

In the Internet of Things (IoT) domain, data collection, storage, and analysis play a critical role in ensuring system efficiency and accurate decision-making. With the rapid growth of IoT devices and the exponential increase in data volume, developers and decision-makers face the challenge of selecting suitable time-series data management systems. Apache IoTDB and Apache HBase are two widely used databases, each with unique strengths in architecture, performance, and functionality.
To assist users in making informed decisions for time-series applications, this article provides an in-depth comparison of Apache IoTDB and Apache HBase across five dimensions: distributed architecture, edge-cloud synchronization, deployment ease, analytics capabilities, and performance.
Overview
Apache IoTDB (Internet of Things Database) is an Apache top-level project originating from Tsinghua University. It is specifically designed as an efficient and scalable time-series database tailored for IoT and industrial big data scenarios. Apache HBase is a high-performance, column-oriented distributed NoSQL database built on Google's BigTable architecture and runs within the Hadoop ecosystem. It uses Hadoop Distributed File System (HDFS) for data storage and Zookeeper for distributed coordination.
Comparison Dimension 1: Distributed Architecture
Apache IoTDB natively supports distributed systems and incorporates extensive optimizations tailored to IoT scenarios, maximizing cluster availability, scalability, and performance.
Partitioning and Load Balancing: IoTDB is designed to handle frequent operations on recent data and relatively fewer operations on historical data in most time-series scenarios.
This approach ensures lightweight maintenance of shard routing information, regardless of whether the number of devices is in the tens of thousands or billions or the time span is one year or ten years. The distributed management of time-series data allows IoTDB to achieve exceptional scalability, with successful tests conducted on petabyte-scale time-series data storage.
Unified Consensus Protocol Framework: IoTDB is the first and currently the only time-series database to introduce and implement a unified framework for consensus protocols. This enables users to select different consensus algorithms based on their needs for performance, availability, consistency, and storage cost.
IoTDB offers three primary options:
IoTConsensus: High-performance protocol tailored for IoT scenarios.
RatisConsensus: Strong consistency protocol.
SimpleConsensus: Lightweight single-replica protocol. This flexibility allows users to customize their configurations based on specific business requirements.
Extensive Observability Metrics: IoTDB incorporates thousands of monitoring metrics across its distributed architecture, covering read/write processes, consensus algorithms, load balancing, and system resource usage. These metrics provide users with reliable real-time monitoring capabilities.
Apache HBase relies on the Hadoop Distributed File System (HDFS) for its storage layer, dividing its distributed architecture into compute and storage layers.
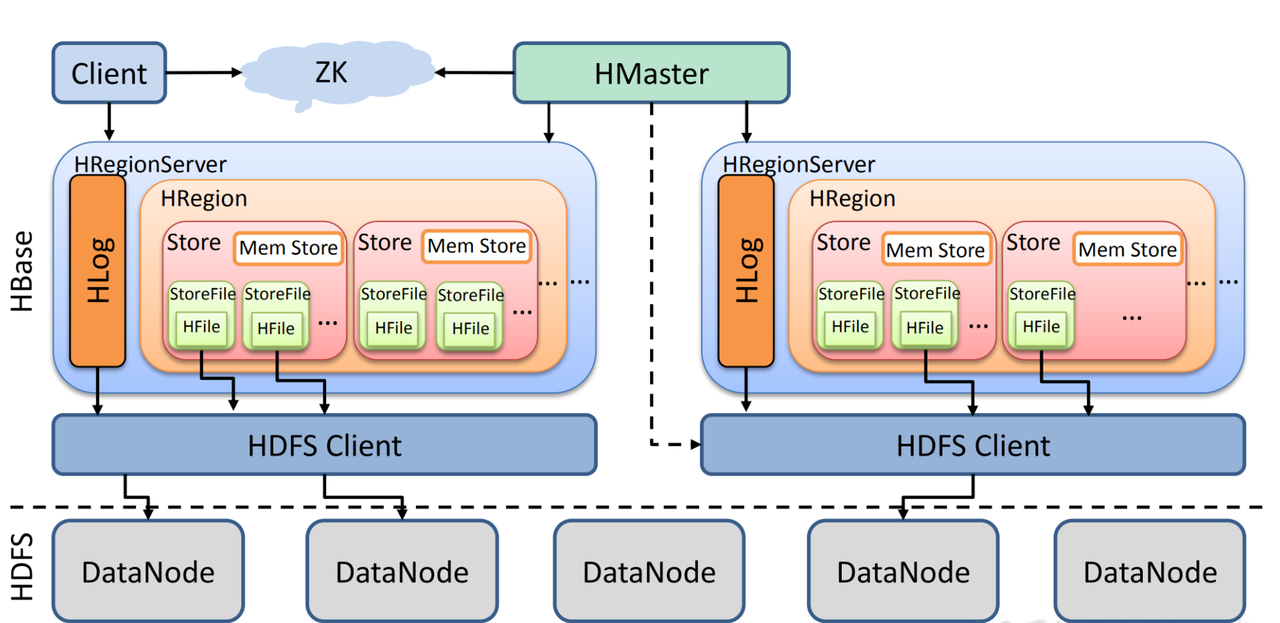
Data Replication in HDFS: HDFS ensures fault tolerance and data consistency through replication. Each file is split into multiple blocks stored across DataNodes, with each block having multiple replicas (typically three by default).
Pipeline-Based Chain Replication: To maintain consistency among replicas, HDFS employs a pipeline mechanism. Data is written sequentially to each replica, starting with the first DataNode and then being passed to subsequent DataNodes in a chain. While this method ensures consistency and availability, it introduces additional write latency and complexity during fault handling.
Key Differences
Flexibility of Consensus Algorithms:
IoTDB: Offers a unified framework supporting multiple consensus algorithms, allowing users to balance performance, availability, consistency, and cost as needed.
HDFS: Relies on a single replication-based consensus protocol, limiting its flexibility and scalability in handling diverse requirements.
Distributed Architecture Performance:
IoTDB: Optimized for time-series IoT scenarios with custom consensus protocols, partitioning, and load balancing strategies, delivering high performance and scalability.
HDFS: While chain replication ensures data consistency and availability, its sequential replication introduces write delays, especially in multi-replica scenarios. Adjustments required during DataNode failures can also impact performance, alongside challenges related to network bandwidth consumption and replica management in large-scale clusters.
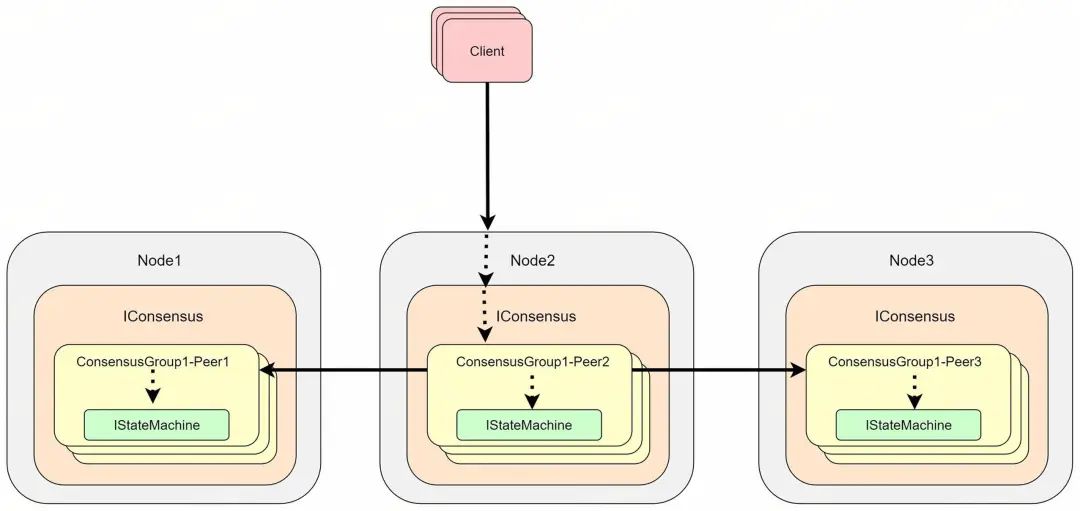
Apache IoTDB Unified Consensus Framework: Users can flexibly adopt different implementations of IConsensus.
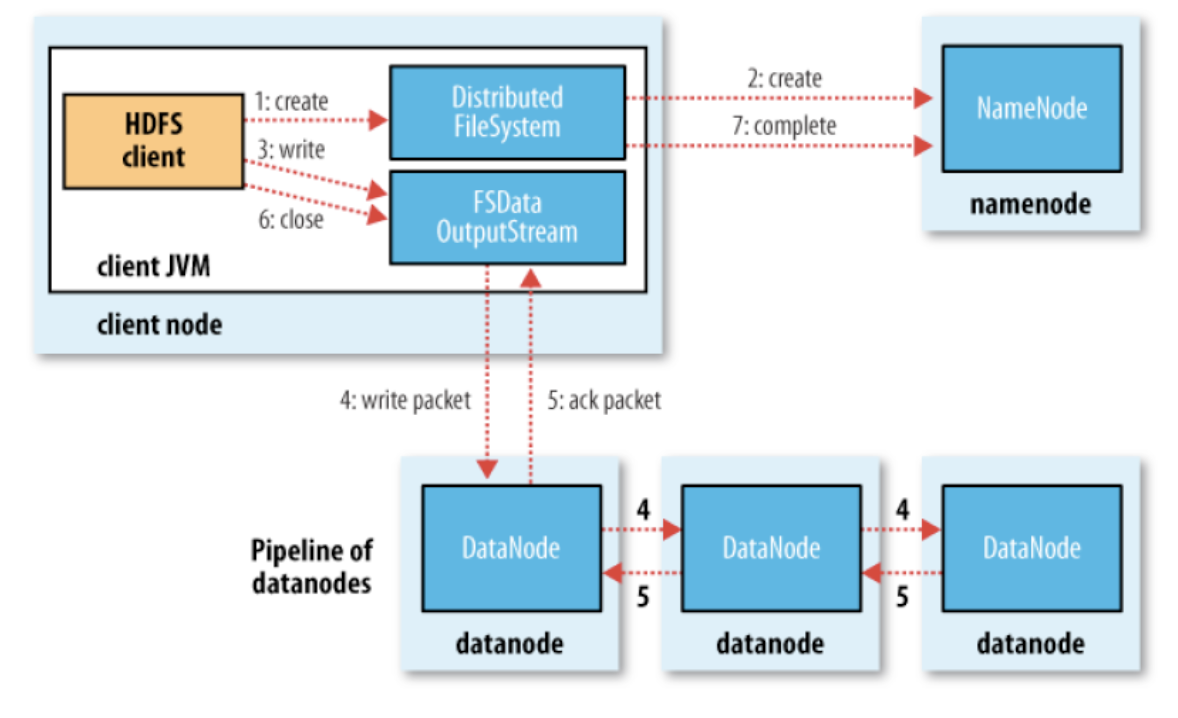
HBase Chain Replication Distributed Architecture
Comparison Dimension 2: Edge-Cloud Synchronization
Apache IoTDB features a built-in stream processing engine that supports edge-cloud synchronization with excellent performance, scalability, and reliability.
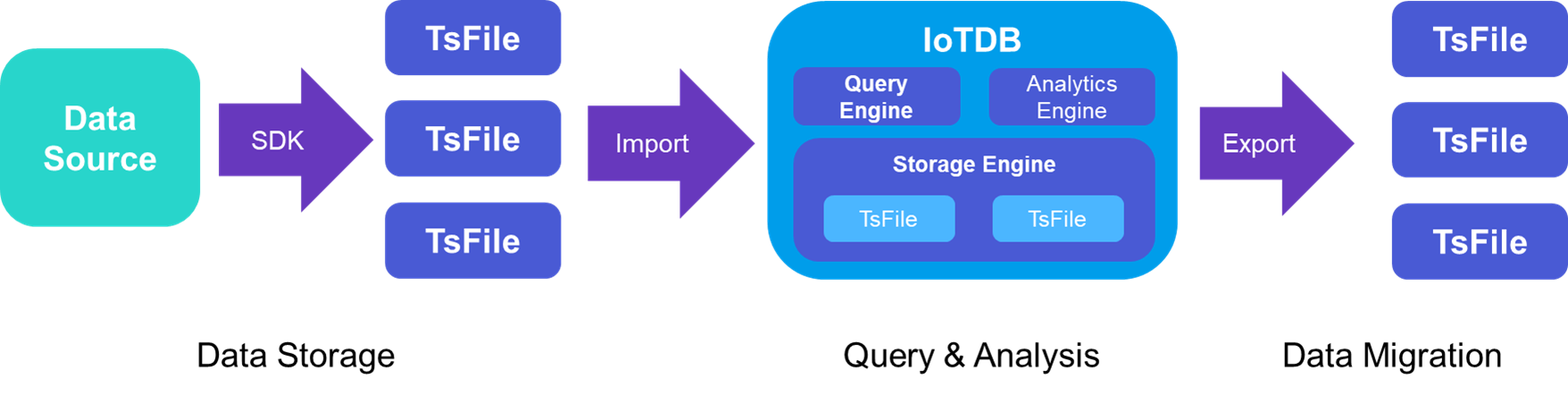
Apache IoTDB Data Synchronization
Adaptive Synchronization: IoTDB supports both streaming synchronization and file-based (TsFile) synchronization. This allows it to ensure full data synchronization while minimizing latency.
Customizable Stream Processing: Users can define custom stream processing logic to monitor and capture changes in the storage engine, process the modified data, and push transformed results externally.
High Availability in Distributed Systems: The stream processing engine natively supports features such as progress tracking, automatic retries upon errors, and breakpoint recalculations. It also adheres to at-least-once transmission semantics, ensuring end-to-end data consistency.
Near-Storage Computing: By leveraging near-storage computing, IoTDB minimizes I/O, CPU, and network costs, optimizing operations for critical scenarios. The high-compression TsFile format from the IoTLSM-Tree storage engine is used as the transmission unit, reducing network traffic and alleviating the load on cloud resources.
Apache HBase does not have built-in support for edge-cloud synchronization, as it was primarily designed for large-scale distributed storage and query use cases, typically in data centers or cloud environments. Its integration with tools like Apache Hive within the big data ecosystem is more prominent.
External Framework Dependency: To achieve edge-cloud synchronization, users must rely on external frameworks like Apache Flink or Apache Kafka to stream data from edge devices into HBase clusters. Custom synchronization logic must also be implemented to manage the transfer and analysis of edge-to-cloud data. While this approach offers flexibility, it increases development and operational complexity.
Key Differences
Native Data Synchronization:
IoTDB: Designed specifically for edge-cloud environments, its stream processing engine ensures highly efficient and real-time synchronization.
HBase: While asynchronous replication (HBase Replication) supports inter-data center synchronization, it is not optimized for edge-cloud use cases, often resulting in significant delays.
Edge Adaptability:
HBase: The architecture's reliance on HDFS and Zookeeper necessitates a stable, high-performance network environment, limiting its applicability in edge scenarios. This makes it challenging to operate effectively in environments with limited network bandwidth or constrained resources.
IoTDB: Optimized for edge environments with low bandwidth, intermittent connectivity, and minimal storage, enabling lightweight execution of data synchronization tasks.
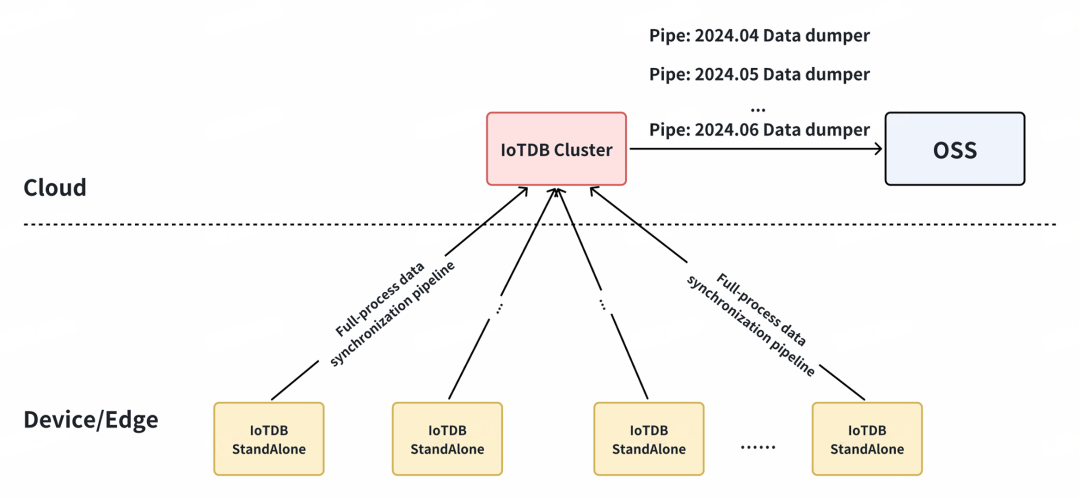
Apache IoTDB Data Synchronization in Edge-Cloud Scenarios
Comparison Dimension 3: Deployment
As a next-generation time-series data management solution, Apache IoTDB is designed with a lightweight architecture to simplify deployment, particularly by optimizing resource usage and hardware requirements.
Single-Machine Efficiency: Unlike traditional distributed databases, IoTDB can efficiently handle massive time-series data writes and queries on a single machine. Even in scenarios involving large-scale data volumes, IoTDB can achieve high-performance processing without requiring complex cluster setups.
Independent Operation: IoTDB does not rely on any external components, supporting both standalone and distributed deployments. This independence reduces setup complexity significantly.
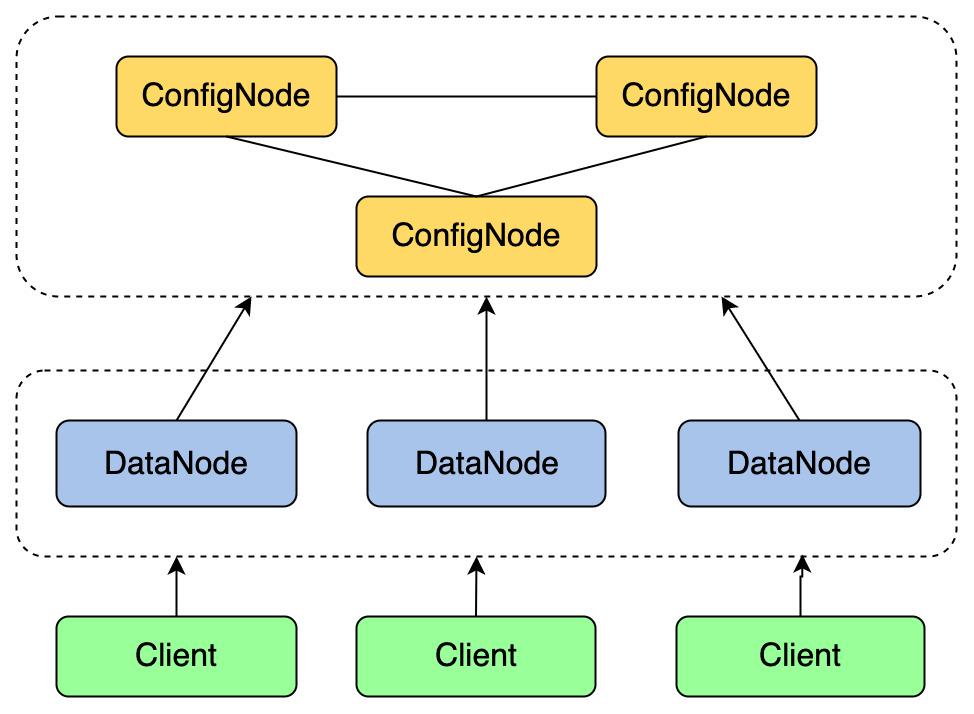
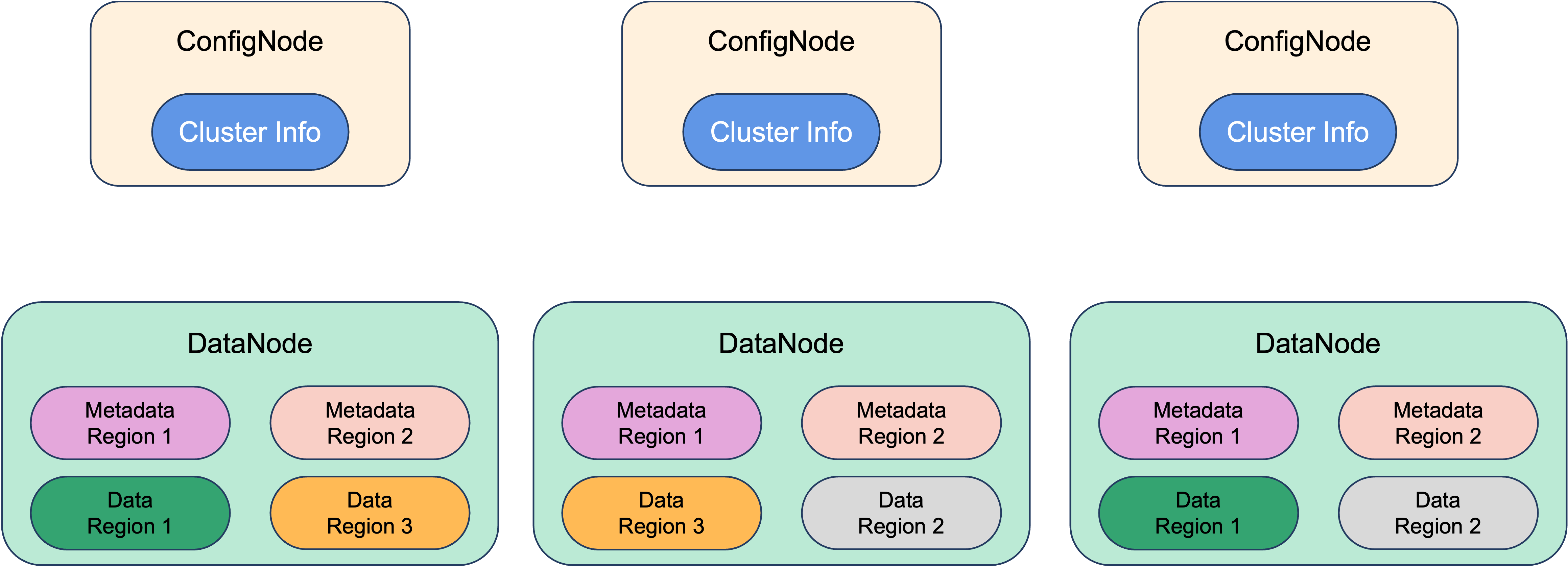
Apache IoTDB operates independently of external components, supporting both standalone and distributed deployments: the diagram above illustrates the common 3C3D architecture
Apache HBase, as a core component of the big data ecosystem, requires coordination with multiple open-source components like Hadoop, Zookeeper, and HDFS to establish a distributed cluster for business data applications.
Dependency on Multiple Components: HBase operates as a distributed database that depends on external systems for functionality:
Hadoop for the HDFS file system.
Zookeeper for cluster coordination. This architecture necessitates a distributed, multi-node setup to ensure high availability and data redundancy, resulting in increased hardware demands and operational overhead.
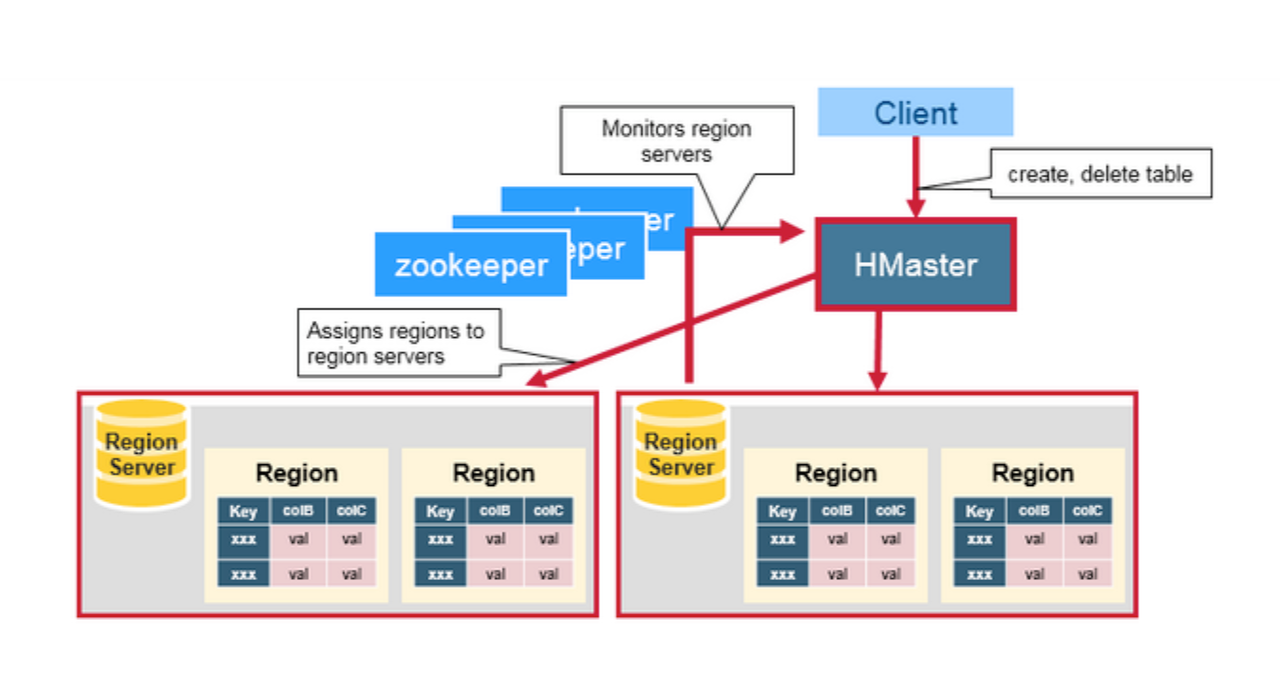
The distributed architecture of Apache HBase requires coordination with multiple upstream and downstream components, such as Zookeeper.
Key Differences
Architecture and Deployment Complexity:
IoTDB: Its lightweight architecture supports single-machine deployments, making it suitable for scenarios that do not require large-scale clusters. It is simple to deploy and has minimal dependencies.
HBase: Based on a distributed architecture, HBase relies on HDFS and Zookeeper, requiring multi-node configurations, which increases deployment complexity.
Hardware Requirements:
IoTDB: Capable of processing large-scale data on a single machine, it has low hardware requirements, making it ideal for resource-sensitive IoT scenarios.
HBase: Requires multiple nodes to ensure high availability and data redundancy, resulting in higher hardware demands and costs.
Automation and Maintenance Simplicity:
IoTDB: Offers one-click deployment tools, simplifying operations and reducing management costs by eliminating the need to handle complex component dependencies.
HBase: Managing multiple components like HDFS, Zookeeper, and RegionServer increases operational complexity and requires significant technical expertise.
Scalability:
IoTDB: Supports dynamic addition and removal of nodes, offering lightweight scalability that can easily adjust to business needs.
HBase: Scaling HBase clusters requires fine-tuning of HDFS, Zookeeper, and RegionServer, increasing the technical demands on the operations team.
Comparison Dimension 4: Analytical and Computational Capabilities
As a key-value storage system, Apache HBase has relatively basic read and write interfaces without built-in support for time-dimensioned analysis. It lacks features specifically designed for time-series data analysis. To perform such tasks, users must integrate HBase with external big data analysis tools like Apache Spark or develop significant custom business logic.
In contrast, Apache IoTDB offers extensive analytical and computational capabilities for time-series scenarios, with several standout features:
Statistical Aggregation Functions: IoTDB supports various statistical operations such as
count,max,min,avg,std,sum,first_value, andlast_value.Advanced Time-Series Query Semantics: IoTDB provides specialized query capabilities for time-series data, including:
Window-based queries divided into equal intervals.
Queries grouped by enumerated values in a specific column.
Queries based on the continuity of time-series records.
Time-Series Data Analysis: IoTDB supports advanced analysis tasks, such as:
Data quality checks.
Data profiling.
Anomaly detection.
Frequency domain analysis.
Data matching and repair.
AINode Integration: IoTDB includes a native machine learning framework, AINode, which provides pre-built algorithms for tasks like time-series forecasting and anomaly detection. Users can also deploy their custom models to run inferences directly on the data. This out-of-the-box solution combines storage and analysis, allowing seamless operations such as sequence forecasting immediately after installation.
Comparison Dimension 5: Performance
Performance is a critical factor when choosing a time-series database. Here, we compare Apache IoTDB and Apache HBase based on the TPCx-IoT benchmark, the first IoT benchmark designed to measure the performance of IoT gateway systems.
About TPCx-IoT
TPCx-IoT enables direct comparison of different software and hardware solutions. Using a typical power utility scenario with thousands of substations, it evaluates:
The performance, cost-efficiency, and availability of commercial systems processing data from a large number of devices.
Real-time analytic queries running concurrently with large-scale data ingestion.
System architectures and implementation approaches in a technically rigorous, directly comparable manner.
Key Metrics Defined by TPCx-IoT:
Performance (IoTps): IoTps = SF/T, where SF is the scale factor (data ingested) and T is the elapsed ingestion time in seconds.
Cost Efficiency ($/kIoTps): $/kIoTps =1000∗P / IoTps, where P is the total 3-year cost of the system under test (SUT).
System Availability Date: The date when the system becomes available, as defined by TPC pricing specifications.
Performance Results
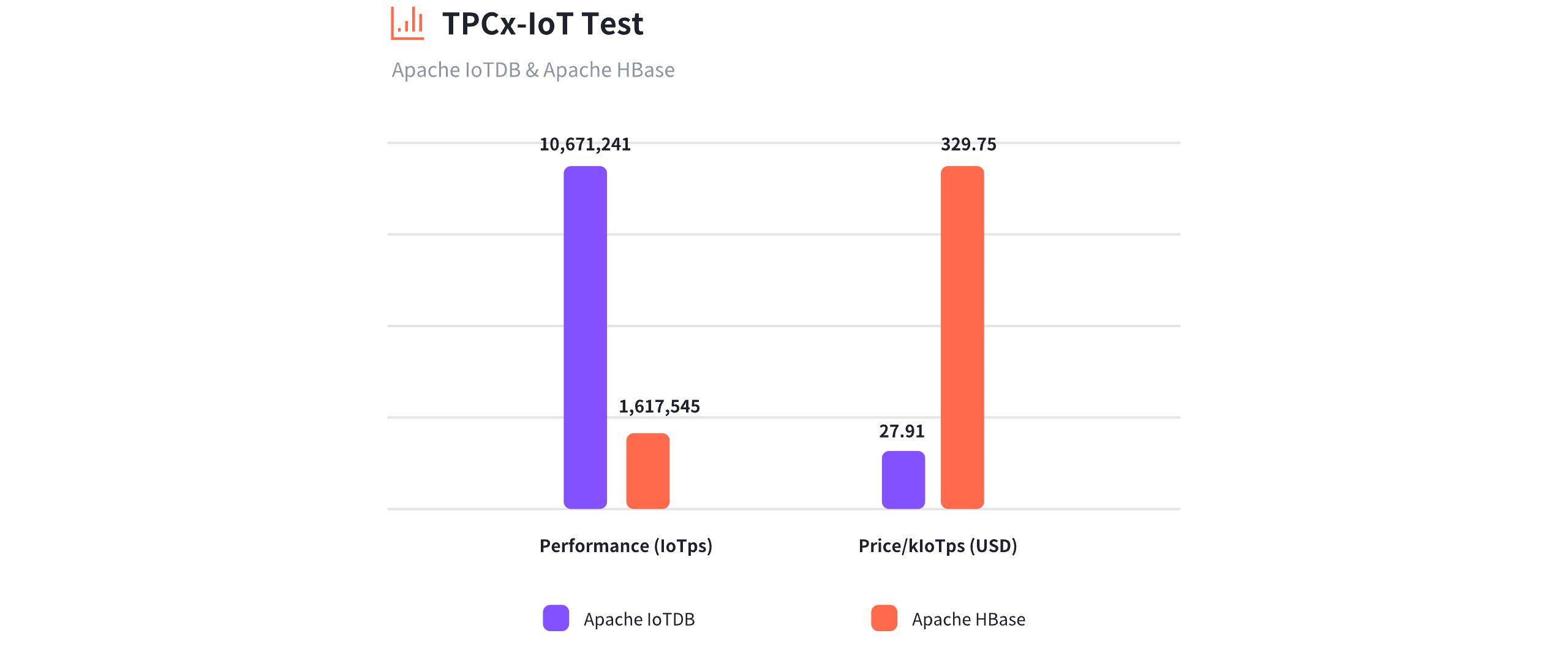
Throughput (IoTps):
Apache IoTDB (TimechoDB): 10,671,241 IoTps.
Apache HBase (Cloudera HBase 2.2.3 on CDP 7.1.4): 1,617,545 IoTps. IoTDB achieves approximately 6.6 times the performance of HBase.
Cost Efficiency ($/kIoTps):
Apache IoTDB (TimechoDB): $27.91 USD/kIoTps.
Apache HBase (Cloudera HBase 2.2.3 on CDP 7.1.4): $329.75 USD/kIoTps. IoTDB is about 11.81 times more cost-efficient than HBase.
Conclusion
When selecting a time-series database for IoT and big data applications, understanding the differences in architecture, functionality, and performance is critical. This article provides a detailed comparison of Apache IoTDB and Apache HBase, focusing on their performance in time-series scenarios. Key aspects analyzed include distributed architecture, edge-cloud synchronization, deployment ease, analytical and computational capabilities, and performance.
Through this analysis, we aim to offer valuable insights for developers and decision-makers, enabling them to make informed choices. In the dynamic and evolving landscapes of IoT and big data, selecting the right time-series database is essential for achieving optimal outcomes.


