

The Data Infrastructure Problem Layer Often Overlooked
When intelligent transportation is discussed, the focus typically falls on autonomous vehicles, smart signaling, and real-time routing. Rarely does attention turn to the data infrastructure layer that quietly sustains these systems—continuously ingesting millions of sensor readings per second, compacting years of telemetry into manageable storage, and serving operational queries in milliseconds while transportation systems operate at full speed.
Yet in production environments, this invisible layer often determines whether an intelligent transportation platform scales successfully.
Consider the data reality:
A modern metro system operating 300 trains can generate ~414 billion data points per day
A connected vehicle platform managing 1.6 million vehicles can produce ~20 TB of new telemetry every 24 hours
These are not traditional data warehousing workloads. They are high-cardinality, high-velocity time-series problems that require purpose-built infrastructure.
Apache IoTDB is designed for exactly this class of workload. This article examines what it is, why it fits transportation systems particularly well, and where it delivers the most operational value.
What Is Apache IoTDB?
Apache IoTDB (Internet of Things Database) is an open-source, high-performance and AI-ready time-series database under the Apache Software Foundation. It was originally engineered for industrial IoT environments characterized by extreme write throughput and long-term telemetry retention—conditions that closely mirror modern transportation systems.
At a systems level, IoTDB differentiates itself through three architectural principles.
Purpose-Built for Time-Series at Scale
IoTDB is not a general database retrofitted with time-series features. Its:
Data model
Indexing strategy
Query engine
Storage format
are all optimized for canonical time-series access patterns, including:
High-frequency sequential writes
Time-range scans
Long-window aggregations
...
This specialization eliminates much of the structural overhead seen in row-oriented or general distributed databases under fleet-scale workloads.
Native Columnar Storage: Apache TsFile
IoTDB uses Apache TsFile as its on-disk format, organizing data by measurement and time to maximize compression efficiency.
For transportation telemetry—where sensor values typically exhibit strong temporal locality—TsFile commonly achieves 10×–30× lossless compression in production environments. In real deployments, three-year storage footprints have been reduced from 200 TB to ~16 TB.
Edge-to-Cloud Native Architecture
Unlike databases designed primarily for centralized deployment, IoTDB was built with edge scenarios as a first-class requirement.
Edge nodes (vehicles, substations, vessels) accumulate data locally and synchronize compressed TsFile segments upstream. Compared with record-level replication, this approach can reduce bandwidth consumption by up to 90%—a material advantage in environments with intermittent or constrained connectivity.
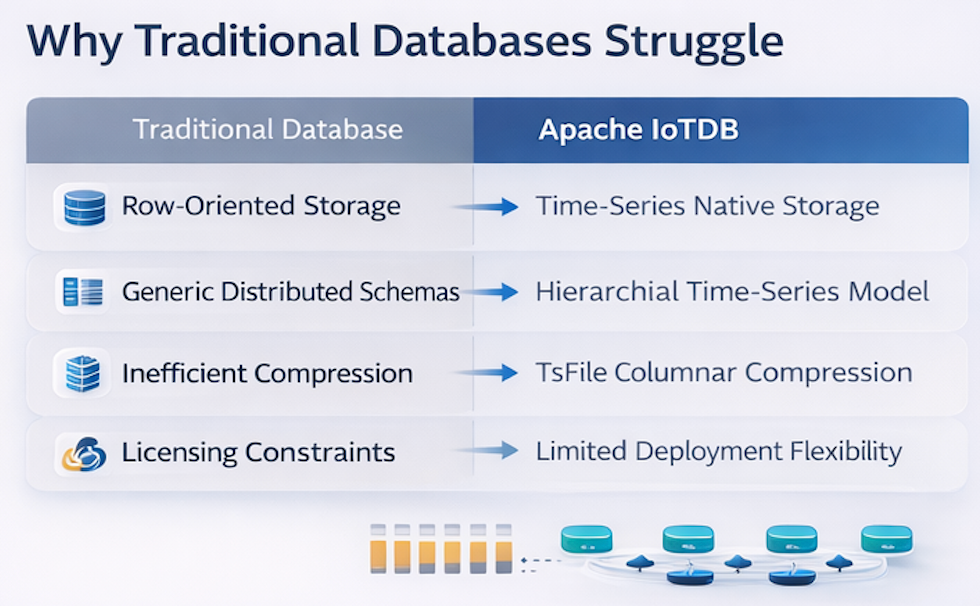
Why Traditional Databases Struggle at Transportation Scale
Transportation telemetry exposes several structural weaknesses in non-specialized databases.
Row-oriented storage Time-range queries against row stores incur significant I/O amplification because sensor histories are interleaved across rows. At fleet scale, this frequently translates into minute-level latency.
Generic distributed schemas Many systems require substantial application-side modeling to represent hierarchical assets (fleet → vehicle → subsystem → sensor). Metadata management often becomes a bottleneck at million-series scale.
Inefficient time-series compression Storage engines without time-series-aware encoding typically scale storage cost roughly linearly with data volume—economically unsustainable for multi-year telemetry retention.
Licensing and deployment flexibility Some database licensing models impose constraints on self-hosted deployment, long-term cost predictability, or deep system customization. For transportation platforms that operate large, long-lived infrastructure systems, these limitations can introduce operational and architectural friction at scale.
These limitations consistently surface in production migrations toward purpose-built time-series infrastructure.
Core Technical Capabilities
High-Throughput Ingestion
IoTDB's write path is optimized for concurrent, high-frequency sensor ingestion. In production conditions, a single node can sustain tens of millions of data points per second, enabled by:
Memory-buffered ingestion
Batch-optimized flushing
Time-partitioned storage
For transportation platforms, this means hundreds of trains or hundreds of thousands of vehicles can be absorbed without write-side bottlenecks.
Millisecond-Level Query Performance
Transportation workloads typically fall into three query classes:
Latest-value queries Example: current speed or battery level of a vehicle. → Served from in-memory structures with sub-millisecond latency.
Time-range queries Example: brake pressure between 08:00–09:30. → Executed efficiently via time-partitioned TsFile scans.
Aggregation queries Example: fleet fuel consumption over 30 days. → Accelerated by columnar scan-and-aggregate execution.
Across multiple production deployments, workloads migrated from HBase or Cassandra have observed latency reductions from minutes to milliseconds.
Compression and Storage Efficiency
Transportation telemetry is highly compressible due to:
Temporal correlation within sensor streams
Bounded numeric ranges
Repetitive measurement patterns
TsFile leverages differential encoding, run-length encoding, and dictionary compression at the column level.
In practice, this yields 10×–30× smaller storage footprints, directly lowering infrastructure cost at fleet scale.
Edge-to-Cloud Synchronization
IoTDB enables configurable synchronization strategies — from real-time record-level streaming to compressed TsFile-based batch replication — allowing transportation operators to balance latency, bandwidth efficiency, and network resilience.
This design delivers two operational advantages:
Bandwidth efficiency: Compressed TsFile transfer can reduce network usage by up to 90%.
Offline tolerance: If connectivity drops (tunnels, offshore zones), edge nodes continue buffering locally and resume sync automatically when the network returns—without application-side reconciliation logic.
High Availability Architecture
Distributed IoTDB clusters support:
Automatic failover
Load balancing
Rapid node recovery
For transportation systems where telemetry gaps can impact safety and compliance, these are baseline requirements rather than optional features.
Open Governance and Deployment Flexibility
IoTDB is governed under the Apache License 2.0, providing full source transparency and flexible self-hosted deployment. For large-scale transportation platforms that operate long-lived infrastructure systems, this model supports greater operational control and long-term maintainability.
Where IoTDB Fits in the Transportation Stack
IoTDB is data infrastructure, not an end-user application platform.
What IoTDB Handles
Telemetry ingestion from vehicles and infrastructure
Long-term compressed storage
High-performance time-series querying
What Typically Sits Above
Predictive maintenance systems
Anomaly detection pipelines
Visualization platforms (e.g., Grafana)
Big data processing (Spark, Flink, Hadoop)
What Sits Below
Onboard data collectors
IoT gateways
Network transport layers (5G, DSRC, satellite)
This positioning is important for correctly scoping IoTDB within complex transportation architectures.
Two Primary Transportation Use Domains
Urban Rail Operations and Maintenance
This domain emphasizes:
Equipment health monitoring
Predictive maintenance
Signal integration
Real-time operations
Production deployments include:
CRRC Sifang intelligent rail O&M platform
CityX Urban Construction Intelligent Control metro automation system
Deutsche Bahn fuel cell monitoring project
These environments commonly involve millions of measurement points and multi-year retention requirements.
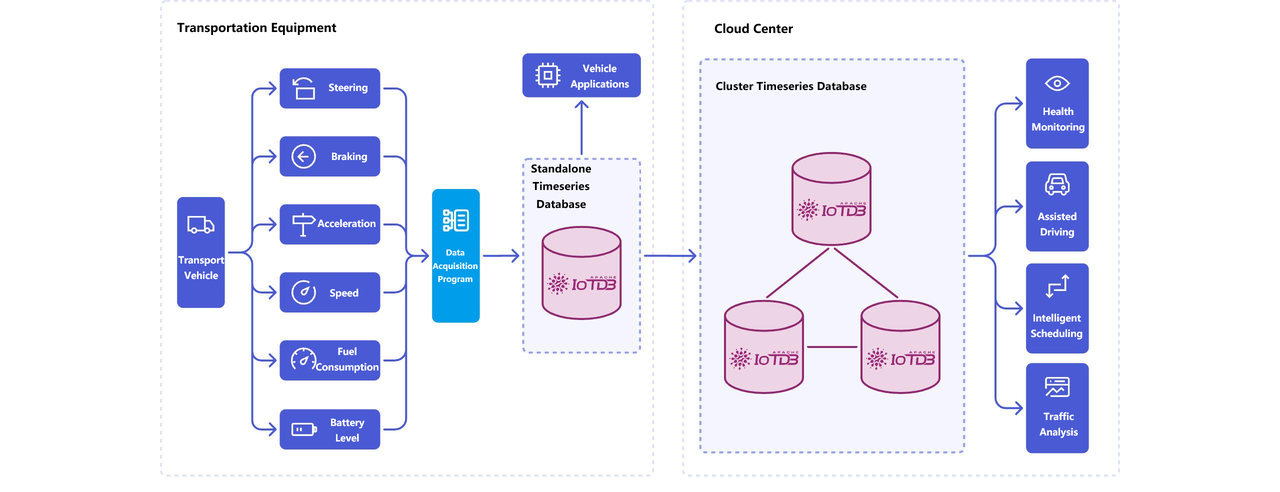
Connected Vehicle Management
This domain features:
Geographically distributed fleets
Heterogeneous telemetry
Bursty peak loads
Mixed real-time and analytical queries
Representative deployments include:
Changan Automobile connected vehicle platform
AutoAI Toyota driving behavior system
Measurement cardinality typically reaches tens to hundreds of millions of time series.
Summary
Intelligent transportation systems run on time-series data infrastructure that is often overlooked but operationally decisive.
Apache IoTDB addresses the sector's most persistent data challenges through:
High-ratio TsFile compression
Edge-native synchronization
Millisecond query latency
Open and sovereign deployment model
The next two articles in this series examine how these capabilities translate into real-world outcomes in urban rail and connected vehicle platforms. Stay tuned!
Build smarter systems on a foundation that scales. Start exploring IoTDB today.


