

A Covariate Forecasting Framework with TimechoDB AINode
In industrial time-series forecasting scenarios, accurate trend prediction often serves as a critical foundation for operational decision-making. However, traditional univariate forecasting approaches struggle to fully capture the complexity of real-world systems.
Take electricity pricing as an example. Power prices are not determined solely by historical price patterns. They are also influenced by a variety of external factors, including temperature, wind speed, holidays, and energy supply structure. Similar multivariate dependencies exist across many industries, such as manufacturing, transportation, and energy systems.
As the scale and complexity of time-series data continue to grow, forecasting is no longer purely an algorithmic problem. Increasingly, it requires tight integration between data infrastructure and model capabilities.
In TimechoDB, we significantly enhanced the capabilities of AINode, the database's intelligent analysis node. The upgrade enables native deployment and inference of Transformer-based time-series models, while introducing a framework for covariate-aware forecasting tasks.
With this capability, users can integrate different types of time-series foundation models directly into the database, enabling a unified workflow that spans data management, model execution, and predictive analytics.
What Are Covariates and Covariate Forecasting?
To understand covariate forecasting, it is important to first clarify two core concepts.
Covariates
Covariates are variables that are strongly correlated with the target variable and can provide additional information useful for prediction.
For example, in electricity price forecasting:
Temperature
Wind speed
Holiday indicators
...
influence fluctuations in power prices. These variables can therefore be used as covariates during model training and inference.
Covariate Forecasting
Unlike univariate forecasting methods, covariate forecasting combines:
Historical data of the target variable
Historical data of covariates
Partially known future covariate values
to jointly model future trends.
Instead of relying on a single time series, the model learns from the dynamic relationships across multiple data dimensions, allowing it to better reflect the underlying behavior of real-world systems.
 By incorporating covariate information, forecasting models can move beyond the limitations of single-signal prediction. In many industrial applications, this leads to significantly improved prediction accuracy and stability.
By incorporating covariate information, forecasting models can move beyond the limitations of single-signal prediction. In many industrial applications, this leads to significantly improved prediction accuracy and stability.
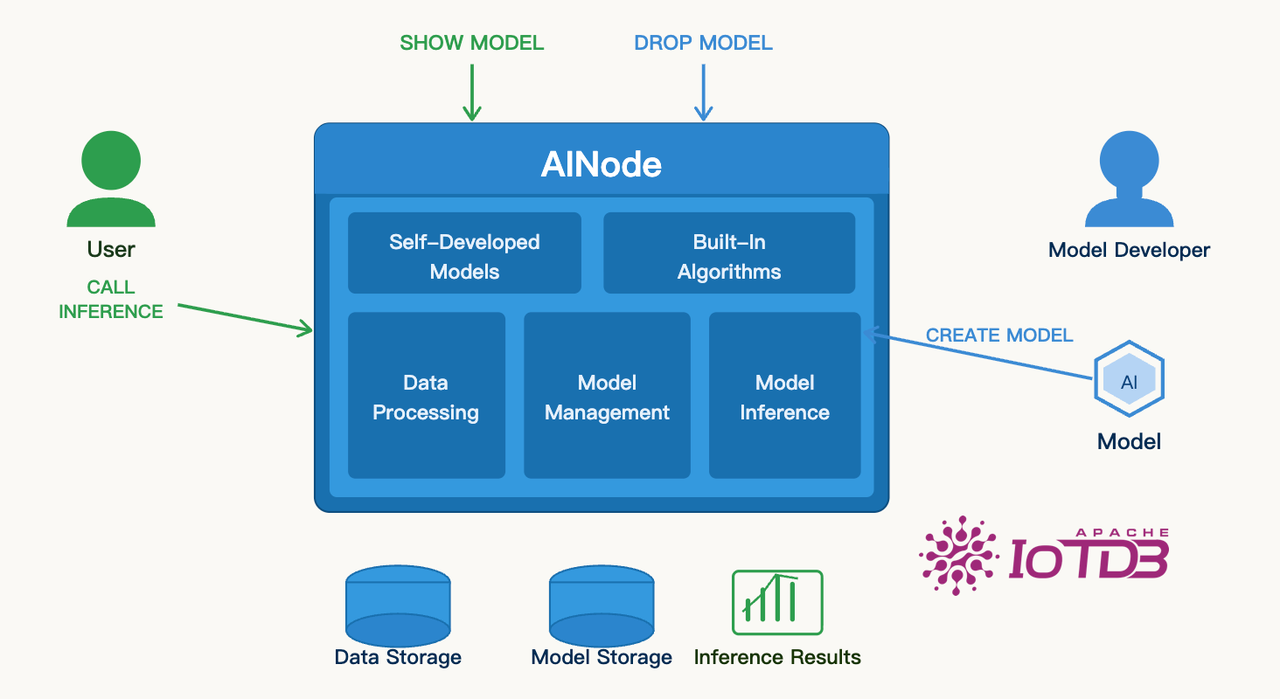
AINode: A Database-Native Intelligent Analysis Node
To better integrate forecasting capabilities with data infrastructure, TimechoDB introduced a major upgrade to AINode in version 2.0.8.
AINode is designed to transform the database from a pure data management system into a platform that can also host model deployment and inference workloads. This enables predictive analytics to run directly within the database environment.
In this release, AINode provides a unified model integration mechanism that allows the database to deploy a variety of Transformer-based time-series models, including:
Timer
Chronos
Moirai
...
Model training can still be performed outside the database for maximum flexibility. However, model deployment, inference execution, and task scheduling are centrally managed within the database.
With this architecture, forecasting tasks can directly:
Read data from the database
Invoke the prediction model
Generate forecast results
 This eliminates the frequent data exports and system switching common in traditional forecasting pipelines.
This eliminates the frequent data exports and system switching common in traditional forecasting pipelines.
As a result, the database evolves from a standalone data store into an infrastructure layer that enables collaboration between data and AI workloads.
Native Forecasting with SQL
In many forecasting tools, covariates must be manually passed as parameters. Users often need to input covariate values one by one in SQL queries or construct them via string concatenation.
This approach introduces several issues:
Complex operational workflows
Higher risk of parameter input errors
Limited integration with existing data query processes
TimechoDB optimizes this process by allowing covariate inputs to be directly queried from the database using SQL. This makes forecasting tasks a natural extension of standard data query workflows.
A typical covariate forecasting call looks like the following:
SELECT * FROM FORECAST (
MODEL_ID => 'chronos2',
TARGETS => (
SELECT TIME, target1, target2
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6
),
HISTORY_COVS => (
SELECT TIME, cov1, cov2, cov3
FROM etth.tab_real
WHERE TIME < 7
ORDER BY TIME DESC
LIMIT 6
),
FUTURE_COVS => (
SELECT TIME, cov1
FROM etth.tab_real
WHERE TIME >= 7
LIMIT 2
),
OUTPUT_LENGTH => 2
);With this approach:
Target variables and covariates both come directly from database queries
No manual parameter concatenation is required
Forecasting workflows become significantly easier to implement
This greatly lowers the operational barrier for deploying forecasting tasks.
Industrial Case Study: Covariate Forecasting for Electricity Prices
Covariate forecasting is not only a theoretical capability — it also delivers measurable benefits in real industrial scenarios.
In a real-world electricity price forecasting task, we validated the covariate forecasting framework under production conditions.
The goal was to predict electricity price trends. However, electricity prices are influenced by many interacting factors, including:
Meteorological conditions
Time-related patterns
Energy supply structures
In addition, extreme price spikes are notoriously difficult to predict.
During the modeling process, the business team initially identified more than 100 potential covariates. After multiple rounds of data cleaning and feature selection, over 20 key variables were retained for the final model.
These variables can be broadly grouped into three categories:
Time-related variables, such as date, weekday indicators, and holiday indicators, which capture periodic patterns in electricity demand.
Weather-related variables, including temperature, wind speed, precipitation, and cloud coverage, all of which can significantly influence energy consumption and renewable generation.
Energy-related variables, such as solar power generation, wind power output, and energy conversion efficiency, reflecting the supply-side dynamics of the energy system.
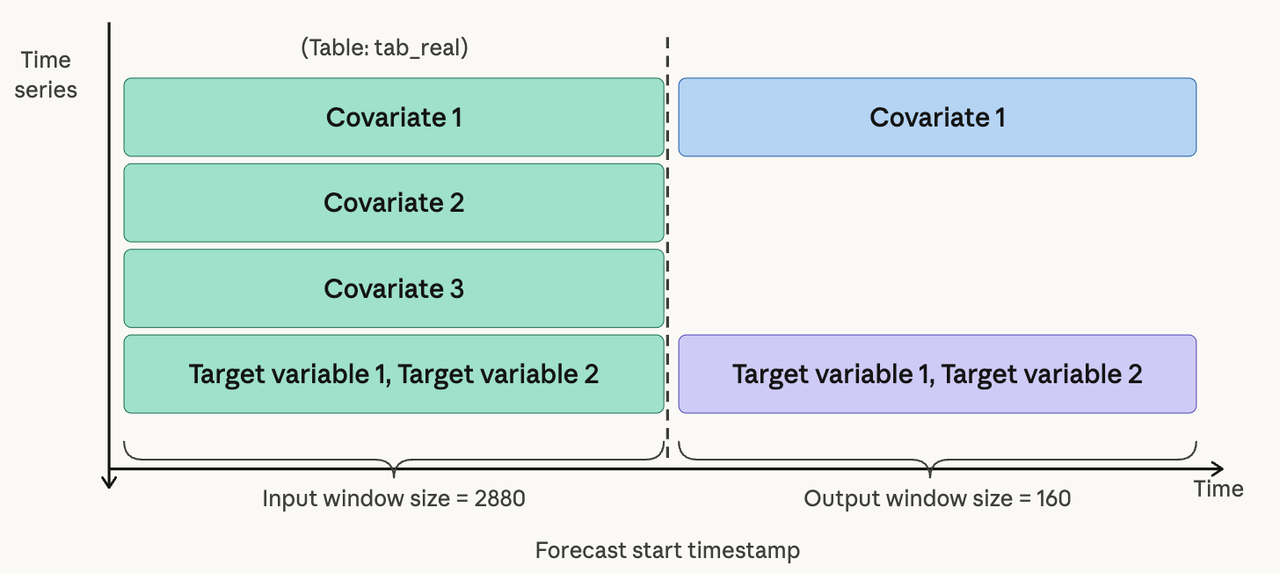
During forecasting, the model simultaneously consumes:
2,880 historical timestamps (~30 days) of target variables and covariates
160 future timestamps(~40 hours) of known covariate information
We implemented a covariate-enhanced forecasting approach built on top of open-source time-series foundation models and compared it against several baseline models.
The experimental results show that in complex multivariate environments, incorporating covariate modeling allows prediction curves to capture real trend changes more accurately. The covariate-enhanced model outperformed baseline models in:
Peak prediction accuracy
Trend tracking
Overall stability
In particular, the FutureBoosting covariate-enhanced model was able to better align with actual series behavior during key trend transitions.
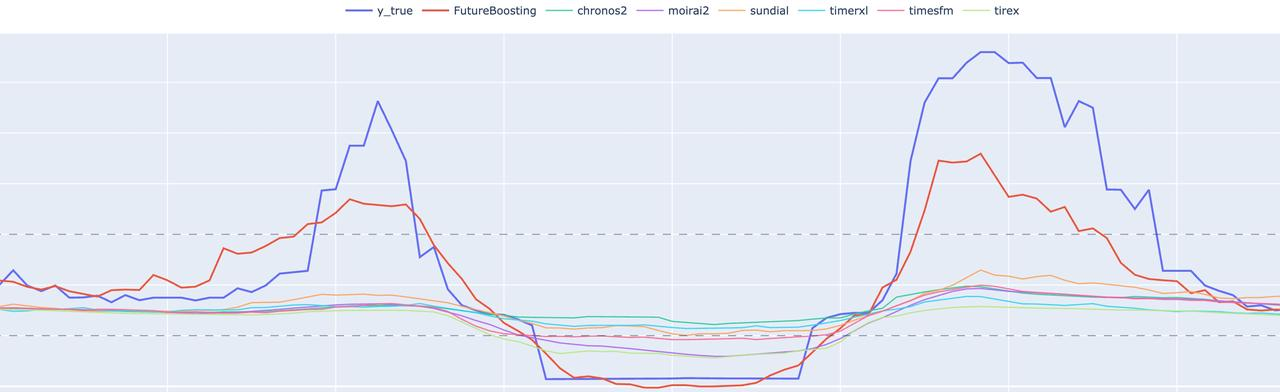
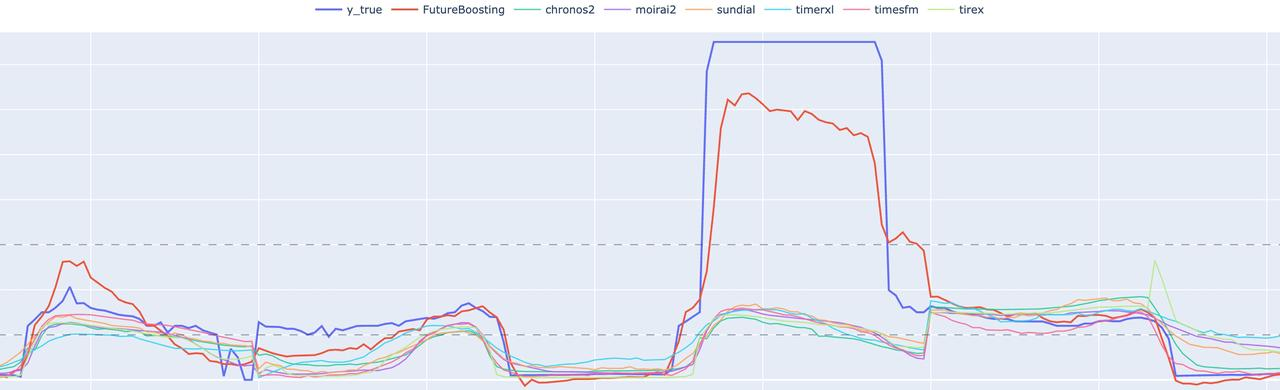
Multi-model forecasting comparison: the covariate-enhanced approach (FutureBoosting) aligns more closely with the ground-truth series, particularly during major trend shifts.
Conclusion
In TimechoDB v2.0.8, we introduced a major upgrade to AINode, enabling the database to deploy and run Transformer-based time-series models while providing a framework for covariate forecasting tasks.
With this capability, organizations can centrally manage:
Model deployment
Forecasting task scheduling
Data access
all within the database environment.
This architecture enables an integrated workflow that spans data management and intelligent analytics.
As time-series foundation models continue to evolve, the collaboration between databases and AI models will increasingly become a key direction for next-generation time-series data systems. Databases are gradually evolving into critical infrastructure for time-series AI applications.


