
Query Data
Query Data
1. OVERVIEW
1.1 Syntax Definition
In IoTDB, SELECT statement is used to retrieve data from one or more selected time series. Here is the syntax definition of SELECT statement:
SELECT [LAST] selectExpr [, selectExpr] ...
[INTO intoItem [, intoItem] ...]
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY {
([startTime, endTime), interval [, slidingStep]) |
LEVEL = levelNum [, levelNum] ... |
TAGS(tagKey [, tagKey] ... ) |
VARIATION(expression[,delta][,ignoreNull=true/false]) |
CONDITION(expression,[keep>/>=/=/</<=]threshold[,ignoreNull=true/false]) |
SESSION(timeInterval) |
COUNT(expression, size[,ignoreNull=true/false])
}]
[HAVING havingCondition]
[ORDER BY sortKey {ASC | DESC}]
[FILL ({PREVIOUS | LINEAR | constant}) (, interval=DURATION_LITERAL)?)]
[SLIMIT seriesLimit] [SOFFSET seriesOffset]
[LIMIT rowLimit] [OFFSET rowOffset]
[ALIGN BY {TIME | DEVICE}]1.2 Syntax Description
SELECT clause
- The
SELECTclause specifies the output of the query, consisting of severalselectExpr. - Each
selectExprdefines one or more columns in the query result, which is an expression consisting of time series path suffixes, constants, functions, and operators. - Supports using
ASto specify aliases for columns in the query result set. - Use the
LASTkeyword in theSELECTclause to specify that the query is the last query.
INTO clause
SELECT INTOis used to write query results into a series of specified time series. TheINTOclause specifies the target time series to which query results are written.
FROM clause
- The
FROMclause contains the path prefix of one or more time series to be queried, and wildcards are supported. - When executing a query, the path prefix in the
FROMclause and the suffix in theSELECTclause will be concatenated to obtain a complete query target time series.
WHERE clause
- The
WHEREclause specifies the filtering conditions for data rows, consisting of awhereCondition. whereConditionis a logical expression that evaluates to true for each row to be selected. If there is noWHEREclause, all rows will be selected.- In
whereCondition, any IOTDB-supported functions and operators can be used except aggregate functions.
GROUP BY clause
- The
GROUP BYclause specifies how the time series are aggregated by segment or group. - Segmented aggregation refers to segmenting data in the row direction according to the time dimension, aiming at the time relationship between different data points in the same time series, and obtaining an aggregated value for each segment. Currently only group by time、group by variation、group by condition、group by session and group by count is supported, and more segmentation methods will be supported in the future.
- Group aggregation refers to grouping the potential business attributes of time series for different time series. Each group contains several time series, and each group gets an aggregated value. Support group by path level and group by tag two grouping methods.
- Segment aggregation and group aggregation can be mixed.
HAVING clause
- The
HAVINGclause specifies the filter conditions for the aggregation results, consisting of ahavingCondition. havingConditionis a logical expression that evaluates to true for the aggregation results to be selected. If there is noHAVINGclause, all aggregated results will be selected.HAVINGis to be used with aggregate functions and theGROUP BYclause.
ORDER BY clause
- The
ORDER BYclause is used to specify how the result set is sorted. - In ALIGN BY TIME mode: By default, they are sorted in ascending order of timestamp size, and
ORDER BY TIME DESCcan be used to specify that the result set is sorted in descending order of timestamp. - In ALIGN BY DEVICE mode: arrange according to the device first, and sort each device in ascending order according to the timestamp. The ordering and priority can be adjusted by
ORDER BYclause.
FILL clause
- The
FILLclause is used to specify the filling mode in the case of missing data, allowing users to fill in empty values for the result set of any query according to a specific method.
SLIMIT and SOFFSET clauses
SLIMITspecifies the number of columns of the query result, andSOFFSETspecifies the starting column position of the query result display.SLIMITandSOFFSETare only used to control value columns and have no effect on time and device columns.
LIMIT and OFFSET clauses
LIMITspecifies the number of rows of the query result, andOFFSETspecifies the starting row position of the query result display.
ALIGN BY clause
- The query result set is ALIGN BY TIME by default, including a time column and several value columns, and the timestamps of each column of data in each row are the same.
- It also supports ALIGN BY DEVICE. The query result set contains a time column, a device column, and several value columns.
1.3 Basic Examples
Select a Column of Data Based on a Time Interval
The SQL statement is:
select temperature from root.ln.wf01.wt01 where time < 2017-11-01T00:08:00.000which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is the temperature sensor (temperature). The SQL statement requires that all temperature sensor values before the time point of "2017-11-01T00:08:00.000" be selected.
The execution result of this SQL statement is as follows:
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|2017-11-01T00:00:00.000+08:00| 25.96|
|2017-11-01T00:01:00.000+08:00| 24.36|
|2017-11-01T00:02:00.000+08:00| 20.09|
|2017-11-01T00:03:00.000+08:00| 20.18|
|2017-11-01T00:04:00.000+08:00| 21.13|
|2017-11-01T00:05:00.000+08:00| 22.72|
|2017-11-01T00:06:00.000+08:00| 20.71|
|2017-11-01T00:07:00.000+08:00| 21.45|
+-----------------------------+-----------------------------+
Total line number = 8
It costs 0.026sSelect Multiple Columns of Data Based on a Time Interval
The SQL statement is:
select status, temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature". The SQL statement requires that the status and temperature sensor values between the time point of "2017-11-01T00:05:00.000" and "2017-11-01T00:12:00.000" be selected.
The execution result of this SQL statement is as follows:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
|2017-11-01T00:10:00.000+08:00| true| 25.52|
|2017-11-01T00:11:00.000+08:00| false| 22.91|
+-----------------------------+------------------------+-----------------------------+
Total line number = 6
It costs 0.018sSelect Multiple Columns of Data for the Same Device According to Multiple Time Intervals
IoTDB supports specifying multiple time interval conditions in a query. Users can combine time interval conditions at will according to their needs. For example, the SQL statement is:
select status,temperature from root.ln.wf01.wt01 where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
The execution result of this SQL statement is as follows:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
|2017-11-01T00:10:00.000+08:00| true| 25.52|
|2017-11-01T00:11:00.000+08:00| false| 22.91|
|2017-11-01T16:35:00.000+08:00| true| 23.44|
|2017-11-01T16:36:00.000+08:00| false| 21.98|
|2017-11-01T16:37:00.000+08:00| false| 21.93|
+-----------------------------+------------------------+-----------------------------+
Total line number = 9
It costs 0.018sChoose Multiple Columns of Data for Different Devices According to Multiple Time Intervals
The system supports the selection of data in any column in a query, i.e., the selected columns can come from different devices. For example, the SQL statement is:
select wf01.wt01.status,wf02.wt02.hardware from root.ln where (time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000) or (time >= 2017-11-01T16:35:00.000 and time <= 2017-11-01T16:37:00.000);which means:
The selected timeseries are "the power supply status of ln group wf01 plant wt01 device" and "the hardware version of ln group wf02 plant wt02 device"; the statement specifies two different time intervals, namely "2017-11-01T00:05:00.000 to 2017-11-01T00:12:00.000" and "2017-11-01T16:35:00.000 to 2017-11-01T16:37:00.000". The SQL statement requires that the values of selected timeseries satisfying any time interval be selected.
The execution result of this SQL statement is as follows:
+-----------------------------+------------------------+--------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf02.wt02.hardware|
+-----------------------------+------------------------+--------------------------+
|2017-11-01T00:06:00.000+08:00| false| v1|
|2017-11-01T00:07:00.000+08:00| false| v1|
|2017-11-01T00:08:00.000+08:00| false| v1|
|2017-11-01T00:09:00.000+08:00| false| v1|
|2017-11-01T00:10:00.000+08:00| true| v2|
|2017-11-01T00:11:00.000+08:00| false| v1|
|2017-11-01T16:35:00.000+08:00| true| v2|
|2017-11-01T16:36:00.000+08:00| false| v1|
|2017-11-01T16:37:00.000+08:00| false| v1|
+-----------------------------+------------------------+--------------------------+
Total line number = 9
It costs 0.014sOrder By Time Query
IoTDB supports the 'order by time' statement since 0.11, it's used to display results in descending order by time. For example, the SQL statement is:
select * from root.ln.** where time > 1 order by time desc limit 10;The execution result of this SQL statement is as follows:
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
|2017-11-07T23:59:00.000+08:00| v1| false| 21.07| false|
|2017-11-07T23:58:00.000+08:00| v1| false| 22.93| false|
|2017-11-07T23:57:00.000+08:00| v2| true| 24.39| true|
|2017-11-07T23:56:00.000+08:00| v2| true| 24.44| true|
|2017-11-07T23:55:00.000+08:00| v2| true| 25.9| true|
|2017-11-07T23:54:00.000+08:00| v1| false| 22.52| false|
|2017-11-07T23:53:00.000+08:00| v2| true| 24.58| true|
|2017-11-07T23:52:00.000+08:00| v1| false| 20.18| false|
|2017-11-07T23:51:00.000+08:00| v1| false| 22.24| false|
|2017-11-07T23:50:00.000+08:00| v2| true| 23.7| true|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
Total line number = 10
It costs 0.016s1.4 Execution Interface
In IoTDB, there are two ways to execute data query:
- Execute queries using IoTDB-SQL.
- Efficient execution interfaces for common queries, including time-series raw data query, last query, and aggregation query.
Execute queries using IoTDB-SQL
Data query statements can be used in SQL command-line terminals, JDBC, JAVA / C++ / Python / Go and other native APIs, and RESTful APIs.
Execute the query statement in the SQL command line terminal: start the SQL command line terminal, and directly enter the query statement to execute, see SQL command line terminal.
Execute query statements in JDBC, see JDBC for details.
Execute query statements in native APIs such as JAVA / C++ / Python / Go. For details, please refer to the relevant documentation in the Application Programming Interface chapter. The interface prototype is as follows:
SessionDataSet executeQueryStatement(String sql)Used in RESTful API, see HTTP API V1 or HTTP API V2 for details.
Efficient execution interfaces
The native APIs provide efficient execution interfaces for commonly used queries, which can save time-consuming operations such as SQL parsing. include:
- Time-series raw data query with time range:
- The specified query time range is a left-closed right-open interval, including the start time but excluding the end time.
SessionDataSet executeRawDataQuery(List<String> paths, long startTime, long endTime);- Last query:
- Query the last data, whose timestamp is greater than or equal LastTime.
SessionDataSet executeLastDataQuery(List<String> paths, long LastTime);- Aggregation query:
- Support specified query time range: The specified query time range is a left-closed right-open interval, including the start time but not the end time.
- Support GROUP BY TIME.
SessionDataSet executeAggregationQuery(List<String> paths, List<Aggregation> aggregations);
SessionDataSet executeAggregationQuery(
List<String> paths, List<Aggregation> aggregations, long startTime, long endTime);
SessionDataSet executeAggregationQuery(
List<String> paths,
List<Aggregation> aggregations,
long startTime,
long endTime,
long interval);
SessionDataSet executeAggregationQuery(
List<String> paths,
List<Aggregation> aggregations,
long startTime,
long endTime,
long interval,
long slidingStep);2. SELECT CLAUSE
The SELECT clause specifies the output of the query, consisting of several selectExpr. Each selectExpr defines one or more columns in the query result. For select expression details, see document Operator-and-Expression.
- Example 1:
select temperature from root.ln.wf01.wt01- Example 2:
select status, temperature from root.ln.wf01.wt012.1 Last Query
The last query is a special type of query in Apache IoTDB. It returns the data point with the largest timestamp of the specified time series. In other word, it returns the latest state of a time series. This feature is especially important in IoT data analysis scenarios. To meet the performance requirement of real-time device monitoring systems, Apache IoTDB caches the latest values of all time series to achieve microsecond read latency.
The last query is to return the most recent data point of the given timeseries in a three column format.
The SQL syntax is defined as:
select last <Path> [COMMA <Path>]* from < PrefixPath > [COMMA < PrefixPath >]* <WhereClause> [ORDER BY TIMESERIES (DESC | ASC)?]which means: Query and return the last data points of timeseries prefixPath.path.
Only time filter is supported in <WhereClause>. Any other filters given in the <WhereClause> will give an exception. When the cached most recent data point does not satisfy the criterion specified by the filter, IoTDB will have to get the result from the external storage, which may cause a decrease in performance.
The result will be returned in a four column table format.
| Time | timeseries | value | dataType |Note: The
valuecolum will always return the value asstringand thus also hasTSDataType.TEXT. Therefore, the columndataTypeis returned also which contains the real type how the value should be interpreted.We can use
TIME/TIMESERIES/VALUE/DATATYPE (DESC | ASC)to specify that the result set is sorted in descending/ascending order based on a particular column. When the value column contains multiple types of data, the sorting is based on the string representation of the values.
Example 1: get the last point of root.ln.wf01.wt01.status:
IoTDB> select last status from root.ln.wf01.wt01
+-----------------------------+------------------------+-----+--------+
| Time| timeseries|value|dataType|
+-----------------------------+------------------------+-----+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.status|false| BOOLEAN|
+-----------------------------+------------------------+-----+--------+
Total line number = 1
It costs 0.000sExample 2: get the last status and temperature points of root.ln.wf01.wt01, whose timestamp larger or equal to 2017-11-07T23:50:00。
IoTDB> select last status, temperature from root.ln.wf01.wt01 where time >= 2017-11-07T23:50:00
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002sExample 3: get the last points of all sensor in root.ln.wf01.wt01, and order the result by the timeseries column in descending order
IoTDB> select last * from root.ln.wf01.wt01 order by timeseries desc;
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002sExample 4: get the last points of all sensor in root.ln.wf01.wt01, and order the result by the dataType column in descending order
IoTDB> select last * from root.ln.wf01.wt01 order by dataType desc;
+-----------------------------+-----------------------------+---------+--------+
| Time| timeseries| value|dataType|
+-----------------------------+-----------------------------+---------+--------+
|2017-11-07T23:59:00.000+08:00|root.ln.wf01.wt01.temperature|21.067368| DOUBLE|
|2017-11-07T23:59:00.000+08:00| root.ln.wf01.wt01.status| false| BOOLEAN|
+-----------------------------+-----------------------------+---------+--------+
Total line number = 2
It costs 0.002sNote: The requirement to query the latest data point with other filtering conditions can be implemented through function composition. For example:
IoTDB> select max_time(*), last_value(*) from root.ln.wf01.wt01 where time >= 2017-11-07T23:50:00 and status = false align by device
+-----------------+---------------------+----------------+-----------------------+------------------+
| Device|max_time(temperature)|max_time(status)|last_value(temperature)|last_value(status)|
+-----------------+---------------------+----------------+-----------------------+------------------+
|root.ln.wf01.wt01| 1510077540000| 1510077540000| 21.067368| false|
+-----------------+---------------------+----------------+-----------------------+------------------+
Total line number = 1
It costs 0.021s3. WHERE CLAUSE
In IoTDB query statements, two filter conditions, time filter and value filter, are supported.
The supported operators are as follows:
- Comparison operators: greater than (
>), greater than or equal (>=), equal (=or==), not equal (!=or<>), less than or equal (<=), less than (<). - Logical operators: and (
ANDor&or&&), or (ORor|or||), not (NOTor!). - Range contains operator: contains (
IN). - String matches operator:
LIKE,REGEXP.
3.1 Time Filter
Use time filters to filter data for a specific time range. For supported formats of timestamps, please refer to Timestamp .
An example is as follows:
Select data with timestamp greater than 2022-01-01T00:05:00.000:
select s1 from root.sg1.d1 where time > 2022-01-01T00:05:00.000;Select data with timestamp equal to 2022-01-01T00:05:00.000:
select s1 from root.sg1.d1 where time = 2022-01-01T00:05:00.000;Select the data in the time interval [2017-11-01T00:05:00.000, 2017-11-01T00:12:00.000):
select s1 from root.sg1.d1 where time >= 2022-01-01T00:05:00.000 and time < 2017-11-01T00:12:00.000;
Note: In the above example, time can also be written as timestamp.
3.2 Value Filter
Use value filters to filter data whose data values meet certain criteria. Allow to use a time series not selected in the select clause as a value filter.
An example is as follows:
Select data with a value greater than 36.5:
select temperature from root.sg1.d1 where temperature > 36.5;Select data with value equal to true:
select status from root.sg1.d1 where status = true;Select data for the interval [36.5,40] or not:
select temperature from root.sg1.d1 where temperature between 36.5 and 40;select temperature from root.sg1.d1 where temperature not between 36.5 and 40;Select data with values within a specific range:
select code from root.sg1.d1 where code in ('200', '300', '400', '500');Select data with values outside a certain range:
select code from root.sg1.d1 where code not in ('200', '300', '400', '500');Select data with values is null:
select code from root.sg1.d1 where temperature is null;Select data with values is not null:
select code from root.sg1.d1 where temperature is not null;
3.3 Fuzzy Query
Fuzzy query is divided into Like statement and Regexp statement, both of which can support fuzzy matching of TEXT type data.
Like statement:
Fuzzy matching using Like
In the value filter condition, for TEXT type data, use Like and Regexp operators to perform fuzzy matching on data.
Matching rules:
- The percentage (
%) wildcard matches any string of zero or more characters. - The underscore (
_) wildcard matches any single character.
Example 1: Query data containing 'cc' in value under root.sg.d1.
IoTDB> select * from root.sg.d1 where value like '%cc%'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002sExample 2: Query data that consists of 3 characters and the second character is 'b' in value under root.sg.d1.
IoTDB> select * from root.sg.device where value like '_b_'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:02.000+08:00| abc|
+-----------------------------+----------------+
Total line number = 1
It costs 0.002sFuzzy matching using Regexp
The filter conditions that need to be passed in are regular expressions in the Java standard library style.
Examples of common regular matching:
All characters with a length of 3-20: ^.{3,20}$
Uppercase english characters: ^[A-Z]+$
Numbers and English characters: ^[A-Za-z0-9]+$
Beginning with a: ^a.*Example 1: Query a string composed of 26 English characters for the value under root.sg.d1
IoTDB> select * from root.sg.d1 where value regexp '^[A-Za-z]+$'
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002sExample 2: Query root.sg.d1 where the value value is a string composed of 26 lowercase English characters and the time is greater than 100
IoTDB> select * from root.sg.d1 where value regexp '^[a-z]+$' and time > 100
+-----------------------------+----------------+
| Time|root.sg.d1.value|
+-----------------------------+----------------+
|2017-11-01T00:00:00.000+08:00| aabbccdd|
|2017-11-01T00:00:01.000+08:00| cc|
+-----------------------------+----------------+
Total line number = 2
It costs 0.002s4. GROUP BY CLAUSE
IoTDB supports using GROUP BY clause to aggregate the time series by segment and group.
Segmented aggregation refers to segmenting data in the row direction according to the time dimension, aiming at the time relationship between different data points in the same time series, and obtaining an aggregated value for each segment. Currently only group by time、group by variation、group by condition、group by session and group by count is supported, and more segmentation methods will be supported in the future.
Group aggregation refers to grouping the potential business attributes of time series for different time series. Each group contains several time series, and each group gets an aggregated value. Support group by path level and group by tag two grouping methods.
4.1 Aggregate By Segment
Aggregate By Time
Aggregate by time is a typical query method for time series data. Data is collected at high frequency and needs to be aggregated and calculated at certain time intervals. For example, to calculate the daily average temperature, the sequence of temperature needs to be segmented by day, and then calculated. average value.
Aggregate by time refers to a query method that uses a lower frequency than the time frequency of data collection, and is a special case of segmented aggregation. For example, the frequency of data collection is one second. If you want to display the data in one minute, you need to use time aggregagtion.
This section mainly introduces the related examples of time aggregation, using the GROUP BY clause. IoTDB supports partitioning result sets according to time interval and customized sliding step. And by default results are sorted by time in ascending order.
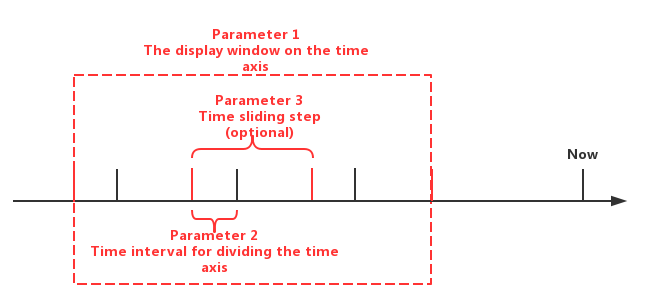
The GROUP BY statement provides users with three types of specified parameters:
- Parameter 1: The display window on the time axis
- Parameter 2: Time interval for dividing the time axis(should be positive)
- Parameter 3: Time sliding step (optional and defaults to equal the time interval if not set)
The actual meanings of the three types of parameters are shown in Figure below. Among them, the parameter 3 is optional.
There are three typical examples of frequency reduction aggregation:
Aggregate By Time without Specifying the Sliding Step Length
The SQL statement is:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d);which means:
Since the sliding step length is not specified, the GROUP BY statement by default set the sliding step the same as the time interval which is 1d.
The fist parameter of the GROUP BY statement above is the display window parameter, which determines the final display range is [2017-11-01T00:00:00, 2017-11-07T23:00:00).
The second parameter of the GROUP BY statement above is the time interval for dividing the time axis. Taking this parameter (1d) as time interval and startTime of the display window as the dividing origin, the time axis is divided into several continuous intervals, which are [0,1d), [1d, 2d), [2d, 3d), etc.
Then the system will use the time and value filtering condition in the WHERE clause and the first parameter of the GROUP BY statement as the data filtering condition to obtain the data satisfying the filtering condition (which in this case is the data in the range of [2017-11-01T00:00:00, 2017-11-07 T23:00:00]), and map these data to the previously segmented time axis (in this case there are mapped data in every 1-day period from 2017-11-01T00:00:00 to 2017-11-07T23:00:00:00).
Since there is data for each time period in the result range to be displayed, the execution result of the SQL statement is shown below:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 1440| 26.0|
|2017-11-02T00:00:00.000+08:00| 1440| 26.0|
|2017-11-03T00:00:00.000+08:00| 1440| 25.99|
|2017-11-04T00:00:00.000+08:00| 1440| 26.0|
|2017-11-05T00:00:00.000+08:00| 1440| 26.0|
|2017-11-06T00:00:00.000+08:00| 1440| 25.99|
|2017-11-07T00:00:00.000+08:00| 1380| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.024sAggregate By Time Specifying the Sliding Step Length
The SQL statement is:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d);which means:
Since the user specifies the sliding step parameter as 1d, the GROUP BY statement will move the time interval 1 day long instead of 3 hours as default.
That means we want to fetch all the data of 00:00:00 to 02:59:59 every day from 2017-11-01 to 2017-11-07.
The first parameter of the GROUP BY statement above is the display window parameter, which determines the final display range is [2017-11-01T00:00:00, 2017-11-07T23:00:00).
The second parameter of the GROUP BY statement above is the time interval for dividing the time axis. Taking this parameter (3h) as time interval and the startTime of the display window as the dividing origin, the time axis is divided into several continuous intervals, which are [2017-11-01T00:00:00, 2017-11-01T03:00:00), [2017-11-02T00:00:00, 2017-11-02T03:00:00), [2017-11-03T00:00:00, 2017-11-03T03:00:00), etc.
The third parameter of the GROUP BY statement above is the sliding step for each time interval moving.
Then the system will use the time and value filtering condition in the WHERE clause and the first parameter of the GROUP BY statement as the data filtering condition to obtain the data satisfying the filtering condition (which in this case is the data in the range of [2017-11-01T00:00:00, 2017-11-07T23:00:00]), and map these data to the previously segmented time axis (in this case there are mapped data in every 3-hour period for each day from 2017-11-01T00:00:00 to 2017-11-07T23:00:00:00).
Since there is data for each time period in the result range to be displayed, the execution result of the SQL statement is shown below:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 180| 25.98|
|2017-11-02T00:00:00.000+08:00| 180| 25.98|
|2017-11-03T00:00:00.000+08:00| 180| 25.96|
|2017-11-04T00:00:00.000+08:00| 180| 25.96|
|2017-11-05T00:00:00.000+08:00| 180| 26.0|
|2017-11-06T00:00:00.000+08:00| 180| 25.85|
|2017-11-07T00:00:00.000+08:00| 180| 25.99|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 7
It costs 0.006sThe sliding step can be smaller than the interval, in which case there is overlapping time between the aggregation windows (similar to a sliding window).
The SQL statement is:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-01 10:00:00), 4h, 2h);The execution result of the SQL statement is shown below:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-01T00:00:00.000+08:00| 180| 25.98|
|2017-11-01T02:00:00.000+08:00| 180| 25.98|
|2017-11-01T04:00:00.000+08:00| 180| 25.96|
|2017-11-01T06:00:00.000+08:00| 180| 25.96|
|2017-11-01T08:00:00.000+08:00| 180| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 5
It costs 0.006sAggregate by Natural Month
The SQL statement is:
select count(status) from root.ln.wf01.wt01 group by([2017-11-01T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);which means:
Since the user specifies the sliding step parameter as 2mo, the GROUP BY statement will move the time interval 2 months long instead of 1 month as default.
The first parameter of the GROUP BY statement above is the display window parameter, which determines the final display range is [2017-11-01T00:00:00, 2019-11-07T23:00:00).
The start time is 2017-11-01T00:00:00. The sliding step will increment monthly based on the start date, and the 1st day of the month will be used as the time interval's start time.
The second parameter of the GROUP BY statement above is the time interval for dividing the time axis. Taking this parameter (1mo) as time interval and the startTime of the display window as the dividing origin, the time axis is divided into several continuous intervals, which are [2017-11-01T00:00:00, 2017-12-01T00:00:00), [2018-02-01T00:00:00, 2018-03-01T00:00:00), [2018-05-03T00:00:00, 2018-06-01T00:00:00)), etc.
The third parameter of the GROUP BY statement above is the sliding step for each time interval moving.
Then the system will use the time and value filtering condition in the WHERE clause and the first parameter of the GROUP BY statement as the data filtering condition to obtain the data satisfying the filtering condition (which in this case is the data in the range of (2017-11-01T00:00:00, 2019-11-07T23:00:00], and map these data to the previously segmented time axis (in this case there are mapped data of the first month in every two month period from 2017-11-01T00:00:00 to 2019-11-07T23:00:00).
The SQL execution result is:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-01T00:00:00.000+08:00| 259|
|2018-01-01T00:00:00.000+08:00| 250|
|2018-03-01T00:00:00.000+08:00| 259|
|2018-05-01T00:00:00.000+08:00| 251|
|2018-07-01T00:00:00.000+08:00| 242|
|2018-09-01T00:00:00.000+08:00| 225|
|2018-11-01T00:00:00.000+08:00| 216|
|2019-01-01T00:00:00.000+08:00| 207|
|2019-03-01T00:00:00.000+08:00| 216|
|2019-05-01T00:00:00.000+08:00| 207|
|2019-07-01T00:00:00.000+08:00| 199|
|2019-09-01T00:00:00.000+08:00| 181|
|2019-11-01T00:00:00.000+08:00| 60|
+-----------------------------+-------------------------------+The SQL statement is:
select count(status) from root.ln.wf01.wt01 group by([2017-10-31T00:00:00, 2019-11-07T23:00:00), 1mo, 2mo);which means:
Since the user specifies the sliding step parameter as 2mo, the GROUP BY statement will move the time interval 2 months long instead of 1 month as default.
The first parameter of the GROUP BY statement above is the display window parameter, which determines the final display range is [2017-10-31T00:00:00, 2019-11-07T23:00:00).
Different from the previous example, the start time is set to 2017-10-31T00:00:00. The sliding step will increment monthly based on the start date, and the 31st day of the month meaning the last day of the month will be used as the time interval's start time. If the start time is set to the 30th date, the sliding step will use the 30th or the last day of the month.
The start time is 2017-10-31T00:00:00. The sliding step will increment monthly based on the start time, and the 1st day of the month will be used as the time interval's start time.
The second parameter of the GROUP BY statement above is the time interval for dividing the time axis. Taking this parameter (1mo) as time interval and the startTime of the display window as the dividing origin, the time axis is divided into several continuous intervals, which are [2017-10-31T00:00:00, 2017-11-31T00:00:00), [2018-02-31T00:00:00, 2018-03-31T00:00:00), [2018-05-31T00:00:00, 2018-06-31T00:00:00), etc.
The third parameter of the GROUP BY statement above is the sliding step for each time interval moving.
Then the system will use the time and value filtering condition in the WHERE clause and the first parameter of the GROUP BY statement as the data filtering condition to obtain the data satisfying the filtering condition (which in this case is the data in the range of [2017-10-31T00:00:00, 2019-11-07T23:00:00) and map these data to the previously segmented time axis (in this case there are mapped data of the first month in every two month period from 2017-10-31T00:00:00 to 2019-11-07T23:00:00).
The SQL execution result is:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-10-31T00:00:00.000+08:00| 251|
|2017-12-31T00:00:00.000+08:00| 250|
|2018-02-28T00:00:00.000+08:00| 259|
|2018-04-30T00:00:00.000+08:00| 250|
|2018-06-30T00:00:00.000+08:00| 242|
|2018-08-31T00:00:00.000+08:00| 225|
|2018-10-31T00:00:00.000+08:00| 216|
|2018-12-31T00:00:00.000+08:00| 208|
|2019-02-28T00:00:00.000+08:00| 216|
|2019-04-30T00:00:00.000+08:00| 208|
|2019-06-30T00:00:00.000+08:00| 199|
|2019-08-31T00:00:00.000+08:00| 181|
|2019-10-31T00:00:00.000+08:00| 69|
+-----------------------------+-------------------------------+Left Open And Right Close Range
The SQL statement is:
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d);In this sql, the time interval is left open and right close, so we won't include the value of timestamp 2017-11-01T00:00:00 and instead we will include the value of timestamp 2017-11-07T23:00:00.
We will get the result like following:
+-----------------------------+-------------------------------+
| Time|count(root.ln.wf01.wt01.status)|
+-----------------------------+-------------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------------+
Total line number = 7
It costs 0.004sAggregation By Variation
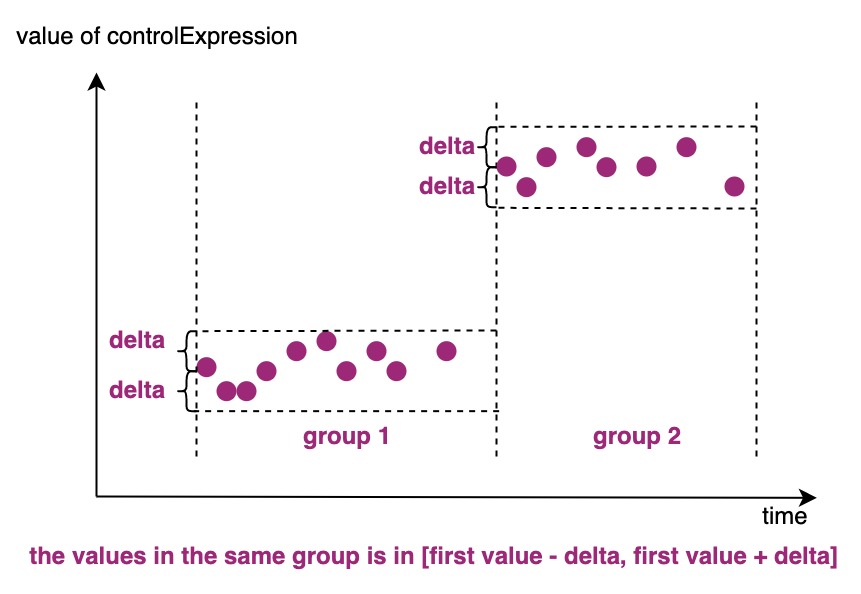
IoTDB supports grouping by continuous stable values through the GROUP BY VARIATION statement.
Group-By-Variation wil set the first point in group as the base point,
then if the difference between the new data and base point is small than or equal to delta, the data point will be grouped together and execute aggregation query (The calculation of difference and the meaning of delte are introduced below). The groups won't overlap and there is no fixed start time and end time. The syntax of clause is as follows:
group by variation(controlExpression[,delta][,ignoreNull=true/false])The different parameters mean:
- controlExpression
The value that is used to calculate difference. It can be any columns or the expression of them.
- delta
The threshold that is used when grouping. The difference of controlExpression between the first data point and new data point should less than or equal to delta. When delta is zero, all the continuous data with equal expression value will be grouped into the same group.
- ignoreNull
Used to specify how to deal with the data when the value of controlExpression is null. When ignoreNull is false, null will be treated as a new value and when ignoreNull is true, the data point will be directly skipped.
The supported return types of controlExpression and how to deal with null value when ignoreNull is false are shown in the following table:
| delta | Return Type Supported By controlExpression | The Handling of null when ignoreNull is False |
|---|---|---|
| delta!=0 | INT32、INT64、FLOAT、DOUBLE | If the processing group doesn't contains null, null value should be treated as infinity/infinitesimal and will end current group. Continuous null values are treated as stable values and assigned to the same group. |
| delta=0 | TEXT、BINARY、INT32、INT64、FLOAT、DOUBLE | Null is treated as a new value in a new group and continuous nulls belong to the same group. |
Precautions for Use
- The result of controlExpression should be a unique value. If multiple columns appear after using wildcard stitching, an error will be reported.
- For a group in resultSet, the time column output the start time of the group by default. __endTime can be used in select clause to output the endTime of groups in resultSet.
- Each device is grouped separately when used with
ALIGN BY DEVICE. - Delta is zero and ignoreNull is true by default.
- Currently
GROUP BY VARIATIONis not supported withGROUP BY LEVEL.
Using the raw data below, several examples of GROUP BY VARIAITON queries will be given.
+-----------------------------+-------+-------+-------+--------+-------+-------+
| Time| s1| s2| s3| s4| s5| s6|
+-----------------------------+-------+-------+-------+--------+-------+-------+
|1970-01-01T08:00:00.000+08:00| 4.5| 9.0| 0.0| 45.0| 9.0| 8.25|
|1970-01-01T08:00:00.010+08:00| null| 19.0| 10.0| 145.0| 19.0| 8.25|
|1970-01-01T08:00:00.020+08:00| 24.5| 29.0| null| 245.0| 29.0| null|
|1970-01-01T08:00:00.030+08:00| 34.5| null| 30.0| 345.0| null| null|
|1970-01-01T08:00:00.040+08:00| 44.5| 49.0| 40.0| 445.0| 49.0| 8.25|
|1970-01-01T08:00:00.050+08:00| null| 59.0| 50.0| 545.0| 59.0| 6.25|
|1970-01-01T08:00:00.060+08:00| 64.5| 69.0| 60.0| 645.0| 69.0| null|
|1970-01-01T08:00:00.070+08:00| 74.5| 79.0| null| null| 79.0| 3.25|
|1970-01-01T08:00:00.080+08:00| 84.5| 89.0| 80.0| 845.0| 89.0| 3.25|
|1970-01-01T08:00:00.090+08:00| 94.5| 99.0| 90.0| 945.0| 99.0| 3.25|
|1970-01-01T08:00:00.150+08:00| 66.5| 77.0| 90.0| 945.0| 99.0| 9.25|
+-----------------------------+-------+-------+-------+--------+-------+-------+delta = 0
The sql is shown below:
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6)Get the result below which ignores the row with null value in s6.
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.040+08:00| 24.5| 3| 50.0|
|1970-01-01T08:00:00.050+08:00|1970-01-01T08:00:00.050+08:00| null| 1| 50.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+when ignoreNull is false, the row with null value in s6 will be considered.
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, ignoreNull=false)Get the following result.
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.010+08:00| 4.5| 2| 10.0|
|1970-01-01T08:00:00.020+08:00|1970-01-01T08:00:00.030+08:00| 29.5| 1| 30.0|
|1970-01-01T08:00:00.040+08:00|1970-01-01T08:00:00.040+08:00| 44.5| 1| 40.0|
|1970-01-01T08:00:00.050+08:00|1970-01-01T08:00:00.050+08:00| null| 1| 50.0|
|1970-01-01T08:00:00.060+08:00|1970-01-01T08:00:00.060+08:00| 64.5| 1| 60.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+delta !=0
The sql is shown below:
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6, 4)Get the result below:
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.050+08:00| 24.5| 4| 100.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.090+08:00| 84.5| 3| 170.0|
|1970-01-01T08:00:00.150+08:00|1970-01-01T08:00:00.150+08:00| 66.5| 1| 90.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+The sql is shown below:
select __endTime, avg(s1), count(s2), sum(s3) from root.sg.d group by variation(s6+s5, 10)Get the result below:
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
| Time| __endTime|avg(root.sg.d.s1)|count(root.sg.d.s2)|sum(root.sg.d.s3)|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+
|1970-01-01T08:00:00.000+08:00|1970-01-01T08:00:00.010+08:00| 4.5| 2| 10.0|
|1970-01-01T08:00:00.040+08:00|1970-01-01T08:00:00.050+08:00| 44.5| 2| 90.0|
|1970-01-01T08:00:00.070+08:00|1970-01-01T08:00:00.080+08:00| 79.5| 2| 80.0|
|1970-01-01T08:00:00.090+08:00|1970-01-01T08:00:00.150+08:00| 80.5| 2| 180.0|
+-----------------------------+-----------------------------+-----------------+-------------------+-----------------+Aggregation By Condition
When you need to filter the data according to a specific condition and group the continuous ones for an aggregation query. GROUP BY CONDITION is suitable for you.The rows which don't meet the given condition will be simply ignored because they don't belong to any group. Its syntax is defined below:
group by condition(predict,[keep>/>=/=/<=/<]threshold,[,ignoreNull=true/false])- predict
Any legal expression return the type of boolean for filtering in grouping.
- [keep>/>=/=/<=/<]threshold
Keep expression is used to specify the number of continuous rows that meet the predict condition to form a group. Only the number of rows in group satisfy the keep condition, the result of group will be output. Keep expression consists of a 'keep' string and a threshold of type long or a single 'long' type data.
- ignoreNull=true/false
Used to specify how to handle data rows that encounter null predict, skip the row when it's true and end current group when it's false.
Precautions for Use
- keep condition is required in the query, but you can omit the 'keep' string and given a
longnumber which defaults to 'keep=long number' condition. - IgnoreNull defaults to true.
- For a group in resultSet, the time column output the start time of the group by default. __endTime can be used in select clause to output the endTime of groups in resultSet.
- Each device is grouped separately when used with
ALIGN BY DEVICE. - Currently
GROUP BY CONDITIONis not supported withGROUP BY LEVEL.
For the following raw data, several query examples are given below:
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+
| Time|root.sg.beijing.car01.soc|root.sg.beijing.car01.charging_status|root.sg.beijing.car01.vehicle_status|
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+
|1970-01-01T08:00:00.001+08:00| 14.0| 1| 1|
|1970-01-01T08:00:00.002+08:00| 16.0| 1| 1|
|1970-01-01T08:00:00.003+08:00| 16.0| 0| 1|
|1970-01-01T08:00:00.004+08:00| 16.0| 0| 1|
|1970-01-01T08:00:00.005+08:00| 18.0| 1| 1|
|1970-01-01T08:00:00.006+08:00| 24.0| 1| 1|
|1970-01-01T08:00:00.007+08:00| 36.0| 1| 1|
|1970-01-01T08:00:00.008+08:00| 36.0| null| 1|
|1970-01-01T08:00:00.009+08:00| 45.0| 1| 1|
|1970-01-01T08:00:00.010+08:00| 60.0| 1| 1|
+-----------------------------+-------------------------+-------------------------------------+------------------------------------+The sql statement to query data with at least two continuous row shown below:
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoringNull=true)Get the result below:
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
| Time|max_time(root.sg.beijing.car01.charging_status)|count(root.sg.beijing.car01.vehicle_status)|last_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
|1970-01-01T08:00:00.001+08:00| 2| 2| 16.0|
|1970-01-01T08:00:00.005+08:00| 10| 5| 60.0|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+When ignoreNull is false, the null value will be treated as a row that doesn't meet the condition.
select max_time(charging_status),count(vehicle_status),last_value(soc) from root.** group by condition(charging_status=1,KEEP>=2,ignoringNull=false)Get the result below, the original group is split.
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
| Time|max_time(root.sg.beijing.car01.charging_status)|count(root.sg.beijing.car01.vehicle_status)|last_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+
|1970-01-01T08:00:00.001+08:00| 2| 2| 16.0|
|1970-01-01T08:00:00.005+08:00| 7| 3| 36.0|
|1970-01-01T08:00:00.009+08:00| 10| 2| 60.0|
+-----------------------------+-----------------------------------------------+-------------------------------------------+-------------------------------------+Aggregation By Session
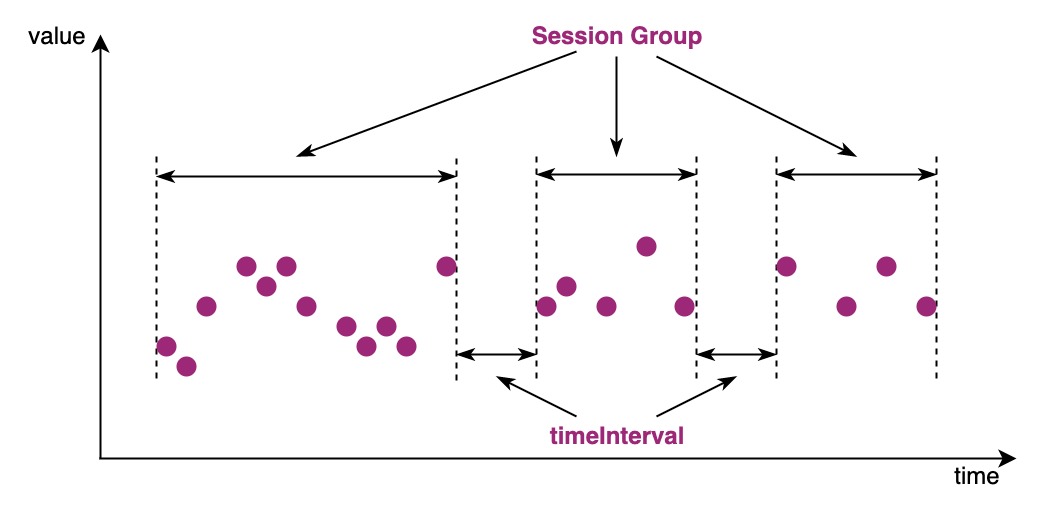
GROUP BY SESSION can be used to group data according to the interval of the time. Data with a time interval less than or equal to the given threshold will be assigned to the same group. For example, in industrial scenarios, devices don't always run continuously, GROUP BY SESSION will group the data generated by each access session of the device. Its syntax is defined as follows:
group by session(timeInterval)- timeInterval
A given interval threshold to create a new group of data when the difference between the time of data is greater than the threshold.
The figure below is a grouping diagram under GROUP BY SESSION.
Precautions for Use
- For a group in resultSet, the time column output the start time of the group by default. __endTime can be used in select clause to output the endTime of groups in resultSet.
- Each device is grouped separately when used with
ALIGN BY DEVICE. - Currently
GROUP BY SESSIONis not supported withGROUP BY LEVEL.
For the raw data below, a few query examples are given:
+-----------------------------+-----------------+-----------+--------+------+
| Time| Device|temperature|hardware|status|
+-----------------------------+-----------------+-----------+--------+------+
|1970-01-01T08:00:01.000+08:00|root.ln.wf02.wt01| 35.7| 11| false|
|1970-01-01T08:00:02.000+08:00|root.ln.wf02.wt01| 35.8| 22| true|
|1970-01-01T08:00:03.000+08:00|root.ln.wf02.wt01| 35.4| 33| false|
|1970-01-01T08:00:04.000+08:00|root.ln.wf02.wt01| 36.4| 44| false|
|1970-01-01T08:00:05.000+08:00|root.ln.wf02.wt01| 36.8| 55| false|
|1970-01-01T08:00:10.000+08:00|root.ln.wf02.wt01| 36.8| 110| false|
|1970-01-01T08:00:20.000+08:00|root.ln.wf02.wt01| 37.8| 220| true|
|1970-01-01T08:00:30.000+08:00|root.ln.wf02.wt01| 37.5| 330| false|
|1970-01-01T08:00:40.000+08:00|root.ln.wf02.wt01| 37.4| 440| false|
|1970-01-01T08:00:50.000+08:00|root.ln.wf02.wt01| 37.9| 550| false|
|1970-01-01T08:01:40.000+08:00|root.ln.wf02.wt01| 38.0| 110| false|
|1970-01-01T08:02:30.000+08:00|root.ln.wf02.wt01| 38.8| 220| true|
|1970-01-01T08:03:20.000+08:00|root.ln.wf02.wt01| 38.6| 330| false|
|1970-01-01T08:04:20.000+08:00|root.ln.wf02.wt01| 38.4| 440| false|
|1970-01-01T08:05:20.000+08:00|root.ln.wf02.wt01| 38.3| 550| false|
|1970-01-01T08:06:40.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-01T08:07:50.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-01T08:08:00.000+08:00|root.ln.wf02.wt01| null| 0| null|
|1970-01-02T08:08:01.000+08:00|root.ln.wf02.wt01| 38.2| 110| false|
|1970-01-02T08:08:02.000+08:00|root.ln.wf02.wt01| 37.5| 220| true|
|1970-01-02T08:08:03.000+08:00|root.ln.wf02.wt01| 37.4| 330| false|
|1970-01-02T08:08:04.000+08:00|root.ln.wf02.wt01| 36.8| 440| false|
|1970-01-02T08:08:05.000+08:00|root.ln.wf02.wt01| 37.4| 550| false|
+-----------------------------+-----------------+-----------+--------+------+TimeInterval can be set by different time units, the sql is shown below:
select __endTime,count(*) from root.** group by session(1d)Get the result:
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+
| Time| __endTime|count(root.ln.wf02.wt01.temperature)|count(root.ln.wf02.wt01.hardware)|count(root.ln.wf02.wt01.status)|
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+
|1970-01-01T08:00:01.000+08:00|1970-01-01T08:08:00.000+08:00| 15| 18| 15|
|1970-01-02T08:08:01.000+08:00|1970-01-02T08:08:05.000+08:00| 5| 5| 5|
+-----------------------------+-----------------------------+------------------------------------+---------------------------------+-------------------------------+It can be also used with HAVING and ALIGN BY DEVICE clauses.
select __endTime,sum(hardware) from root.ln.wf02.wt01 group by session(50s) having sum(hardware)>0 align by deviceGet the result below:
+-----------------------------+-----------------+-----------------------------+-------------+
| Time| Device| __endTime|sum(hardware)|
+-----------------------------+-----------------+-----------------------------+-------------+
|1970-01-01T08:00:01.000+08:00|root.ln.wf02.wt01|1970-01-01T08:03:20.000+08:00| 2475.0|
|1970-01-01T08:04:20.000+08:00|root.ln.wf02.wt01|1970-01-01T08:04:20.000+08:00| 440.0|
|1970-01-01T08:05:20.000+08:00|root.ln.wf02.wt01|1970-01-01T08:05:20.000+08:00| 550.0|
|1970-01-02T08:08:01.000+08:00|root.ln.wf02.wt01|1970-01-02T08:08:05.000+08:00| 1650.0|
+-----------------------------+-----------------+-----------------------------+-------------+Aggregation By Count
GROUP BY COUNTcan aggregate the data points according to the number of points. It can group fixed number of continuous data points together for aggregation query. Its syntax is defined as follows:
group by count(controlExpression, size[,ignoreNull=true/false])- controlExpression
The object to count during processing, it can be any column or an expression of columns.
- size
The number of data points in a group, a number of size continuous points will be divided to the same group.
- ignoreNull=true/false
Whether to ignore the data points with null in controlExpression, when ignoreNull is true, data points with the controlExpression of null will be skipped during counting.
Precautions for Use
- For a group in resultSet, the time column output the start time of the group by default. __endTime can be used in select clause to output the endTime of groups in resultSet.
- Each device is grouped separately when used with
ALIGN BY DEVICE. - Currently
GROUP BY SESSIONis not supported withGROUP BY LEVEL. - When the final number of data points in a group is less than
size, the result of the group will not be output.
For the data below, some examples will be given.
+-----------------------------+-----------+-----------------------+
| Time|root.sg.soc|root.sg.charging_status|
+-----------------------------+-----------+-----------------------+
|1970-01-01T08:00:00.001+08:00| 14.0| 1|
|1970-01-01T08:00:00.002+08:00| 16.0| 1|
|1970-01-01T08:00:00.003+08:00| 16.0| 0|
|1970-01-01T08:00:00.004+08:00| 16.0| 0|
|1970-01-01T08:00:00.005+08:00| 18.0| 1|
|1970-01-01T08:00:00.006+08:00| 24.0| 1|
|1970-01-01T08:00:00.007+08:00| 36.0| 1|
|1970-01-01T08:00:00.008+08:00| 36.0| null|
|1970-01-01T08:00:00.009+08:00| 45.0| 1|
|1970-01-01T08:00:00.010+08:00| 60.0| 1|
+-----------------------------+-----------+-----------------------+The sql is shown below
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5)Get the result below, in the second group from 1970-01-01T08:00:00.006+08:00 to 1970-01-01T08:00:00.010+08:00. There are only four points included which is less than size. So it won't be output.
+-----------------------------+-----------------------------+--------------------------------------+
| Time| __endTime|first_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00|1970-01-01T08:00:00.005+08:00| 14.0|
+-----------------------------+-----------------------------+--------------------------------------+When ignoreNull=false is used to take null value into account. There will be two groups with 5 points in the resultSet, which is shown as follows:
select count(charging_stauts), first_value(soc) from root.sg group by count(charging_status,5,ignoreNull=false)Get the results:
+-----------------------------+-----------------------------+--------------------------------------+
| Time| __endTime|first_value(root.sg.beijing.car01.soc)|
+-----------------------------+-----------------------------+--------------------------------------+
|1970-01-01T08:00:00.001+08:00|1970-01-01T08:00:00.005+08:00| 14.0|
|1970-01-01T08:00:00.006+08:00|1970-01-01T08:00:00.010+08:00| 24.0|
+-----------------------------+-----------------------------+--------------------------------------+4.2 Aggregate By Group
Aggregation By Level
Aggregation by level statement is used to group the query result whose name is the same at the given level.
- Keyword
LEVELis used to specify the level that need to be grouped. By convention,level=0represents root level. - All aggregation functions are supported. When using five aggregations: sum, avg, min_value, max_value and extreme, please make sure all the aggregated series have exactly the same data type. Otherwise, it will generate a syntax error.
Example 1: there are multiple series named status under different databases, like "root.ln.wf01.wt01.status", "root.ln.wf02.wt02.status", and "root.sgcc.wf03.wt01.status". If you need to count the number of data points of the status sequence under different databases, use the following query:
select count(status) from root.** group by level = 1Result:
+-------------------------+---------------------------+
|count(root.ln.*.*.status)|count(root.sgcc.*.*.status)|
+-------------------------+---------------------------+
| 20160| 10080|
+-------------------------+---------------------------+
Total line number = 1
It costs 0.003sExample 2: If you need to count the number of data points under different devices, you can specify level = 3,
select count(status) from root.** group by level = 3Result:
+---------------------------+---------------------------+
|count(root.*.*.wt01.status)|count(root.*.*.wt02.status)|
+---------------------------+---------------------------+
| 20160| 10080|
+---------------------------+---------------------------+
Total line number = 1
It costs 0.003sExample 3: Attention,the devices named wt01 under databases ln and sgcc are grouped together, since they are regarded as devices with the same name. If you need to further count the number of data points in different devices under different databases, you can use the following query:
select count(status) from root.** group by level = 1, 3Result:
+----------------------------+----------------------------+------------------------------+
|count(root.ln.*.wt01.status)|count(root.ln.*.wt02.status)|count(root.sgcc.*.wt01.status)|
+----------------------------+----------------------------+------------------------------+
| 10080| 10080| 10080|
+----------------------------+----------------------------+------------------------------+
Total line number = 1
It costs 0.003sExample 4: Assuming that you want to query the maximum value of temperature sensor under all time series, you can use the following query statement:
select max_value(temperature) from root.** group by level = 0Result:
+---------------------------------+
|max_value(root.*.*.*.temperature)|
+---------------------------------+
| 26.0|
+---------------------------------+
Total line number = 1
It costs 0.013sExample 5: The above queries are for a certain sensor. In particular, if you want to query the total data points owned by all sensors at a certain level, you need to explicitly specify * is selected.
select count(*) from root.ln.** group by level = 2Result:
+----------------------+----------------------+
|count(root.*.wf01.*.*)|count(root.*.wf02.*.*)|
+----------------------+----------------------+
| 20160| 20160|
+----------------------+----------------------+
Total line number = 1
It costs 0.013sAggregate By Time with Level Clause
Level could be defined to show count the number of points of each node at the given level in current Metadata Tree.
This could be used to query the number of points under each device.
The SQL statement is:
Get time aggregation by level.
select count(status) from root.ln.wf01.wt01 group by ((2017-11-01T00:00:00, 2017-11-07T23:00:00],1d), level=1;Result:
+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-02T00:00:00.000+08:00| 1440|
|2017-11-03T00:00:00.000+08:00| 1440|
|2017-11-04T00:00:00.000+08:00| 1440|
|2017-11-05T00:00:00.000+08:00| 1440|
|2017-11-06T00:00:00.000+08:00| 1440|
|2017-11-07T00:00:00.000+08:00| 1440|
|2017-11-07T23:00:00.000+08:00| 1380|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.006sTime aggregation with sliding step and by level.
select count(status) from root.ln.wf01.wt01 group by ([2017-11-01 00:00:00, 2017-11-07 23:00:00), 3h, 1d), level=1;Result:
+-----------------------------+-------------------------+
| Time|COUNT(root.ln.*.*.status)|
+-----------------------------+-------------------------+
|2017-11-01T00:00:00.000+08:00| 180|
|2017-11-02T00:00:00.000+08:00| 180|
|2017-11-03T00:00:00.000+08:00| 180|
|2017-11-04T00:00:00.000+08:00| 180|
|2017-11-05T00:00:00.000+08:00| 180|
|2017-11-06T00:00:00.000+08:00| 180|
|2017-11-07T00:00:00.000+08:00| 180|
+-----------------------------+-------------------------+
Total line number = 7
It costs 0.004sAggregation By Tags
IotDB allows you to do aggregation query with the tags defined in timeseries through GROUP BY TAGS clause as well.
Firstly, we can put these example data into IoTDB, which will be used in the following feature introduction.
These are the temperature data of the workshops, which belongs to the factory factory1 and locates in different cities. The time range is [1000, 10000).
The device node of the timeseries path is the ID of the device. The information of city and workshop are modelled in the tags city and workshop. The devices d1 and d2 belong to the workshop d1 in Beijing. d3 and d4 belong to the workshop w2 in Beijing. d5 and d6 belong to the workshop w1 in Shanghai. d7 belongs to the workshop w2 in Shanghai. d8 and d9 are under maintenance, and don't belong to any workshops, so they have no tags.
CREATE DATABASE root.factory1;
create timeseries root.factory1.d1.temperature with datatype=FLOAT tags(city=Beijing, workshop=w1);
create timeseries root.factory1.d2.temperature with datatype=FLOAT tags(city=Beijing, workshop=w1);
create timeseries root.factory1.d3.temperature with datatype=FLOAT tags(city=Beijing, workshop=w2);
create timeseries root.factory1.d4.temperature with datatype=FLOAT tags(city=Beijing, workshop=w2);
create timeseries root.factory1.d5.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w1);
create timeseries root.factory1.d6.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w1);
create timeseries root.factory1.d7.temperature with datatype=FLOAT tags(city=Shanghai, workshop=w2);
create timeseries root.factory1.d8.temperature with datatype=FLOAT;
create timeseries root.factory1.d9.temperature with datatype=FLOAT;
insert into root.factory1.d1(time, temperature) values(1000, 104.0);
insert into root.factory1.d1(time, temperature) values(3000, 104.2);
insert into root.factory1.d1(time, temperature) values(5000, 103.3);
insert into root.factory1.d1(time, temperature) values(7000, 104.1);
insert into root.factory1.d2(time, temperature) values(1000, 104.4);
insert into root.factory1.d2(time, temperature) values(3000, 103.7);
insert into root.factory1.d2(time, temperature) values(5000, 103.3);
insert into root.factory1.d2(time, temperature) values(7000, 102.9);
insert into root.factory1.d3(time, temperature) values(1000, 103.9);
insert into root.factory1.d3(time, temperature) values(3000, 103.8);
insert into root.factory1.d3(time, temperature) values(5000, 102.7);
insert into root.factory1.d3(time, temperature) values(7000, 106.9);
insert into root.factory1.d4(time, temperature) values(1000, 103.9);
insert into root.factory1.d4(time, temperature) values(5000, 102.7);
insert into root.factory1.d4(time, temperature) values(7000, 106.9);
insert into root.factory1.d5(time, temperature) values(1000, 112.9);
insert into root.factory1.d5(time, temperature) values(7000, 113.0);
insert into root.factory1.d6(time, temperature) values(1000, 113.9);
insert into root.factory1.d6(time, temperature) values(3000, 113.3);
insert into root.factory1.d6(time, temperature) values(5000, 112.7);
insert into root.factory1.d6(time, temperature) values(7000, 112.3);
insert into root.factory1.d7(time, temperature) values(1000, 101.2);
insert into root.factory1.d7(time, temperature) values(3000, 99.3);
insert into root.factory1.d7(time, temperature) values(5000, 100.1);
insert into root.factory1.d7(time, temperature) values(7000, 99.8);
insert into root.factory1.d8(time, temperature) values(1000, 50.0);
insert into root.factory1.d8(time, temperature) values(3000, 52.1);
insert into root.factory1.d8(time, temperature) values(5000, 50.1);
insert into root.factory1.d8(time, temperature) values(7000, 50.5);
insert into root.factory1.d9(time, temperature) values(1000, 50.3);
insert into root.factory1.d9(time, temperature) values(3000, 52.1);Aggregation query by one single tag
If the user wants to know the average temperature of each workshop, he can query like this
SELECT AVG(temperature) FROM root.factory1.** GROUP BY TAGS(city);The query will calculate the average of the temperatures of those timeseries which have the same tag value of the key city. The results are
+--------+------------------+
| city| avg(temperature)|
+--------+------------------+
| Beijing|104.04666697184244|
|Shanghai|107.85000076293946|
| NULL| 50.84999910990397|
+--------+------------------+
Total line number = 3
It costs 0.231sFrom the results we can see that the differences between aggregation by tags query and aggregation by time or level query are:
- Aggregation query by tags will no longer remove wildcard to raw timeseries, but do the aggregation through the data of multiple timeseries, which have the same tag value.
- Except for the aggregate result column, the result set contains the key-value column of the grouped tag. The column name is the tag key, and the values in the column are tag values which present in the searched timeseries. If some searched timeseries doesn't have the grouped tag, a
NULLvalue in the key-value column of the grouped tag will be presented, which means the aggregation of all the timeseries lacking the tagged key.
Aggregation query by multiple tags
Except for the aggregation query by one single tag, aggregation query by multiple tags in a particular order is allowed as well.
For example, a user wants to know the average temperature of the devices in each workshop. As the workshop names may be same in different city, it's not correct to aggregated by the tag workshop directly. So the aggregation by the tag city should be done first, and then by the tag workshop.
SQL
SELECT avg(temperature) FROM root.factory1.** GROUP BY TAGS(city, workshop);The results
+--------+--------+------------------+
| city|workshop| avg(temperature)|
+--------+--------+------------------+
| NULL| NULL| 50.84999910990397|
|Shanghai| w1|113.01666768391927|
| Beijing| w2| 104.4000004359654|
|Shanghai| w2|100.10000038146973|
| Beijing| w1|103.73750019073486|
+--------+--------+------------------+
Total line number = 5
It costs 0.027sWe can see that in a multiple tags aggregation query, the result set will output the key-value columns of all the grouped tag keys, which have the same order with the one in GROUP BY TAGS.
Downsampling Aggregation by tags based on Time Window
Downsampling aggregation by time window is one of the most popular features in a time series database. IoTDB supports to do aggregation query by tags based on time window.
For example, a user wants to know the average temperature of the devices in each workshop, in every 5 seconds, in the range of time [1000, 10000).
SQL
SELECT avg(temperature) FROM root.factory1.** GROUP BY ([1000, 10000), 5s), TAGS(city, workshop);The results
+-----------------------------+--------+--------+------------------+
| Time| city|workshop| avg(temperature)|
+-----------------------------+--------+--------+------------------+
|1970-01-01T08:00:01.000+08:00| NULL| NULL| 50.91999893188476|
|1970-01-01T08:00:01.000+08:00|Shanghai| w1|113.20000076293945|
|1970-01-01T08:00:01.000+08:00| Beijing| w2| 103.4|
|1970-01-01T08:00:01.000+08:00|Shanghai| w2| 100.1999994913737|
|1970-01-01T08:00:01.000+08:00| Beijing| w1|103.81666692097981|
|1970-01-01T08:00:06.000+08:00| NULL| NULL| 50.5|
|1970-01-01T08:00:06.000+08:00|Shanghai| w1| 112.6500015258789|
|1970-01-01T08:00:06.000+08:00| Beijing| w2| 106.9000015258789|
|1970-01-01T08:00:06.000+08:00|Shanghai| w2| 99.80000305175781|
|1970-01-01T08:00:06.000+08:00| Beijing| w1| 103.5|
+-----------------------------+--------+--------+------------------+Comparing to the pure tag aggregations, this kind of aggregation will divide the data according to the time window specification firstly, and do the aggregation query by the multiple tags in each time window secondly. The result set will also contain a time column, which have the same meaning with the time column of the result in downsampling aggregation query by time window.
Limitation of Aggregation by Tags
As this feature is still under development, some queries have not been completed yet and will be supported in the future.
- Temporarily not support
HAVINGclause to filter the results.- Temporarily not support ordering by tag values.
- Temporarily not support
LIMIT,OFFSET,SLIMIT,SOFFSET.- Temporarily not support
ALIGN BY DEVICE.- Temporarily not support expressions as aggregation function parameter,e.g.
count(s+1).- Not support the value filter, which stands the same with the
GROUP BY LEVELquery.
5. HAVING CLAUSE
If you want to filter the results of aggregate queries, you can use the HAVING clause after the GROUP BY clause.
NOTE:
1.The expression in HAVING clause must consist of aggregate values; the original sequence cannot appear alone. The following usages are incorrect:
select count(s1) from root.** group by ([1,3),1ms) having sum(s1) > s1 select count(s1) from root.** group by ([1,3),1ms) having s1 > 12.When filtering the
GROUP BY LEVELresult, the PATH inSELECTandHAVINGcan only have one node. The following usages are incorrect:select count(s1) from root.** group by ([1,3),1ms), level=1 having sum(d1.s1) > 1 select count(d1.s1) from root.** group by ([1,3),1ms), level=1 having sum(s1) > 1
Here are a few examples of using the 'HAVING' clause to filter aggregate results.
Aggregation result 1:
+-----------------------------+---------------------+---------------------+
| Time|count(root.test.*.s1)|count(root.test.*.s2)|
+-----------------------------+---------------------+---------------------+
|1970-01-01T08:00:00.001+08:00| 4| 4|
|1970-01-01T08:00:00.003+08:00| 1| 0|
|1970-01-01T08:00:00.005+08:00| 2| 4|
|1970-01-01T08:00:00.007+08:00| 3| 2|
|1970-01-01T08:00:00.009+08:00| 4| 4|
+-----------------------------+---------------------+---------------------+Aggregation result filtering query 1:
select count(s1) from root.** group by ([1,11),2ms), level=1 having count(s2) > 1Filtering result 1:
+-----------------------------+---------------------+
| Time|count(root.test.*.s1)|
+-----------------------------+---------------------+
|1970-01-01T08:00:00.001+08:00| 4|
|1970-01-01T08:00:00.005+08:00| 2|
|1970-01-01T08:00:00.009+08:00| 4|
+-----------------------------+---------------------+Aggregation result 2:
+-----------------------------+-------------+---------+---------+
| Time| Device|count(s1)|count(s2)|
+-----------------------------+-------------+---------+---------+
|1970-01-01T08:00:00.001+08:00|root.test.sg1| 1| 2|
|1970-01-01T08:00:00.003+08:00|root.test.sg1| 1| 0|
|1970-01-01T08:00:00.005+08:00|root.test.sg1| 1| 2|
|1970-01-01T08:00:00.007+08:00|root.test.sg1| 2| 1|
|1970-01-01T08:00:00.009+08:00|root.test.sg1| 2| 2|
|1970-01-01T08:00:00.001+08:00|root.test.sg2| 2| 2|
|1970-01-01T08:00:00.003+08:00|root.test.sg2| 0| 0|
|1970-01-01T08:00:00.005+08:00|root.test.sg2| 1| 2|
|1970-01-01T08:00:00.007+08:00|root.test.sg2| 1| 1|
|1970-01-01T08:00:00.009+08:00|root.test.sg2| 2| 2|
+-----------------------------+-------------+---------+---------+Aggregation result filtering query 2:
select count(s1), count(s2) from root.** group by ([1,11),2ms) having count(s2) > 1 align by deviceFiltering result 2:
+-----------------------------+-------------+---------+---------+
| Time| Device|count(s1)|count(s2)|
+-----------------------------+-------------+---------+---------+
|1970-01-01T08:00:00.001+08:00|root.test.sg1| 1| 2|
|1970-01-01T08:00:00.005+08:00|root.test.sg1| 1| 2|
|1970-01-01T08:00:00.009+08:00|root.test.sg1| 2| 2|
|1970-01-01T08:00:00.001+08:00|root.test.sg2| 2| 2|
|1970-01-01T08:00:00.005+08:00|root.test.sg2| 1| 2|
|1970-01-01T08:00:00.009+08:00|root.test.sg2| 2| 2|
+-----------------------------+-------------+---------+---------+6. FILL CLAUSE
6.1 Introduction
When executing some queries, there may be no data for some columns in some rows, and data in these locations will be null, but this kind of null value is not conducive to data visualization and analysis, and the null value needs to be filled.
In IoTDB, users can use the FILL clause to specify the fill mode when data is missing. Fill null value allows the user to fill any query result with null values according to a specific method, such as taking the previous value that is not null, or linear interpolation. The query result after filling the null value can better reflect the data distribution, which is beneficial for users to perform data analysis.
6.2 Syntax Definition
The following is the syntax definition of the FILL clause:
FILL '(' PREVIOUS | LINEAR | constant ')'Note:
- We can specify only one fill method in the
FILLclause, and this method applies to all columns of the result set. - Null value fill is not compatible with version 0.13 and previous syntax (
FILL((<data_type>[<fill_method>(, <before_range>, <after_range>)?])+)) is not supported anymore.
6.3 Fill Methods
IoTDB supports the following three fill methods:
PREVIOUS: Fill with the previous non-null value of the column.LINEAR: Fill the column with a linear interpolation of the previous non-null value and the next non-null value of the column.- Constant: Fill with the specified constant.
Following table lists the data types and supported fill methods.
| Data Type | Supported Fill Methods |
|---|---|
| boolean | previous, value |
| int32 | previous, linear, value |
| int64 | previous, linear, value |
| float | previous, linear, value |
| double | previous, linear, value |
| text | previous, value |
Note: For columns whose data type does not support specifying the fill method, we neither fill it nor throw exception, just keep it as it is.
For examples:
If we don't use any fill methods:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000;the original result will be like:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| null| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4PREVIOUS Fill
For null values in the query result set, fill with the previous non-null value of the column.
Note: If the first value of this column is null, we will keep first value as null and won't fill it until we meet first non-null value
For example, with PREVIOUS fill, the SQL is as follows:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(previous);result will be like:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 21.93| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| false|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4While using FILL(PREVIOUS), you can specify a time interval. If the interval between the timestamp of the current null value and the timestamp of the previous non-null value exceeds the specified time interval, no filling will be performed.
- In the case of FILL(LINEAR) and FILL(CONSTANT), if the second parameter is specified, an exception will be thrown
- The interval parameter only supports integers For example, the raw data looks like this:
select s1 from root.db.d1+-----------------------------+-------------+
| Time|root.db.d1.s1|
+-----------------------------+-------------+
|2023-11-08T16:41:50.008+08:00| 1.0|
+-----------------------------+-------------+
|2023-11-08T16:46:50.011+08:00| 2.0|
+-----------------------------+-------------+
|2023-11-08T16:48:50.011+08:00| 3.0|
+-----------------------------+-------------+We want to group the data by 1 min time interval:
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| null|
+-----------------------------+------------------+After grouping, we want to fill the null value:
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)
FILL(PREVIOUS);+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| 3.0|
+-----------------------------+------------------+we also don't want the null value to be filled if it keeps null for 2 min.
select avg(s1)
from root.db.d1
group by([2023-11-08T16:40:00.008+08:00, 2023-11-08T16:50:00.008+08:00), 1m)
FILL(PREVIOUS, 2m);+-----------------------------+------------------+
| Time|avg(root.db.d1.s1)|
+-----------------------------+------------------+
|2023-11-08T16:40:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:41:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:42:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:43:00.008+08:00| 1.0|
+-----------------------------+------------------+
|2023-11-08T16:44:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:45:00.008+08:00| null|
+-----------------------------+------------------+
|2023-11-08T16:46:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:47:00.008+08:00| 2.0|
+-----------------------------+------------------+
|2023-11-08T16:48:00.008+08:00| 3.0|
+-----------------------------+------------------+
|2023-11-08T16:49:00.008+08:00| 3.0|
+-----------------------------+------------------+LINEAR Fill
For null values in the query result set, fill the column with a linear interpolation of the previous non-null value and the next non-null value of the column.
Note:
- If all the values before current value are null or all the values after current value are null, we will keep current value as null and won't fill it.
- If the column's data type is boolean/text, we neither fill it nor throw exception, just keep it as it is.
Here we give an example of filling null values using the linear method. The SQL statement is as follows:
For example, with LINEAR fill, the SQL is as follows:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(linear);result will be like:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 22.08| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4Constant Fill
For null values in the query result set, fill with the specified constant.
Note:
When using the ValueFill, IoTDB neither fill the query result if the data type is different from the input constant nor throw exception, just keep it as it is.
Constant Value Data Type Support Data Type BOOLEANBOOLEANTEXTINT64INT32INT64FLOATDOUBLETEXTDOUBLEFLOATDOUBLETEXTTEXTTEXTIf constant value is larger than Integer.MAX_VALUE, IoTDB neither fill the query result if the data type is int32 nor throw exception, just keep it as it is.
For example, with FLOAT constant fill, the SQL is as follows:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(2.0);result will be like:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| 2.0| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| null|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| null|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 4For example, with BOOLEAN constant fill, the SQL is as follows:
select temperature, status from root.sgcc.wf03.wt01 where time >= 2017-11-01T16:37:00.000 and time <= 2017-11-01T16:40:00.000 fill(true);result will be like:
+-----------------------------+-------------------------------+--------------------------+
| Time|root.sgcc.wf03.wt01.temperature|root.sgcc.wf03.wt01.status|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:37:00.000+08:00| 21.93| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:38:00.000+08:00| null| false|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:39:00.000+08:00| 22.23| true|
+-----------------------------+-------------------------------+--------------------------+
|2017-11-01T16:40:00.000+08:00| 23.43| true|
+-----------------------------+-------------------------------+--------------------------+
Total line number = 47. LIMIT and SLIMIT CLAUSES (PAGINATION)
When the query result set has a large amount of data, it is not conducive to display on one page. You can use the LIMIT/SLIMIT clause and the OFFSET/SOFFSET clause to control paging.
- The
LIMITandSLIMITclauses are used to control the number of rows and columns of query results. - The
OFFSETandSOFFSETclauses are used to control the starting position of the result display.
7.1 Row Control over Query Results
By using LIMIT and OFFSET clauses, users control the query results in a row-related manner. We demonstrate how to use LIMIT and OFFSET clauses through the following examples.
- Example 1: basic LIMIT clause
The SQL statement is:
select status, temperature from root.ln.wf01.wt01 limit 10which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature". The SQL statement requires the first 10 rows of the query result.
The result is shown below:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:00:00.000+08:00| true| 25.96|
|2017-11-01T00:01:00.000+08:00| true| 24.36|
|2017-11-01T00:02:00.000+08:00| false| 20.09|
|2017-11-01T00:03:00.000+08:00| false| 20.18|
|2017-11-01T00:04:00.000+08:00| false| 21.13|
|2017-11-01T00:05:00.000+08:00| false| 22.72|
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
+-----------------------------+------------------------+-----------------------------+
Total line number = 10
It costs 0.000s- Example 2: LIMIT clause with OFFSET
The SQL statement is:
select status, temperature from root.ln.wf01.wt01 limit 5 offset 3which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is "status" and "temperature". The SQL statement requires rows 3 to 7 of the query result be returned (with the first row numbered as row 0).
The result is shown below:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:03:00.000+08:00| false| 20.18|
|2017-11-01T00:04:00.000+08:00| false| 21.13|
|2017-11-01T00:05:00.000+08:00| false| 22.72|
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
+-----------------------------+------------------------+-----------------------------+
Total line number = 5
It costs 0.342s- Example 3: LIMIT clause combined with WHERE clause
The SQL statement is:
select status,temperature from root.ln.wf01.wt01 where time > 2024-07-07T00:05:00.000 and time< 2024-07-12T00:12:00.000 limit 5 offset 3which means:
The selected equipment is the ln group wf01 factory wt01 equipment; The selected time series are "state" and "temperature". The SQL statement requires the return of the status and temperature sensor values between the time "2024-07-07T00:05:00.000" and "2024-07-12T00:12:00.0000" on lines 3 to 7 (the first line is numbered as line 0).
The result is shown below:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2024-07-09T17:32:11.943+08:00| true| 24.941973|
|2024-07-09T17:32:12.944+08:00| true| 20.05108|
|2024-07-09T17:32:13.945+08:00| true| 20.541632|
|2024-07-09T17:32:14.945+08:00| null| 23.09016|
|2024-07-09T17:32:14.946+08:00| true| null|
+-----------------------------+------------------------+-----------------------------+
Total line number = 5
It costs 0.070s- Example 4: LIMIT clause combined with GROUP BY clause
The SQL statement is:
select count(status), max_value(temperature) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) limit 5 offset 3which means:
The SQL statement clause requires rows 3 to 7 of the query result be returned (with the first row numbered as row 0).
The result is shown below:
+-----------------------------+-------------------------------+----------------------------------------+
| Time|count(root.ln.wf01.wt01.status)|max_value(root.ln.wf01.wt01.temperature)|
+-----------------------------+-------------------------------+----------------------------------------+
|2017-11-04T00:00:00.000+08:00| 1440| 26.0|
|2017-11-05T00:00:00.000+08:00| 1440| 26.0|
|2017-11-06T00:00:00.000+08:00| 1440| 25.99|
|2017-11-07T00:00:00.000+08:00| 1380| 26.0|
+-----------------------------+-------------------------------+----------------------------------------+
Total line number = 4
It costs 0.016s7.2 Column Control over Query Results
By using SLIMIT and SOFFSET clauses, users can control the query results in a column-related manner. We will demonstrate how to use SLIMIT and SOFFSET clauses through the following examples.
- Example 1: basic SLIMIT clause
The SQL statement is:
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is the first column under this device, i.e., the power supply status. The SQL statement requires the status sensor values between the time point of "2017-11-01T00:05:00.000" and "2017-11-01T00:12:00.000" be selected.
The result is shown below:
+-----------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.temperature|
+-----------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| 20.71|
|2017-11-01T00:07:00.000+08:00| 21.45|
|2017-11-01T00:08:00.000+08:00| 22.58|
|2017-11-01T00:09:00.000+08:00| 20.98|
|2017-11-01T00:10:00.000+08:00| 25.52|
|2017-11-01T00:11:00.000+08:00| 22.91|
+-----------------------------+-----------------------------+
Total line number = 6
It costs 0.000s- Example 2: SLIMIT clause with SOFFSET
The SQL statement is:
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 1which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is the second column under this device, i.e., the temperature. The SQL statement requires the temperature sensor values between the time point of "2017-11-01T00:05:00.000" and "2017-11-01T00:12:00.000" be selected.
The result is shown below:
+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.status|
+-----------------------------+------------------------+
|2017-11-01T00:06:00.000+08:00| false|
|2017-11-01T00:07:00.000+08:00| false|
|2017-11-01T00:08:00.000+08:00| false|
|2017-11-01T00:09:00.000+08:00| false|
|2017-11-01T00:10:00.000+08:00| true|
|2017-11-01T00:11:00.000+08:00| false|
+-----------------------------+------------------------+
Total line number = 6
It costs 0.003s- Example 3: SLIMIT clause combined with GROUP BY clause
The SQL statement is:
select max_value(*) from root.ln.wf01.wt01 group by ([2017-11-01T00:00:00, 2017-11-07T23:00:00),1d) slimit 1 soffset 1The result is shown below:
+-----------------------------+-----------------------------------+
| Time|max_value(root.ln.wf01.wt01.status)|
+-----------------------------+-----------------------------------+
|2017-11-01T00:00:00.000+08:00| true|
|2017-11-02T00:00:00.000+08:00| true|
|2017-11-03T00:00:00.000+08:00| true|
|2017-11-04T00:00:00.000+08:00| true|
|2017-11-05T00:00:00.000+08:00| true|
|2017-11-06T00:00:00.000+08:00| true|
|2017-11-07T00:00:00.000+08:00| true|
+-----------------------------+-----------------------------------+
Total line number = 7
It costs 0.000s7.3 Row and Column Control over Query Results
In addition to row or column control over query results, IoTDB allows users to control both rows and columns of query results. Here is a complete example with both LIMIT clauses and SLIMIT clauses.
The SQL statement is:
select * from root.ln.wf01.wt01 limit 10 offset 100 slimit 2 soffset 0which means:
The selected device is ln group wf01 plant wt01 device; the selected timeseries is columns 0 to 1 under this device (with the first column numbered as column 0). The SQL statement clause requires rows 100 to 109 of the query result be returned (with the first row numbered as row 0).
The result is shown below:
+-----------------------------+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+-----------------------------+------------------------+
|2017-11-01T01:40:00.000+08:00| 21.19| false|
|2017-11-01T01:41:00.000+08:00| 22.79| false|
|2017-11-01T01:42:00.000+08:00| 22.98| false|
|2017-11-01T01:43:00.000+08:00| 21.52| false|
|2017-11-01T01:44:00.000+08:00| 23.45| true|
|2017-11-01T01:45:00.000+08:00| 24.06| true|
|2017-11-01T01:46:00.000+08:00| 22.6| false|
|2017-11-01T01:47:00.000+08:00| 23.78| true|
|2017-11-01T01:48:00.000+08:00| 24.72| true|
|2017-11-01T01:49:00.000+08:00| 24.68| true|
+-----------------------------+-----------------------------+------------------------+
Total line number = 10
It costs 0.009s7.4 Error Handling
If the parameter N/SN of LIMIT/SLIMIT exceeds the size of the result set, IoTDB returns all the results as expected. For example, the query result of the original SQL statement consists of six rows, and we select the first 100 rows through the LIMIT clause:
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 100The result is shown below:
+-----------------------------+------------------------+-----------------------------+
| Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+-----------------------------+------------------------+-----------------------------+
|2017-11-01T00:06:00.000+08:00| false| 20.71|
|2017-11-01T00:07:00.000+08:00| false| 21.45|
|2017-11-01T00:08:00.000+08:00| false| 22.58|
|2017-11-01T00:09:00.000+08:00| false| 20.98|
|2017-11-01T00:10:00.000+08:00| true| 25.52|
|2017-11-01T00:11:00.000+08:00| false| 22.91|
+-----------------------------+------------------------+-----------------------------+
Total line number = 6
It costs 0.005sIf the parameter N/SN of LIMIT/SLIMIT clause exceeds the allowable maximum value (N/SN is of type int64), the system prompts errors. For example, executing the following SQL statement:
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 9223372036854775808The SQL statement will not be executed and the corresponding error prompt is given as follows:
Msg: 416: Out of range. LIMIT <N>: N should be Int64.If the parameter N/SN of LIMIT/SLIMIT clause is not a positive intege, the system prompts errors. For example, executing the following SQL statement:
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 13.1The SQL statement will not be executed and the corresponding error prompt is given as follows:
Msg: 401: line 1:129 mismatched input '.' expecting {<EOF>, ';'}If the parameter OFFSET of LIMIT clause exceeds the size of the result set, IoTDB will return an empty result set. For example, executing the following SQL statement:
select status,temperature from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 limit 2 offset 6The result is shown below:
+----+------------------------+-----------------------------+
|Time|root.ln.wf01.wt01.status|root.ln.wf01.wt01.temperature|
+----+------------------------+-----------------------------+
+----+------------------------+-----------------------------+
Empty set.
It costs 0.005sIf the parameter SOFFSET of SLIMIT clause is not smaller than the number of available timeseries, the system prompts errors. For example, executing the following SQL statement:
select * from root.ln.wf01.wt01 where time > 2017-11-01T00:05:00.000 and time < 2017-11-01T00:12:00.000 slimit 1 soffset 2The SQL statement will not be executed and the corresponding error prompt is given as follows:
Msg: 411: Meet error in query process: The value of SOFFSET (2) is equal to or exceeds the number of sequences (2) that can actually be returned.8. ORDER BY CLAUSE
8.1 Order by in ALIGN BY TIME mode
The result set of IoTDB is in ALIGN BY TIME mode by default and ORDER BY TIME clause can also be used to specify the ordering of timestamp. The SQL statement is:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time desc;Results:
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
| Time|root.ln.wf02.wt02.hardware|root.ln.wf02.wt02.status|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+
|2017-11-01T00:01:00.000+08:00| v2| true| 24.36| true|
|2017-11-01T00:00:00.000+08:00| v2| true| 25.96| true|
|1970-01-01T08:00:00.002+08:00| v2| false| null| null|
|1970-01-01T08:00:00.001+08:00| v1| true| null| null|
+-----------------------------+--------------------------+------------------------+-----------------------------+------------------------+8.2 Order by in ALIGN BY DEVICE mode
When querying in ALIGN BY DEVICE mode, ORDER BY clause can be used to specify the ordering of result set.
ALIGN BY DEVICE mode supports four kinds of clauses with two sort keys which are Device and Time.
ORDER BY DEVICE: sort by the alphabetical order of the device name. The devices with the same column names will be clustered in a group view.ORDER BY TIME: sort by the timestamp, the data points from different devices will be shuffled according to the timestamp.ORDER BY DEVICE,TIME: sort by the alphabetical order of the device name. The data points with the same device name will be sorted by timestamp.ORDER BY TIME,DEVICE: sort by timestamp. The data points with the same time will be sorted by the alphabetical order of the device name.
To make the result set more legible, when
ORDER BYclause is not used, default settings will be provided. The default ordering clause isORDER BY DEVICE,TIMEand the default ordering isASC.
When Device is the main sort key, the result set is sorted by device name first, then by timestamp in the group with the same device name, the SQL statement is:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by device desc,time asc align by device;The result shows below:
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
+-----------------------------+-----------------+--------+------+-----------+When Time is the main sort key, the result set is sorted by timestamp first, then by device name in data points with the same timestamp. The SQL statement is:
select * from root.ln.** where time <= 2017-11-01T00:01:00 order by time asc,device desc align by device;The result shows below:
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
+-----------------------------+-----------------+--------+------+-----------+When ORDER BY clause is not used, sort in default way, the SQL statement is:
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;The result below indicates ORDER BY DEVICE ASC,TIME ASC is the clause in default situation. ASC can be omitted because it's the default ordering.
+-----------------------------+-----------------+--------+------+-----------+
| Time| Device|hardware|status|temperature|
+-----------------------------+-----------------+--------+------+-----------+
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| null| true| 25.96|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| true| 24.36|
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| v1| true| null|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| v2| false| null|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| v2| true| null|
+-----------------------------+-----------------+--------+------+-----------+Besides,ALIGN BY DEVICE and ORDER BY clauses can be used with aggregate query,the SQL statement is:
select count(*) from root.ln.** group by ((2017-11-01T00:00:00.000+08:00,2017-11-01T00:03:00.000+08:00],1m) order by device asc,time asc align by deviceThe result shows below:
+-----------------------------+-----------------+---------------+-------------+------------------+
| Time| Device|count(hardware)|count(status)|count(temperature)|
+-----------------------------+-----------------+---------------+-------------+------------------+
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| null| 1| 1|
|2017-11-01T00:02:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:03:00.000+08:00|root.ln.wf01.wt01| null| 0| 0|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| 1| 1| null|
|2017-11-01T00:02:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
|2017-11-01T00:03:00.000+08:00|root.ln.wf02.wt02| 0| 0| null|
+-----------------------------+-----------------+---------------+-------------+------------------+8.3 Order by arbitrary expressions
In addition to the predefined keywords "Time" and "Device" in IoTDB, ORDER BY can also be used to sort by any expressions.
When sorting, ASC or DESC can be used to specify the sorting order, and NULLS syntax is supported to specify the priority of NULL values in the sorting. By default, NULLS FIRST places NULL values at the top of the result, and NULLS LAST ensures that NULL values appear at the end of the result. If not specified in the clause, the default order is ASC with NULLS LAST.
Here are several examples of queries for sorting arbitrary expressions using the following data:
+-----------------------------+-------------+-------+-------+--------+-------+
| Time| Device| base| score| bonus| total|
+-----------------------------+-------------+-------+-------+--------+-------+
|1970-01-01T08:00:00.000+08:00| root.one| 12| 50.0| 45.0| 107.0|
|1970-01-02T08:00:00.000+08:00| root.one| 10| 50.0| 45.0| 105.0|
|1970-01-03T08:00:00.000+08:00| root.one| 8| 50.0| 45.0| 103.0|
|1970-01-01T08:00:00.010+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.020+08:00| root.two| 8| 10.0| 15.0| 33.0|
|1970-01-01T08:00:00.010+08:00| root.three| 9| null| 24.0| 33.0|
|1970-01-01T08:00:00.020+08:00| root.three| 8| null| 22.5| 30.5|
|1970-01-01T08:00:00.030+08:00| root.three| 7| null| 23.5| 30.5|
|1970-01-01T08:00:00.010+08:00| root.four| 9| 32.0| 45.0| 86.0|
|1970-01-01T08:00:00.020+08:00| root.four| 8| 32.0| 45.0| 85.0|
|1970-01-01T08:00:00.030+08:00| root.five| 7| 53.0| 44.0| 104.0|
|1970-01-01T08:00:00.040+08:00| root.five| 6| 54.0| 42.0| 102.0|
+-----------------------------+-------------+-------+-------+--------+-------+When you need to sort the results based on the base score score, you can use the following SQL:
select score from root.** order by score desc align by deviceThis will give you the following results:
+-----------------------------+---------+-----+
| Time| Device|score|
+-----------------------------+---------+-----+
|1970-01-01T08:00:00.040+08:00|root.five| 54.0|
|1970-01-01T08:00:00.030+08:00|root.five| 53.0|
|1970-01-01T08:00:00.000+08:00| root.one| 50.0|
|1970-01-02T08:00:00.000+08:00| root.one| 50.0|
|1970-01-03T08:00:00.000+08:00| root.one| 50.0|
|1970-01-01T08:00:00.000+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00| root.two| 10.0|
+-----------------------------+---------+-----+If you want to sort the results based on the total score, you can use an expression in the ORDER BY clause to perform the calculation:
select score,total from root.one order by base+score+bonus descThis SQL is equivalent to:
select score,total from root.one order by total descHere are the results:
+-----------------------------+--------------+--------------+
| Time|root.one.score|root.one.total|
+-----------------------------+--------------+--------------+
|1970-01-01T08:00:00.000+08:00| 50.0| 107.0|
|1970-01-02T08:00:00.000+08:00| 50.0| 105.0|
|1970-01-03T08:00:00.000+08:00| 50.0| 103.0|
+-----------------------------+--------------+--------------+If you want to sort the results based on the total score and, in case of tied scores, sort by score, base, bonus, and submission time in descending order, you can specify multiple layers of sorting using multiple expressions:
select base, score, bonus, total from root.** order by total desc NULLS Last,
score desc NULLS Last,
bonus desc NULLS Last,
time desc align by deviceHere are the results:
+-----------------------------+----------+----+-----+-----+-----+
| Time| Device|base|score|bonus|total|
+-----------------------------+----------+----+-----+-----+-----+
|1970-01-01T08:00:00.000+08:00| root.one| 12| 50.0| 45.0|107.0|
|1970-01-02T08:00:00.000+08:00| root.one| 10| 50.0| 45.0|105.0|
|1970-01-01T08:00:00.030+08:00| root.five| 7| 53.0| 44.0|104.0|
|1970-01-03T08:00:00.000+08:00| root.one| 8| 50.0| 45.0|103.0|
|1970-01-01T08:00:00.040+08:00| root.five| 6| 54.0| 42.0|102.0|
|1970-01-01T08:00:00.010+08:00| root.four| 9| 32.0| 45.0| 86.0|
|1970-01-01T08:00:00.020+08:00| root.four| 8| 32.0| 45.0| 85.0|
|1970-01-01T08:00:00.010+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.000+08:00| root.two| 9| 50.0| 15.0| 74.0|
|1970-01-01T08:00:00.020+08:00| root.two| 8| 10.0| 15.0| 33.0|
|1970-01-01T08:00:00.010+08:00|root.three| 9| null| 24.0| 33.0|
|1970-01-01T08:00:00.030+08:00|root.three| 7| null| 23.5| 30.5|
|1970-01-01T08:00:00.020+08:00|root.three| 8| null| 22.5| 30.5|
+-----------------------------+----------+----+-----+-----+-----+In the ORDER BY clause, you can also use aggregate query expressions. For example:
select min_value(total) from root.** order by min_value(total) asc align by deviceThis will give you the following results:
+----------+----------------+
| Device|min_value(total)|
+----------+----------------+
|root.three| 30.5|
| root.two| 33.0|
| root.four| 85.0|
| root.five| 102.0|
| root.one| 103.0|
+----------+----------------+When specifying multiple columns in the query, the unsorted columns will change order along with the rows and sorted columns. The order of rows when the sorting columns are the same may vary depending on the specific implementation (no fixed order). For example:
select min_value(total),max_value(base) from root.** order by max_value(total) desc align by deviceThis will give you the following results: ·
+----------+----------------+---------------+
| Device|min_value(total)|max_value(base)|
+----------+----------------+---------------+
| root.one| 103.0| 12|
| root.five| 102.0| 7|
| root.four| 85.0| 9|
| root.two| 33.0| 9|
|root.three| 30.5| 9|
+----------+----------------+---------------+You can use both ORDER BY DEVICE,TIME and ORDER BY EXPRESSION together. For example:
select score from root.** order by device asc, score desc, time asc align by deviceThis will give you the following results:
+-----------------------------+---------+-----+
| Time| Device|score|
+-----------------------------+---------+-----+
|1970-01-01T08:00:00.040+08:00|root.five| 54.0|
|1970-01-01T08:00:00.030+08:00|root.five| 53.0|
|1970-01-01T08:00:00.010+08:00|root.four| 32.0|
|1970-01-01T08:00:00.020+08:00|root.four| 32.0|
|1970-01-01T08:00:00.000+08:00| root.one| 50.0|
|1970-01-02T08:00:00.000+08:00| root.one| 50.0|
|1970-01-03T08:00:00.000+08:00| root.one| 50.0|
|1970-01-01T08:00:00.000+08:00| root.two| 50.0|
|1970-01-01T08:00:00.010+08:00| root.two| 50.0|
|1970-01-01T08:00:00.020+08:00| root.two| 10.0|
+-----------------------------+---------+-----+9. ALIGN BY CLAUSE
In addition, IoTDB supports another result set format: ALIGN BY DEVICE.
9.1 Align by Device
The ALIGN BY DEVICE indicates that the deviceId is considered as a column. Therefore, there are totally limited columns in the dataset.
NOTE:
1.You can see the result of 'align by device' as one relational table,
Time + Deviceis the primary key of this Table.2.The result is order by
Devicefirstly, and then byTimeorder.
The SQL statement is:
select * from root.ln.** where time <= 2017-11-01T00:01:00 align by device;The result shows below:
+-----------------------------+-----------------+-----------+------+--------+
| Time| Device|temperature|status|hardware|
+-----------------------------+-----------------+-----------+------+--------+
|2017-11-01T00:00:00.000+08:00|root.ln.wf01.wt01| 25.96| true| null|
|2017-11-01T00:01:00.000+08:00|root.ln.wf01.wt01| 24.36| true| null|
|1970-01-01T08:00:00.001+08:00|root.ln.wf02.wt02| null| true| v1|
|1970-01-01T08:00:00.002+08:00|root.ln.wf02.wt02| null| false| v2|
|2017-11-01T00:00:00.000+08:00|root.ln.wf02.wt02| null| true| v2|
|2017-11-01T00:01:00.000+08:00|root.ln.wf02.wt02| null| true| v2|
+-----------------------------+-----------------+-----------+------+--------+
Total line number = 6
It costs 0.012s9.2 Ordering in ALIGN BY DEVICE
ALIGN BY DEVICE mode arranges according to the device first, and sort each device in ascending order according to the timestamp. The ordering and priority can be adjusted through ORDER BY clause.
10. INTO CLAUSE (QUERY WRITE-BACK)
The SELECT INTO statement copies data from query result set into target time series.
The application scenarios are as follows:
- Implement IoTDB internal ETL: ETL the original data and write a new time series.
- Query result storage: Persistently store the query results, which acts like a materialized view.
- Non-aligned time series to aligned time series: Rewrite non-aligned time series into another aligned time series.
10.1 SQL Syntax
Syntax Definition
The following is the syntax definition of the select statement:
selectIntoStatement
: SELECT
resultColumn [, resultColumn] ...
INTO intoItem [, intoItem] ...
FROM prefixPath [, prefixPath] ...
[WHERE whereCondition]
[GROUP BY groupByTimeClause, groupByLevelClause]
[FILL {PREVIOUS | LINEAR | constant}]
[LIMIT rowLimit OFFSET rowOffset]
[ALIGN BY DEVICE]
;
intoItem
: [ALIGNED] intoDevicePath '(' intoMeasurementName [',' intoMeasurementName]* ')'
;INTO Clause
The INTO clause consists of several intoItem.
Each intoItem consists of a target device and a list of target measurements (similar to the INTO clause in an INSERT statement).
Each target measurement and device form a target time series, and an intoItem contains a series of time series. For example: root.sg_copy.d1(s1, s2) specifies two target time series root.sg_copy.d1.s1 and root.sg_copy.d1.s2.
The target time series specified by the INTO clause must correspond one-to-one with the columns of the query result set. The specific rules are as follows:
- Align by time (default): The number of target time series contained in all
intoItemmust be consistent with the number of columns in the query result set (except the time column) and correspond one-to-one in the order from left to right in the header. - Align by device (using
ALIGN BY DEVICE): the number of target devices specified in allintoItemis the same as the number of devices queried (i.e., the number of devices matched by the path pattern in theFROMclause), and One-to-one correspondence according to the output order of the result set device.
The number of measurements specified for each target device should be consistent with the number of columns in the query result set (except for the time and device columns). It should be in one-to-one correspondence from left to right in the header.
For examples:
- Example 1 (aligned by time)
IoTDB> select s1, s2 into root.sg_copy.d1(t1), root.sg_copy.d2(t1, t2), root.sg_copy.d1(t2) from root.sg.d1, root.sg.d2;
+--------------+-------------------+--------+
| source column| target timeseries| written|
+--------------+-------------------+--------+
| root.sg.d1.s1| root.sg_copy.d1.t1| 8000|
+--------------+-------------------+--------+
| root.sg.d2.s1| root.sg_copy.d2.t1| 10000|
+--------------+-------------------+--------+
| root.sg.d1.s2| root.sg_copy.d2.t2| 12000|
+--------------+-------------------+--------+
| root.sg.d2.s2| root.sg_copy.d1.t2| 10000|
+--------------+-------------------+--------+
Total line number = 4
It costs 0.725sThis statement writes the query results of the four time series under the root.sg database to the four specified time series under the root.sg_copy database. Note that root.sg_copy.d2(t1, t2) can also be written as root.sg_copy.d2(t1), root.sg_copy.d2(t2).
We can see that the writing of the INTO clause is very flexible as long as the combined target time series is not repeated and corresponds to the query result column one-to-one.
In the result set displayed by
CLI, the meaning of each column is as follows:
- The
source columncolumn represents the column name of the query result.target timeseriesrepresents the target time series for the corresponding column to write.writtenindicates the amount of data expected to be written.
- Example 2 (aligned by time)
IoTDB> select count(s1 + s2), last_value(s2) into root.agg.count(s1_add_s2), root.agg.last_value(s2) from root.sg.d1 group by ([0, 100), 10ms);
+--------------------------------------+-------------------------+--------+
| source column| target timeseries| written|
+--------------------------------------+-------------------------+--------+
| count(root.sg.d1.s1 + root.sg.d1.s2)| root.agg.count.s1_add_s2| 10|
+--------------------------------------+-------------------------+--------+
| last_value(root.sg.d1.s2)| root.agg.last_value.s2| 10|
+--------------------------------------+-------------------------+--------+
Total line number = 2
It costs 0.375sThis statement stores the results of an aggregated query into the specified time series.
- Example 3 (aligned by device)
IoTDB> select s1, s2 into root.sg_copy.d1(t1, t2), root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;
+--------------+--------------+-------------------+--------+
| source device| source column| target timeseries| written|
+--------------+--------------+-------------------+--------+
| root.sg.d1| s1| root.sg_copy.d1.t1| 8000|
+--------------+--------------+-------------------+--------+
| root.sg.d1| s2| root.sg_copy.d1.t2| 11000|
+--------------+--------------+-------------------+--------+
| root.sg.d2| s1| root.sg_copy.d2.t1| 12000|
+--------------+--------------+-------------------+--------+
| root.sg.d2| s2| root.sg_copy.d2.t2| 9000|
+--------------+--------------+-------------------+--------+
Total line number = 4
It costs 0.625sThis statement also writes the query results of the four time series under the root.sg database to the four specified time series under the root.sg_copy database. However, in ALIGN BY DEVICE, the number of intoItem must be the same as the number of queried devices, and each queried device corresponds to one intoItem.
When aligning the query by device, the result set displayed by
CLIhas one more column, thesource devicecolumn indicating the queried device.
- Example 4 (aligned by device)
IoTDB> select s1 + s2 into root.expr.add(d1s1_d1s2), root.expr.add(d2s1_d2s2) from root.sg.d1, root.sg.d2 align by device;
+--------------+--------------+------------------------+--------+
| source device| source column| target timeseries| written|
+--------------+--------------+------------------------+--------+
| root.sg.d1| s1 + s2| root.expr.add.d1s1_d1s2| 10000|
+--------------+--------------+------------------------+--------+
| root.sg.d2| s1 + s2| root.expr.add.d2s1_d2s2| 10000|
+--------------+--------------+------------------------+--------+
Total line number = 2
It costs 0.532sThis statement stores the result of evaluating an expression into the specified time series.
Using variable placeholders
In particular, We can use variable placeholders to describe the correspondence between the target and query time series, simplifying the statement. The following two variable placeholders are currently supported:
- Suffix duplication character
::: Copy the suffix (or measurement) of the query device, indicating that from this layer to the last layer (or measurement) of the device, the node name (or measurement) of the target device corresponds to the queried device The node name (or measurement) is the same. - Single-level node matcher
${i}: Indicates that the current level node name of the target sequence is the same as the i-th level node name of the query sequence. For example, for the pathroot.sg1.d1.s1,${1}meanssg1,${2}meansd1, and${3}meanss1.
When using variable placeholders, there must be no ambiguity in the correspondence between intoItem and the columns of the query result set. The specific cases are classified as follows:
ALIGN BY TIME (default)
Note: The variable placeholder can only describe the correspondence between time series. If the query includes aggregation and expression calculation, the columns in the query result cannot correspond to a time series, so neither the target device nor the measurement can use variable placeholders.
(1) The target device does not use variable placeholders & the target measurement list uses variable placeholders
Limitations:
- In each
intoItem, the length of the list of physical quantities must be 1.
(If the length can be greater than 1, e.g.root.sg1.d1(::, s1), it is not possible to determine which columns match::) - The number of
intoItemis 1, or the same as the number of columns in the query result set.
(When the length of each target measurement list is 1, if there is only oneintoItem, it means that all the query sequences are written to the same device; if the number ofintoItemis consistent with the query sequence, it is expressed as each query time series specifies a target device; ifintoItemis greater than one and less than the number of query sequences, it cannot be a one-to-one correspondence with the query sequence)
Matching method: Each query time series specifies the target device, and the target measurement is generated from the variable placeholder.
Example:
select s1, s2
into root.sg_copy.d1(::), root.sg_copy.d2(s1), root.sg_copy.d1(${3}), root.sg_copy.d2(::)
from root.sg.d1, root.sg.d2;This statement is equivalent to:
select s1, s2
into root.sg_copy.d1(s1), root.sg_copy.d2(s1), root.sg_copy.d1(s2), root.sg_copy.d2(s2)
from root.sg.d1, root.sg.d2;As you can see, the statement is not very simplified in this case.
(2) The target device uses variable placeholders & the target measurement list does not use variable placeholders
Limitations: The number of target measurements in all intoItem is the same as the number of columns in the query result set.
Matching method: The target measurement is specified for each query time series, and the target device is generated according to the target device placeholder of the intoItem where the corresponding target measurement is located.
Example:
select d1.s1, d1.s2, d2.s3, d3.s4
into ::(s1_1, s2_2), root.sg.d2_2(s3_3), root.${2}_copy.::(s4)
from root.sg;(3) The target device uses variable placeholders & the target measurement list uses variable placeholders
Limitations: There is only one intoItem, and the length of the list of measurement list is 1.
Matching method: Each query time series can get a target time series according to the variable placeholder.
Example:
select * into root.sg_bk.::(::) from root.sg.**;Write the query results of all time series under root.sg to root.sg_bk, the device name suffix and measurement remain unchanged.
ALIGN BY DEVICE
Note: The variable placeholder can only describe the correspondence between time series. If the query includes aggregation and expression calculation, the columns in the query result cannot correspond to a specific physical quantity, so the target measurement cannot use variable placeholders.
(1) The target device does not use variable placeholders & the target measurement list uses variable placeholders
Limitations: In each intoItem, if the list of measurement uses variable placeholders, the length of the list must be 1.
Matching method: Each query time series specifies the target device, and the target measurement is generated from the variable placeholder.
Example:
select s1, s2, s3, s4
into root.backup_sg.d1(s1, s2, s3, s4), root.backup_sg.d2(::), root.sg.d3(backup_${4})
from root.sg.d1, root.sg.d2, root.sg.d3
align by device;(2) The target device uses variable placeholders & the target measurement list does not use variable placeholders
Limitations: There is only one intoItem. (If there are multiple intoItem with placeholders, we will not know which source devices each intoItem needs to match)
Matching method: Each query device obtains a target device according to the variable placeholder, and the target measurement written in each column of the result set under each device is specified by the target measurement list.
Example:
select avg(s1), sum(s2) + sum(s3), count(s4)
into root.agg_${2}.::(avg_s1, sum_s2_add_s3, count_s4)
from root.**
align by device;(3) The target device uses variable placeholders & the target measurement list uses variable placeholders
Limitations: There is only one intoItem and the length of the target measurement list is 1.
Matching method: Each query time series can get a target time series according to the variable placeholder.
Example:
select * into ::(backup_${4}) from root.sg.** align by device;Write the query result of each time series in root.sg to the same device, and add backup_ before the measurement.
Specify the target time series as the aligned time series
We can use the ALIGNED keyword to specify the target device for writing to be aligned, and each intoItem can be set independently.
Example:
select s1, s2 into root.sg_copy.d1(t1, t2), aligned root.sg_copy.d2(t1, t2) from root.sg.d1, root.sg.d2 align by device;This statement specifies that root.sg_copy.d1 is an unaligned device and root.sg_copy.d2 is an aligned device.
Unsupported query clauses
SLIMIT,SOFFSET: The query columns are uncertain, so they are not supported.LAST,GROUP BY TAGS,DISABLE ALIGN: The table structure is inconsistent with the writing structure, so it is not supported.
Other points to note
- For general aggregation queries, the timestamp is meaningless, and the convention is to use 0 to store.
- When the target time-series exists, the data type of the source column and the target time-series must be compatible. About data type compatibility, see the document [Data Type](../Background-knowledge/Data-Type.md#Data Type Compatibility).
- When the target time series does not exist, the system automatically creates it (including the database).
- When the queried time series does not exist, or the queried sequence does not have data, the target time series will not be created automatically.
10.2 Application examples
Implement IoTDB internal ETL
ETL the original data and write a new time series.
IOTDB > SELECT preprocess_udf(s1, s2) INTO ::(preprocessed_s1, preprocessed_s2) FROM root.sg.* ALIGN BY DEIVCE;
+--------------+-------------------+---------------------------+--------+
| source device| source column| target timeseries| written|
+--------------+-------------------+---------------------------+--------+
| root.sg.d1| preprocess_udf(s1)| root.sg.d1.preprocessed_s1| 8000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d1| preprocess_udf(s2)| root.sg.d1.preprocessed_s2| 10000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d2| preprocess_udf(s1)| root.sg.d2.preprocessed_s1| 11000|
+--------------+-------------------+---------------------------+--------+
| root.sg.d2| preprocess_udf(s2)| root.sg.d2.preprocessed_s2| 9000|
+--------------+-------------------+---------------------------+--------+Query result storage
Persistently store the query results, which acts like a materialized view.
IOTDB > SELECT count(s1), last_value(s1) INTO root.sg.agg_${2}(count_s1, last_value_s1) FROM root.sg1.d1 GROUP BY ([0, 10000), 10ms);
+--------------------------+-----------------------------+--------+
| source column| target timeseries| written|
+--------------------------+-----------------------------+--------+
| count(root.sg.d1.s1)| root.sg.agg_d1.count_s1| 1000|
+--------------------------+-----------------------------+--------+
| last_value(root.sg.d1.s2)| root.sg.agg_d1.last_value_s2| 1000|
+--------------------------+-----------------------------+--------+
Total line number = 2
It costs 0.115sNon-aligned time series to aligned time series
Rewrite non-aligned time series into another aligned time series.
Note: It is recommended to use the LIMIT & OFFSET clause or the WHERE clause (time filter) to batch data to prevent excessive data volume in a single operation.
IOTDB > SELECT s1, s2 INTO ALIGNED root.sg1.aligned_d(s1, s2) FROM root.sg1.non_aligned_d WHERE time >= 0 and time < 10000;
+--------------------------+----------------------+--------+
| source column| target timeseries| written|
+--------------------------+----------------------+--------+
| root.sg1.non_aligned_d.s1| root.sg1.aligned_d.s1| 10000|
+--------------------------+----------------------+--------+
| root.sg1.non_aligned_d.s2| root.sg1.aligned_d.s2| 10000|
+--------------------------+----------------------+--------+
Total line number = 2
It costs 0.375s10.3 User Permission Management
The user must have the following permissions to execute a query write-back statement:
- All
WRITE_SCHEMApermissions for the source series in theselectclause. - All
WRITE_DATApermissions for the target series in theintoclause.
For more user permissions related content, please refer to Account Management Statements.
10.4 Configurable Properties
select_into_insert_tablet_plan_row_limit: The maximum number of rows can be processed in one insert-tablet-plan when executing select-into statements. 10000 by default.