:
STOP PIPE <PipeId>DELETE TASK
If a task is in the RUNNING state, you can use the DROP PIPE statement to stop the data processing and delete the entire task:
DROP PIPE <PipeId>Before deleting a task, there is no need to execute the STOP operation.
SHOW TASK
You can use the SHOW PIPES statement to view all tasks:
SHOW PIPESThe query results are as follows:
+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
| ID| CreationTime | State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...| ...| None|
+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...| ...| TException: ...|
+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+You can use <PipeId> to specify the status of a particular synchronization task:
SHOW PIPE <PipeId>Additionally, the WHERE clause can be used to determine if the Pipe Connector used by a specific <PipeId> is being reused.
SHOW PIPES
WHERE CONNECTOR USED BY <PipeId>Task Running Status Migration
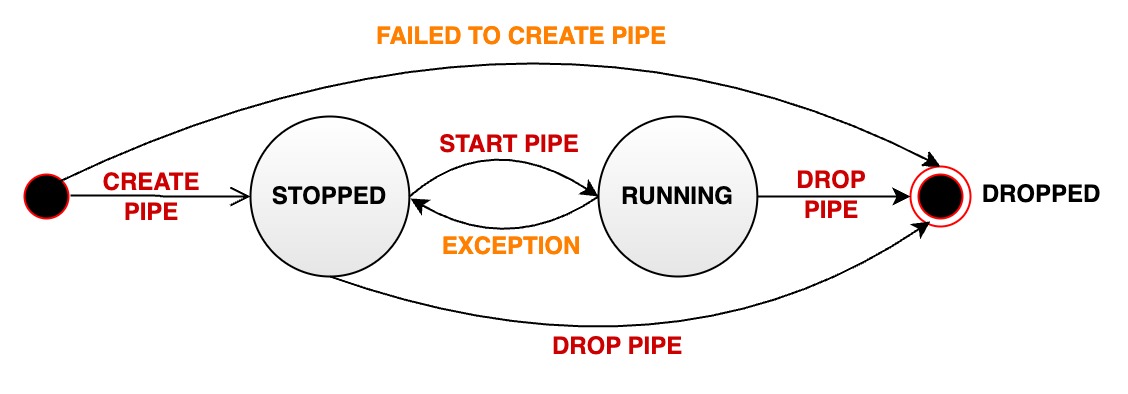
The task running status can transition through several states during the lifecycle of a data synchronization pipe:
- STOPPED: The pipe is in a stopped state. It can have the following possibilities:
- After the successful creation of a pipe, its initial state is set to stopped
- The user manually pauses a pipe that is in normal running state, transitioning its status from RUNNING to STOPPED
- If a pipe encounters an unrecoverable error during execution, its status automatically changes from RUNNING to STOPPED.
- RUNNING: The pipe is actively processing data
- DROPPED: The pipe is permanently deleted
The following diagram illustrates the different states and their transitions:
System Pre-built Data Sync Plugin
View pre-built plugin
User can view the plugins in the system on demand. The statement for viewing plugins is shown below.
SHOW PIPEPLUGINSPre-built Extractor Plugin
iotdb-extractor
Function: Extract historical or realtime data inside IoTDB into pipe.
| key | value | value range | required or optional with default |
|---|---|---|---|
| extractor | iotdb-extractor | String: iotdb-extractor | required |
| extractor.pattern | path prefix for filtering time series | String: any time series prefix | optional: root |
| extractor.history.enable | whether to synchronize historical data | Boolean: true, false | optional: true |
| extractor.history.start-time | start of synchronizing historical data event time,Include start-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
| extractor.history.end-time | end of synchronizing historical data event time,Include end-time | Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
| extractor.realtime.enable | Whether to sync realtime data | Boolean: true, false | optional: true |
| extractor.realtime.mode | Extraction pattern for realtime data | String: hybrid, log, file | optional: hybrid |
| extractor.forwarding-pipe-requests | Whether or not to forward data written by another Pipe (usually Data Sync) | Boolean: true, false | optional: true |
🚫 extractor.pattern Parameter Description
Pattern should use backquotes to modify illegal characters or illegal path nodes, for example, if you want to filter root.`a@b` or root.`123`, you should set the pattern to root.`a@b` or root.`123`(Refer specifically to Timing of single and double quotes and backquotes)
In the underlying implementation, when pattern is detected as root (default value), synchronization efficiency is higher, and any other format will reduce performance.
The path prefix does not need to form a complete path. For example, when creating a pipe with the parameter 'extractor.pattern'='root.aligned.1':
- root.aligned.1TS
- root.aligned.1TS.`1`
- root.aligned.100TS
the data will be synchronized;
- root.aligned.`1`
- root.aligned.`123`
the data will not be synchronized.
❗️start-time, end-time parameter description of extractor.history
- start-time, end-time should be in ISO format, such as 2011-12-03T10:15:30 or 2011-12-03T10:15:30+01:00
✅ a piece of data from production to IoTDB contains two key concepts of time
- event time: the time when the data is actually produced (or the generation time assigned to the data by the data production system, which is a time item in the data point), also called the event time.
- arrival time: the time the data arrived in the IoTDB system.
The out-of-order data we often refer to refers to data whose event time is far behind the current system time (or the maximum event time that has been dropped) when the data arrives. On the other hand, whether it is out-of-order data or sequential data, as long as they arrive newly in the system, their arrival time will increase with the order in which the data arrives at IoTDB.
💎 the work of iotdb-extractor can be split into two stages
- Historical data extraction: All data with arrival time < current system time when creating the pipe is called historical data
- Realtime data extraction: All data with arrival time >= current system time when the pipe is created is called realtime data
The historical data transmission phase and the realtime data transmission phase are executed serially. Only when the historical data transmission phase is completed, the realtime data transmission phase is executed.**
Users can specify iotdb-extractor to:
- Historical data extraction(
'extractor.history.enable' = 'true','extractor.realtime.enable' = 'false')- Realtime data extraction(
'extractor.history.enable' = 'false','extractor.realtime.enable' = 'true')- Full data extraction(
'extractor.history.enable' = 'true','extractor.realtime.enable' = 'true')- Disable simultaneous sets
extractor.history.enableandextractor.realtime.enabletofalse📌 extractor.realtime.mode: mode in which data is extracted
log: in this mode, the task uses only operation logs for data processing and sending.
file: in this mode, the task uses only data files for data processing and sending.
hybrid: This mode takes into account the characteristics of low latency but low throughput when sending data item by item according to the operation log and high throughput but high latency when sending data in batches according to the data file, and is able to automatically switch to a suitable data extraction method under different write loads. When data backlog is generated, it automatically switches to data file-based data extraction to ensure high sending throughput, and when the backlog is eliminated, it automatically switches back to operation log-based data extraction, which avoids the problem that it is difficult to balance the data sending latency or throughput by using a single data extraction algorithm.
🍕 extractor.forwarding-pipe-requests: whether to allow forwarding of data transferred from another pipe.If pipe is to be used to build A -> B -> C data sync, then the pipe of B -> C needs to have this parameter set to true for the data written from A -> B to B via the pipe to be forwarded to C correctly.
If you want to use pipe to build a bi-directional data sync between A <-> B, then the pipe for A -> B and B -> A need to be set to false, otherwise it will result in an endless loop of data being forwarded between clusters.
Pre-built Processor Plugin
do-nothing-processor
Function: Do not do anything with the events passed in by the extractor.
| key | value | value range | required or optional with default |
|---|---|---|---|
| processor | do-nothing-processor | String: do-nothing-processor | required |
pre-connector plugin
iotdb-thrift-sync-connector(alias:iotdb-thrift-connector)
Function: Primarily used for data transfer between IoTDB instances (v1.2.0+). Data is transmitted using the Thrift RPC framework and a single-threaded blocking IO model. It guarantees that the receiving end applies the data in the same order as the sending end receives the write requests.
Limitation: Both the source and target IoTDB versions need to be v1.2.0+.
| key | value | value range | required or optional with default |
|---|---|---|---|
| connector | iotdb-thrift-connector or iotdb-thrift-sync-connector | String: iotdb-thrift-connector or iotdb-thrift-sync-connector | required |
| connector.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and connector.node-urls fill in either one |
| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and connector.node-urls fill in either one |
| connector.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String。eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and connector.ip:connector.port fill in either one |
| connector.batch.enable | Whether to enable log accumulation and batch sending mode to improve transmission throughput and reduce IOPS | Boolean: true, false | optional: true |
| connector.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | optional: 1 |
| connector.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | optional: 16 * 1024 * 1024 (16MiB) |
📌 Make sure that the receiver has created all the time series on the sender side, or that automatic metadata creation is turned on, otherwise the pipe run will fail.
iotdb-thrift-async-connector
Function: Primarily used for data transfer between IoTDB instances (v1.2.0+).
Data is transmitted using the Thrift RPC framework, employing a multi-threaded async non-blocking IO model, resulting in high transfer performance. It is particularly suitable for distributed scenarios on the target end.
It does not guarantee that the receiving end applies the data in the same order as the sending end receives the write requests, but it guarantees data integrity (at-least-once).
Limitation: Both the source and target IoTDB versions need to be v1.2.0+.
| key | value | value range | required or optional with default |
|---|---|---|---|
| connector | iotdb-thrift-async-connector | String: iotdb-thrift-async-connector | required |
| connector.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and connector.node-urls fill in either one |
| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and connector.node-urls fill in either one |
| connector.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String。eg: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: and connector.ip:connector.port fill in either one |
| connector.batch.enable | Whether to enable the log saving wholesale delivery mode, which is used to improve transmission throughput and reduce IOPS | Boolean: true, false | optional: true |
| connector.batch.max-delay-seconds | Effective when the log save and send mode is turned on, indicates the longest time a batch of data waits before being sent (unit: s) | Integer | optional: 1 |
| connector.batch.size-bytes | Effective when log saving and delivery mode is enabled, indicates the maximum saving size of a batch of data (unit: byte) | Long | optional: 16 * 1024 * 1024 (16MiB) |
📌 Please ensure that the receiving end has already created all the time series present in the sending end or has enabled automatic metadata creation. Otherwise, it may result in the failure of the pipe operation.
iotdb-legacy-pipe-connector
Function: Mainly used to transfer data from IoTDB (v1.2.0+) to lower versions of IoTDB, using the data synchronization (Sync) protocol before version v1.2.0.
Data is transmitted using the Thrift RPC framework. It employs a single-threaded sync blocking IO model, resulting in weak transfer performance.
Limitation: The source IoTDB version needs to be v1.2.0+. The target IoTDB version can be either v1.2.0+, v1.1.x (lower versions of IoTDB are theoretically supported but untested).
Note: In theory, any version prior to v1.2.0 of IoTDB can serve as the data synchronization (Sync) receiver for v1.2.0+.
| key | value | value range | required or optional with default |
|---|---|---|---|
| connector | iotdb-legacy-pipe-connector | string: iotdb-legacy-pipe-connector | required |
| connector.ip | data service of one DataNode node of the target IoTDB ip | string | required |
| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | integer | required |
| connector.user | the user name of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
| connector.password | the password of the target IoTDB. Note that the user needs to support data writing and TsFile Load permissions. | string | optional: root |
| connector.version | the version of the target IoTDB, used to disguise its actual version and bypass the version consistency check of the target. | string | optional: 1.1 |
📌 Make sure that the receiver has created all the time series on the sender side, or that automatic metadata creation is turned on, otherwise the pipe run will fail.
iotdb-air-gap-connector
Function: Used for data sync from IoTDB (v1.2.2+) to IoTDB (v1.2.2+) across one-way data gatekeepers. Supported gatekeeper models include NARI Syskeeper 2000, etc.
This Connector uses Java's own Socket to implement data transmission, a single-thread blocking IO model, and its performance is comparable to iotdb-thrift-sync-connector.
Ensure that the order in which the receiving end applies data is consistent with the order in which the sending end accepts write requests.
Scenario: For example, in the specification of power systems
Applications between Zone I/II and Zone III are prohibited from using SQL commands to access the database and bidirectional data transmission based on B/S mode.
For data communication between Zone I/II and Zone III, the transmission end is initiated by the intranet. The reverse response message is not allowed to carry data. The response message of the application layer is at most 1 byte and 1 word. The section has two states: all 0s or all 1s.
limit:
- Both the source IoTDB and target IoTDB versions need to be v1.2.2+.
- The one-way data gatekeeper needs to allow TCP requests to cross, and each request can return a byte of all 1s or all 0s.
- The target IoTDB needs to be configured in iotdb-common.properties
a. pipe_air_gap_receiver_enabled=true
b. pipe_air_gap_receiver_port configures the receiving port of the receiver
| key | value | value range | required or optional with default |
|---|---|---|---|
| connector | iotdb-air-gap-connector | String: iotdb-air-gap-connector | required |
| connector.ip | the data service IP of one of the DataNode nodes in the target IoTDB | String | optional: and connector.node-urls fill in either one |
| connector.port | the data service port of one of the DataNode nodes in the target IoTDB | Integer | optional: and connector.node-urls fill in either one |
| connector.node-urls | the URL of the data service port of any multiple DataNode nodes in the target IoTDB | String. eg:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | optional: 与 connector.ip:connector.port fill in either one |
| connector.air-gap.handshake-timeout-ms | The timeout period for the handshake request when the source and target try to establish a connection for the first time, unit: milliseconds | Integer | optional: 5000 |
📌 Make sure that the receiver has created all the time series on the sender side or that automatic metadata creation is turned on, otherwise the pipe run will fail.
do-nothing-connector
Function: Does not do anything with the events passed in by the processor.
| key | value | value range | required or optional with default |
|---|---|---|---|
| connector | do-nothing-connector | String: do-nothing-connector | required |
Authority Management
| Authority Name | Description |
|---|---|
| CREATE_PIPE | Register task,path-independent |
| START_PIPE | Start task,path-independent |
| STOP_PIPE | Stop task,path-independent |
| DROP_PIPE | Uninstall task,path-independent |
| SHOW_PIPES | Query task,path-independent |
Configure Parameters
In iotdb-common.properties :
####################
### Pipe Configuration
####################
# Uncomment the following field to configure the pipe lib directory.
# For Windows platform
# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
# absolute. Otherwise, it is relative.
# pipe_lib_dir=ext\\pipe
# For Linux platform
# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
# pipe_lib_dir=ext/pipe
# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
# pipe_subtask_executor_max_thread_num=5
# The connection timeout (in milliseconds) for the thrift client.
# pipe_connector_timeout_ms=900000
# The maximum number of selectors that can be used in the async connector.
# pipe_async_connector_selector_number=1
# The core number of clients that can be used in the async connector.
# pipe_async_connector_core_client_number=8
# The maximum number of clients that can be used in the async connector.
# pipe_async_connector_max_client_number=16
# Whether to enable receiving pipe data through air gap.
# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
# pipe_air_gap_receiver_enabled=false
# The port for the server to receive pipe data through air gap.
# pipe_air_gap_receiver_port=9780Functionality Features
At least one semantic guarantee at-least-once
The data synchronization feature provides an at-least-once delivery semantic when transferring data to external systems. In most scenarios, the synchronization feature guarantees exactly-once delivery, ensuring that all data is synchronized exactly once.
However, in the following scenarios, it is possible for some data to be synchronized multiple times (due to resumable transmission):
- Temporary network failures: If a data transmission request fails, the system will retry sending it until reaching the maximum retry attempts.
- Abnormal implementation of the Pipe plugin logic: If an error is thrown during the plugin's execution, the system will retry sending the data until reaching the maximum retry attempts.
- Data partition switching due to node failures or restarts: After the partition change is completed, the affected data will be retransmitted.
- Cluster unavailability: Once the cluster becomes available again, the affected data will be retransmitted.
Source: Data Writing with Pipe Processing and Asynchronous Decoupling of Data Transmission
In the data sync feature, data transfer adopts an asynchronous replication mode.
Data sync is completely decoupled from the writing operation, eliminating any impact on the critical path of writing. This mechanism allows the framework to maintain the writing speed of a time-series database while ensuring continuous data sync.
Source: Adaptive data transfer policy for data write load.
Support to dynamically adjust the data transfer mode according to the writing load. Sync default is to use TsFile and operation stream dynamic hybrid transfer ('extractor.realtime.mode'='hybrid'), when the data writing load is high, TsFile transfer is preferred.
When the data writing load is high, TsFile transfer is preferred, which has a high compression ratio and saves network bandwidth.
When the load of data writing is low, the preferred method is operation stream synchronous transfer. The operation stream transfer has high real-time performance.
Source: High Availability of Pipe Service in a Highly Available Cluster Deployment
When the sender end IoTDB is deployed in a high availability cluster mode, the data sync service will also be highly available. The data sync framework monitors the data sync progress of each data node and periodically takes lightweight distributed consistent snapshots to preserve the sync state.
- In the event of a failure of a data node in the sender cluster, the data sync framework can leverage the consistent snapshot and the data stored in replicas to quickly recover and resume sync, thus achieving high availability of the data sync service.
- In the event of a complete failure and restart of the sender cluster, the data sync framework can also use snapshots to recover the sync service.