

Introduction of Timer
As AI continues to permeate industrial systems, the role of time series data has evolved beyond basic querying and analytics toward more advanced tasks such as equipment state forecasting and intelligent imputation of missing data. Achieving high-precision forecasting in these scenarios increasingly depends on foundation models that are purpose-built for time series characteristics.
However, unlike text, images, or video, time series data presents unique challenges: high variability, stochasticity, and complex temporal dependencies. These factors significantly limit the generalization and scalability of traditional models. As a result, developing domain-specific foundation models for time series has become a central focus in both academia and industry.
To address these challenges, the research team from Tsinghua University, in collaboration with ByteDance, introduces Timer-S1, the latest advancement in the Timer model series (Timer 1.0–3.0). Timer-S1 is the first time series foundation model scaled to billions of parameters, with a context length of up to 11.5K time steps. It achieves state-of-the-art (SOTA) forecasting performance on the large-scale benchmark GIFT-Eval.
The accompanying paper, "Timer-S1: A Billion-Scale Time Series Foundation Model with Serial Scaling," presents the technical details. In this article, we break down the key innovations behind Timer-S1.
Core Challenges in Time Series Foundation Models
Building foundation models for time series involves several fundamental challenges:
Strong Data Heterogeneity
Time series data varies significantly across domains in terms of frequency, distribution, and structure. Capturing multi-scale dependencies in high-dimensional, often unstructured signals remains difficult.
Intrinsic Uncertainty
Real-world time series are typically non-stationary and stochastic. External factors and system dynamics can introduce abrupt distribution shifts, increasing prediction uncertainty.
Scalability Constraints
Scaling techniques widely used in large language models—such as Mixture-of-Experts (MoE)—do not directly translate well to time series, often leading to degraded performance. Balancing sequential dependency modeling with computational efficiency remains a bottleneck.
Training–Inference Gap
Autoregressive models align well with the sequential nature of time series, but suffer from high computational cost and error accumulation during iterative inference. On the other hand, parallel multi-step prediction improves efficiency but fails to capture long-term dependencies.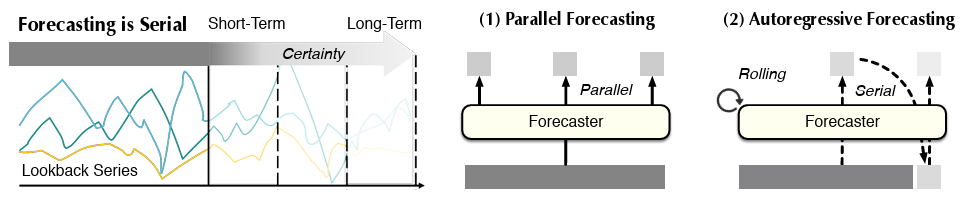 (Figure 1: Long-Horizon Forecasting Accumulates Uncertainty: Each Prediction Depends on Prior Estimates, Making Time Series Forecasting Inherently Sequential)
(Figure 1: Long-Horizon Forecasting Accumulates Uncertainty: Each Prediction Depends on Prior Estimates, Making Time Series Forecasting Inherently Sequential)
Timer-S1 is designed as a systematic response to these challenges.
Core Innovation of Timer-S1: The Serial Scaling Paradigm
The key contribution of Timer-S1 is the introduction of a serial scaling paradigm, which integrates the sequential nature of time series forecasting into three tightly coupled dimensions: model architecture, dataset construction, and training pipeline.
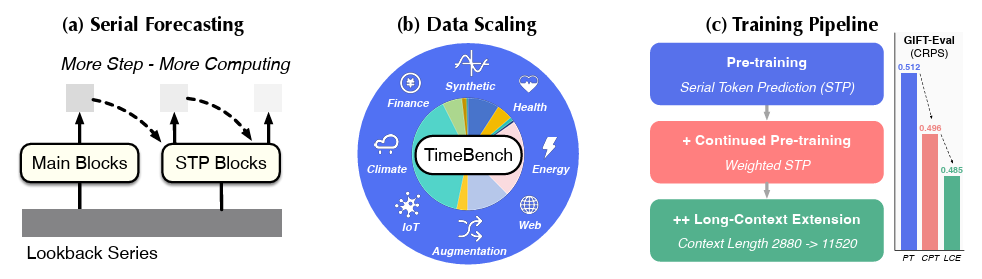 (Figure 2: The Serial Scaling Paradigm in Timer-S1, Spanning Three Dimensions - Serial Forecasting, Data Scaling, and Post-Training)
(Figure 2: The Serial Scaling Paradigm in Timer-S1, Spanning Three Dimensions - Serial Forecasting, Data Scaling, and Post-Training)
Architecture Design: Efficient Serial Forecasting
Timer-S1 is built on a decoder-only Transformer backbone, enhanced with two specialized modules:
TimeMoE Block
A sparse Mixture-of-Experts module tailored for global heterogeneity in time series. It dynamically routes different temporal patterns to specialized experts, enabling:
Scalable training up to 8.3 billion parameters
Improved training stability
Efficient inference despite large model size
TimeSTP Block (Serial Token Prediction)
The core innovation for sequential forecasting. TimeSTP introduces progressive, step-wise prediction within a single forward pass:
TimeSTP is a time-series modeling approach that captures temporal dependencies in sequential data to enable accurate forecasting and pattern analysis.
Iteratively generates multi-step forecasts using historical inputs and intermediate representations
Eliminates the need for autoregressive rolling inference
Reduces error accumulation while significantly improving inference efficiency
Unified Forecasting Head
A shared quantile prediction head that supports multiple output formulations (e.g., linear projection, diffusion-based heads), ensuring architectural flexibility.
The Timer-S1 Model increased additional techniques include:
Instance-wise re-normalization to handle scale variations across datasets
Patch-level tokenization, converting continuous time points into model-friendly tokens
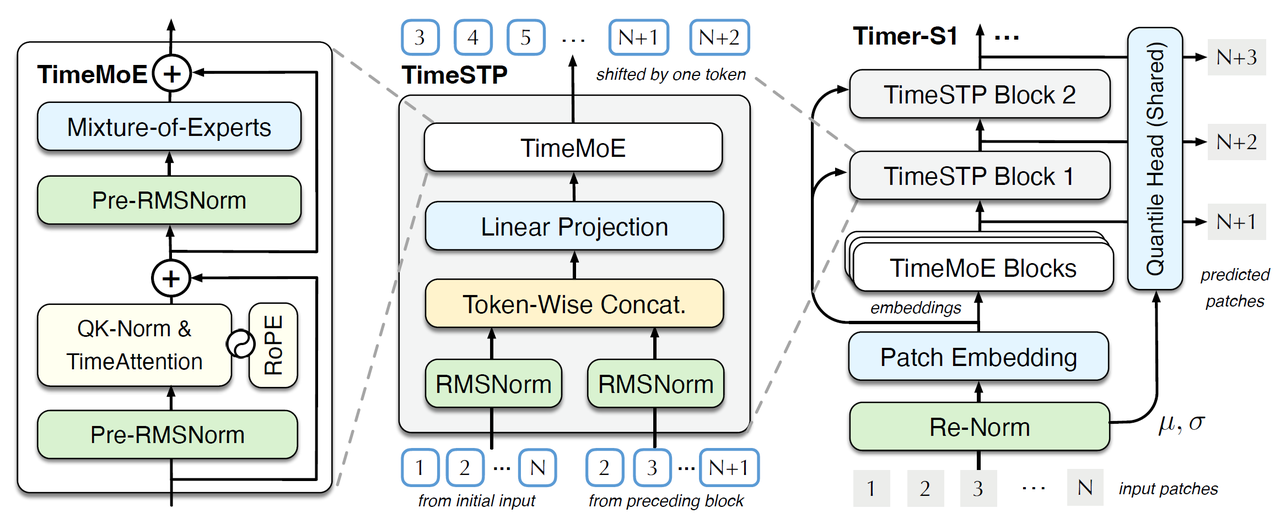 (Figure 3: The Architecture of Timer-S1)
(Figure 3: The Architecture of Timer-S1)
Data Construction: A Trillion-Point Time Series Corpus
To support large-scale training, the team constructed TimeBench, a dataset containing 1 trillion time points.
Key features include:
Multi-Source Data Integration
Combines real-world datasets from finance, IoT, meteorology, and healthcare, along with public benchmarks (e.g., Chronos, LOTSA), and synthetic signals (linear, sinusoidal, exponential).
Strict Data Quality Control
Missing values handled via causal mean imputation
Outliers removed using sliding-window detection
Data leakage prevention through rigorous filtering
Targeted Data Augmentation
Resampling
Value flipping
These techniques reduce prediction bias and improve generalization.
Data Complexity Evaluation
Each dataset is profiled using:
ADF stationarity tests
Spectral entropy-based predictability metrics
This results in a structured "complexity plane" for fine-grained dataset selection.
Training Pipeline: Optimizing Short and Long-Term Forecasting
Timer-S1 adopts a multi-stage training strategy instead of a single-phase approach:
Pretraining
Dense supervision across varying input-output lengths using STP as the core objective, enabling strong representation learning and multi-steps forecasting ability.
Continued Pretraining
Introduces a weighted STP objective to prioritize short-term accuracy (critical for long-horizon forecasting), combined with replay-based sampling to prevent overfitting.
Long-Context Extension
Using RoPE (Rotary Positional Embedding), the context length is extended from 2,880 to 11,520 time steps, significantly improving long-range dependency modeling.
The training system supports:
Billion-scale distributed training
Hybrid memory–disk data loading for efficient trillion-scale data access
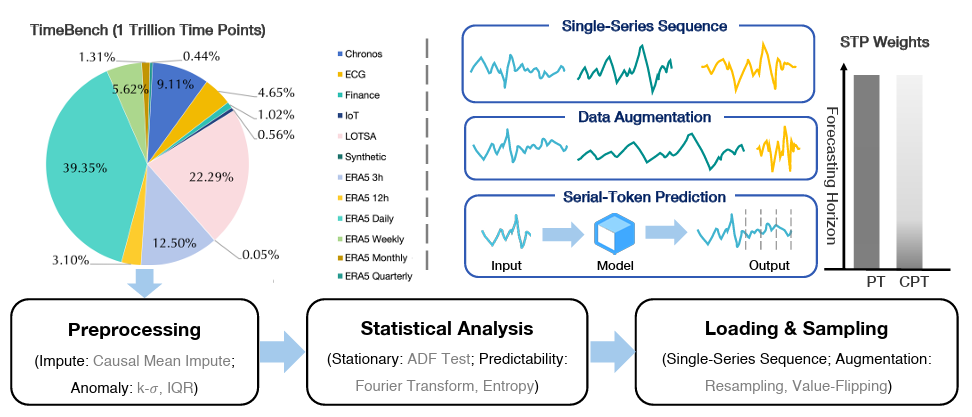 (Figure 4: Overview of the TimeBench Dataset and the Timer-S1 Training Pipeline)
(Figure 4: Overview of the TimeBench Dataset and the Timer-S1 Training Pipeline)
Benchmark Results: SOTA on GIFT-Eval
Timer-S1 is evaluated on GIFT-Eval, a comprehensive benchmark with:
24 datasets
144,000 time series
177 million data points
Key Results:
Overall SOTA Performance
MASE ↓ 7.6% (Mean Absolute Scaled Error)
CRPS ↓ 13.2% (Continuous Ranked Probability Score)
Compared to Timer-3 (trained on the same TimeBench dataset), these results demonstrate the effectiveness of the serial scaling paradigm.
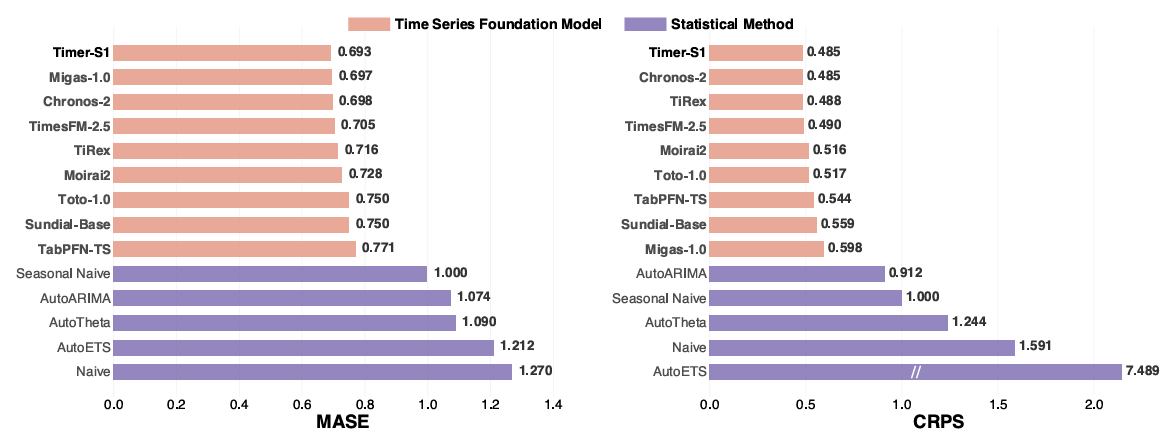 (Figure 5: Performance of Timer-S1 on the GIFT-Eval Leaderboard)
(Figure 5: Performance of Timer-S1 on the GIFT-Eval Leaderboard)
Strong Mid- and Long-Horizon Forecasting
Performance gains are especially pronounced for longer prediction horizons, validating the effectiveness of serial modeling in capturing long-term dependencies.
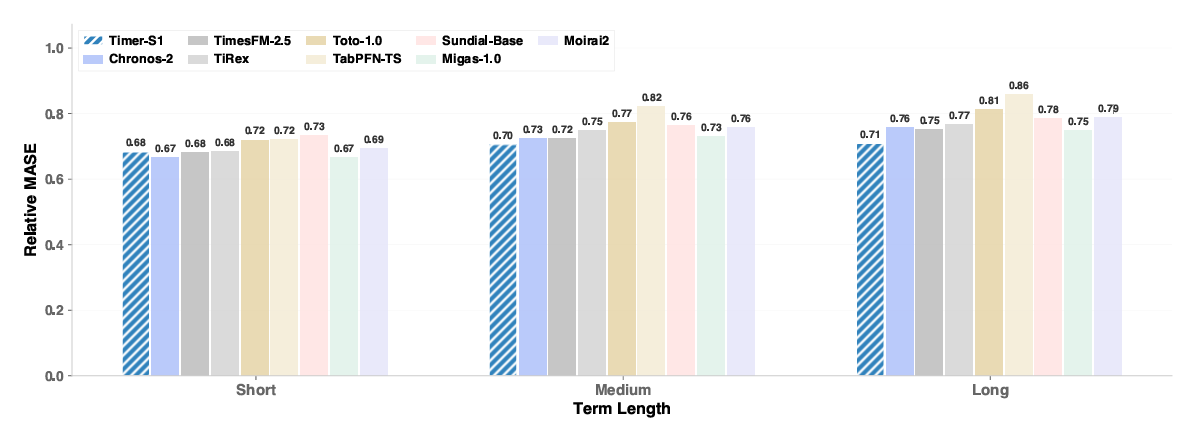 (Figure 6: MASE Comparison Across Different Forecasting Horizons: Timer-S1 Shows Significant Advantages in Mid- and Long-Term Forecasting Tasks)
(Figure 6: MASE Comparison Across Different Forecasting Horizons: Timer-S1 Shows Significant Advantages in Mid- and Long-Term Forecasting Tasks)
Significant Gains from Post-Training
Multi-stage training (include pretraining, continous pretraining and long context expansion) significantly outperforms single-stage pretraining, confirming the importance of decoupled optimization objectives.
 (Figure 7: Performance Comparison Across Different Training Pipelines in Timer-S1)
(Figure 7: Performance Comparison Across Different Training Pipelines in Timer-S1)
STP vs. NTP/MTP
Under the same compute budget:
STP outperforms both Next Token Prediction (NTP) and Multi-Token Prediction (MTP)
Achieves better accuracy with lower inference latency
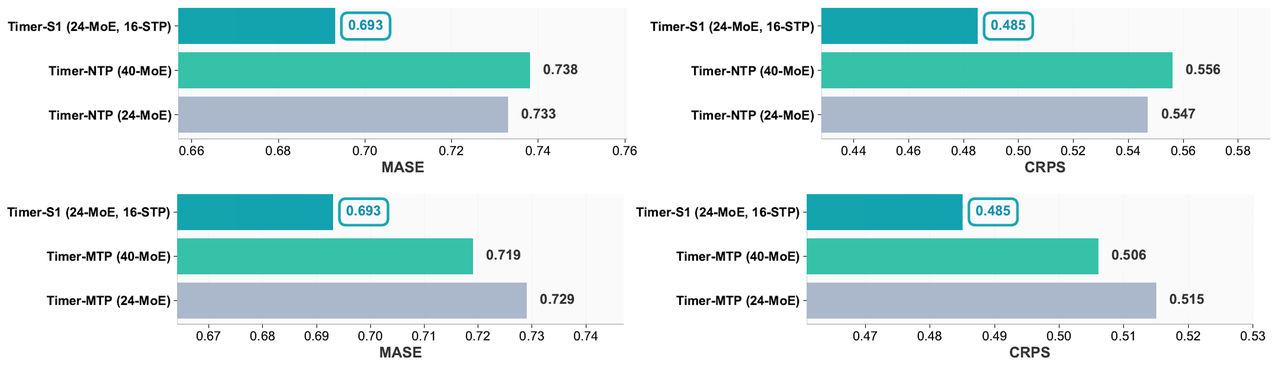 (Figure 8: TPerformance Comparison Between NTP, MTP, and STP)
(Figure 8: TPerformance Comparison Between NTP, MTP, and STP)
Ablation Studies: Core Component is Essential
Extensive ablation experiments highlight the importance of each component:
TimeSTP Design Matters Removing TimeSTP during inference or reverting to autoregressive rolling prediction leads to substantial performance degradation. The current design effectively narrows the gap between training and inference, adapting to the distribution characteristics of time series.
 (Figure 9: Performance Comparison Across Different TimeSTP Variants in Timer-S1)
(Figure 9: Performance Comparison Across Different TimeSTP Variants in Timer-S1)
Data Augmentation is Critical Eliminating augmentation strategies (resampling and value flipping) increases prediction bias and reduces generalization, which validates the necessity of data augmentation in alleviating time series distribution imbalance.
 (Figure 10: Impact of Data Augmentation on Timer-S1 Performance)
(Figure 10: Impact of Data Augmentation on Timer-S1 Performance)
Pretraining Enables Transferability Models trained from scratch perform significantly worse, demonstrating strong cross-task knowledge transfer from TimeBench.
 (Figure 11: Impact of TimeBench Pretraining on Timer-S1 Performance)
(Figure 11: Impact of TimeBench Pretraining on Timer-S1 Performance)
Scaling Still Works Optimal performance is achieved with 24 TimeMoE blocks + 16 TimeSTP blocks, confirming that billion-scale expansion continues to yield gains.
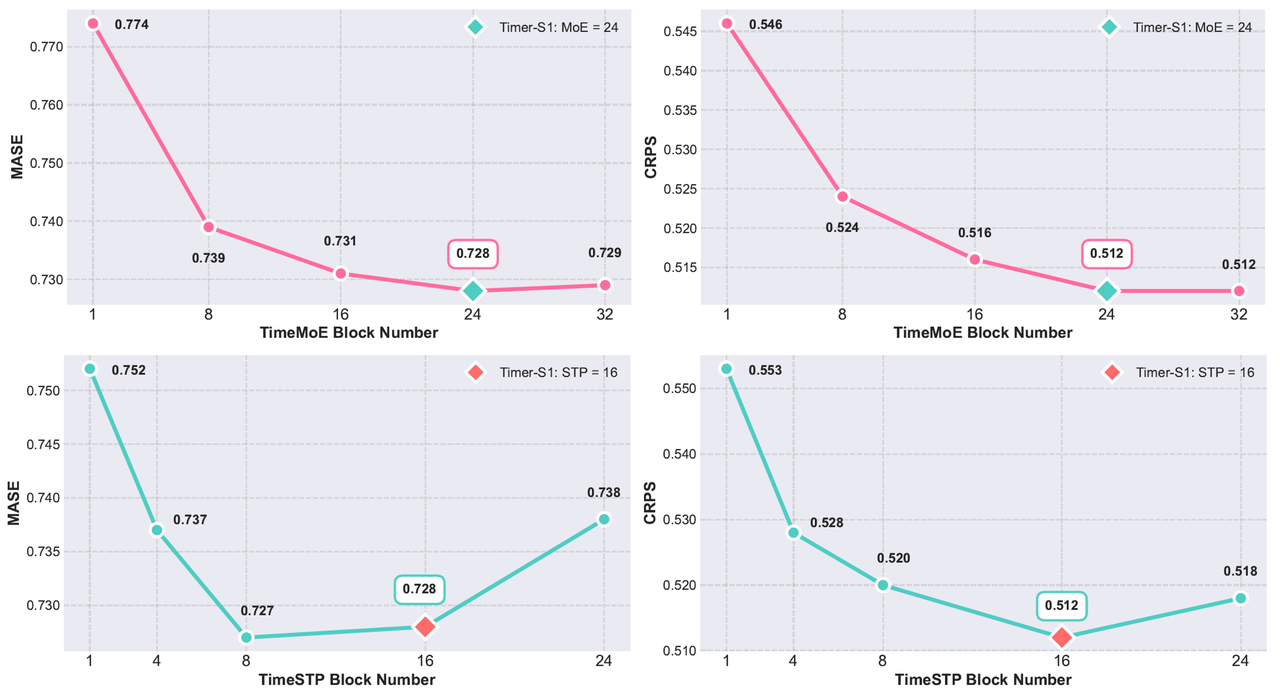 (Figure 12: Pretraining Performance Under Different Numbers of TimeMoE and TimeSTP Blocks)
(Figure 12: Pretraining Performance Under Different Numbers of TimeMoE and TimeSTP Blocks)
Conclusion
Timer-S1 represents a major step forward in scaling time series foundation models to the billion-parameter regime. Its serial scaling paradigm systematically integrates the sequential nature of time series into architecture, data, and training, offering a generalizable solution to long-standing scalability challenges.
With innovations such as TimeBench, multi-stage training, and the TimeSTP module, Timer-S1 provides a reusable technical framework for future research and industrial deployment.
The release of Timer-S1 is not an endpoint, but a new milestone. Continued advancements in generalization and real-world applicability will further unlock the potential of time series intelligence across industries.


