

The value of stored data is realized through analysis, and when data is queried and analyzed, its true value is unlocked. In this article, we talk about SQL queries and segmentation techniques in Apache IoTDB.
In relational databases, the GROUP BY clause is used to group result sets by one or more columns. It is often used with aggregate functions such as COUNT(), SUM(), AVG(), MIN(), and MAX() to perform statistical calculations on each group. However, since relational databases do not consider the sequence in time of numerical values, GROUP BY does not account for the order of grouping keys.
As an example, we use temperature data recorded for equipment on a production line at different times and under various working conditions to illustrate the different uses of GROUP BY clause. As shown below, grouping based on column values typically uses data equivalence as the grouping condition, with a fixed segmentation method.
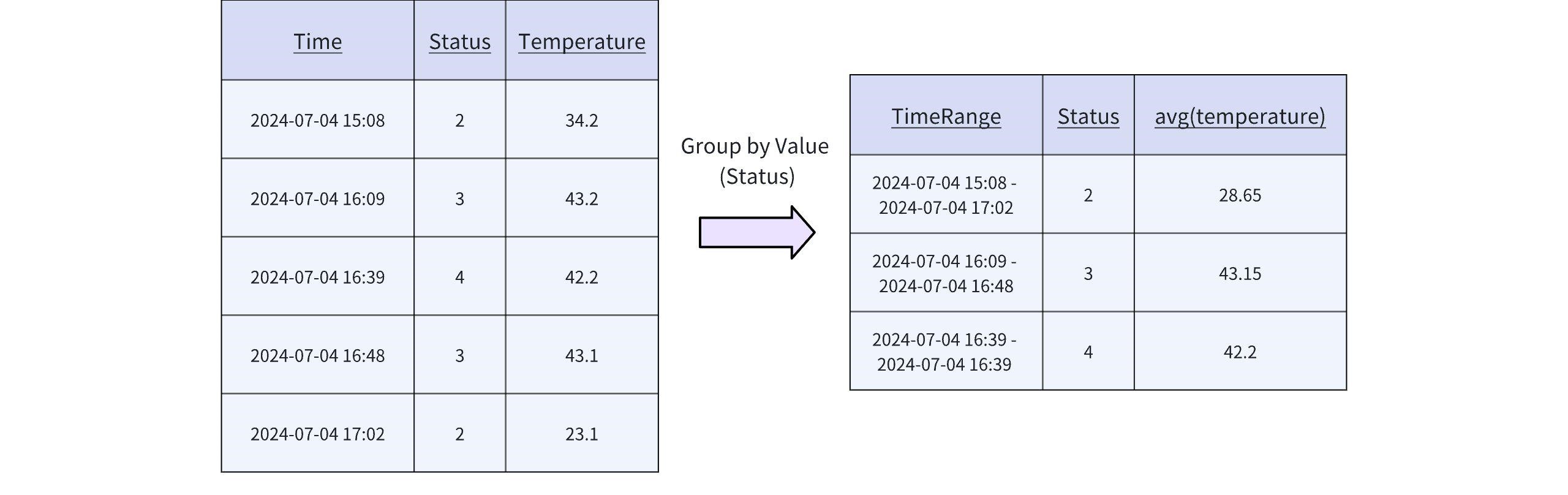
In time-series scenarios, we usually care more about the relationships between data points over time. Grouping by time columns requires identifying different time windows or other segmentation methods that align with time-series semantics.

Therefore, IoTDB provides new segmentation scenarios based on time columns, allowing users to quickly and conveniently segment time-series data using simple built-in SQL statements. This feature enhances the extraction of relevant characteristics from time-series data, helping users uncover data value more efficiently in time-series contexts.
Details of Time-Series Segmentation Methods in IoTDB
Method 1: Segmentation by Time Interval
IoTDB supports basic time sliding window segmentation, which is a fundamental method of time segmentation. You can specify the aggregation time interval and the sliding step size to define the time window. This method mainly includes three parameters:
[startTime, endTime): the time range for the query
interval: the size of a single segmentation window
sliding step: the sliding step size of the window
GROUP BY ([startTime, endTime), size, step)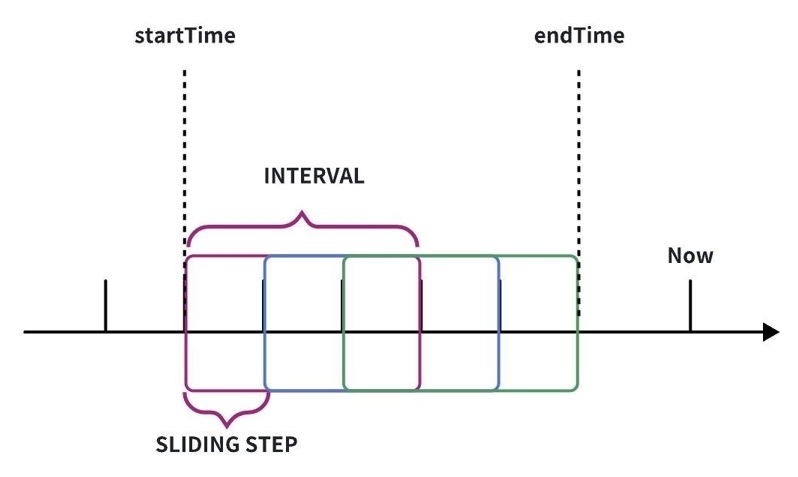
Illustration of Segmentation by Time Interval
Method 2: Segmentation by Data Value Difference
Traditional segmentation methods can segment data with the same value. In the context of time-series data, since the data is in sequence, we can use value change patterns as a basis for segmentation.
In the difference-based segmentation of IoTDB, we take the first data point as the reference for a time segment. Each segment calculates the difference with the reference value according to a given expression. If the difference is less than a specified threshold, the data point is included in the current time segment; otherwise, it starts a new segment.
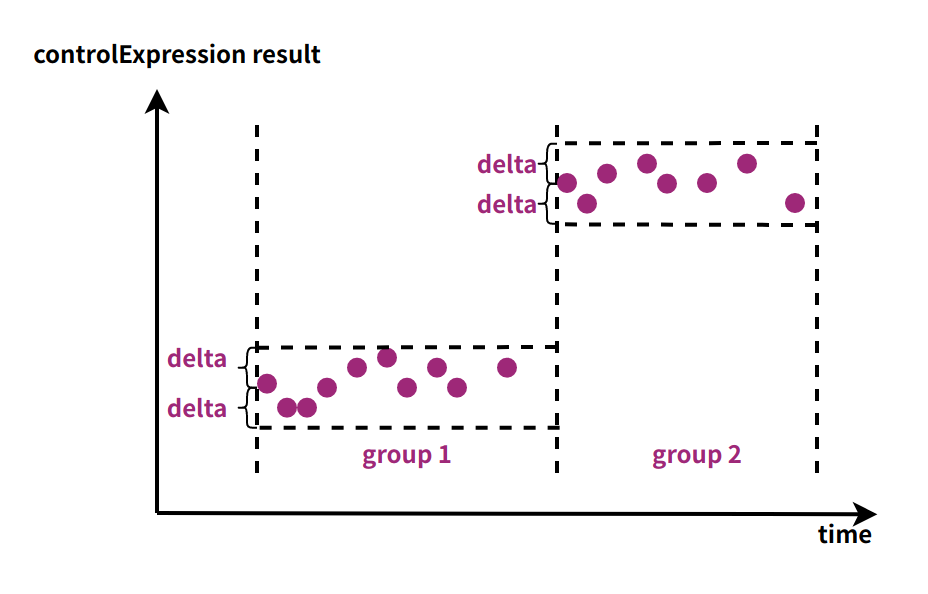
Illustration of Segmentation by Data Value Difference
The SQL for difference-based segmentation in IoTDB, along with the meanings of its various parameters, is as follows:
GROUP BY VARIATION(controlExpression[,delta][,ignoreNull=true/false])controlExpression: the value referenced for grouping, which can be a column in the data or an expression involving multiple columns
delta: the threshold value used for grouping, with a default value of 0
ignoreNull: specifies how to handle data when the result of controlExpression is null. If ignoreNull is true, such points are skipped; otherwise, a new segment is created.
Method 3: Segmentation by Session Interval
In practical scenarios, even ordered time columns may not be continuous. The time intervals between these time points can serve as the basis for segmentation. Session segmentation can divide data into different time segments when the time intervals exceed a certain threshold.
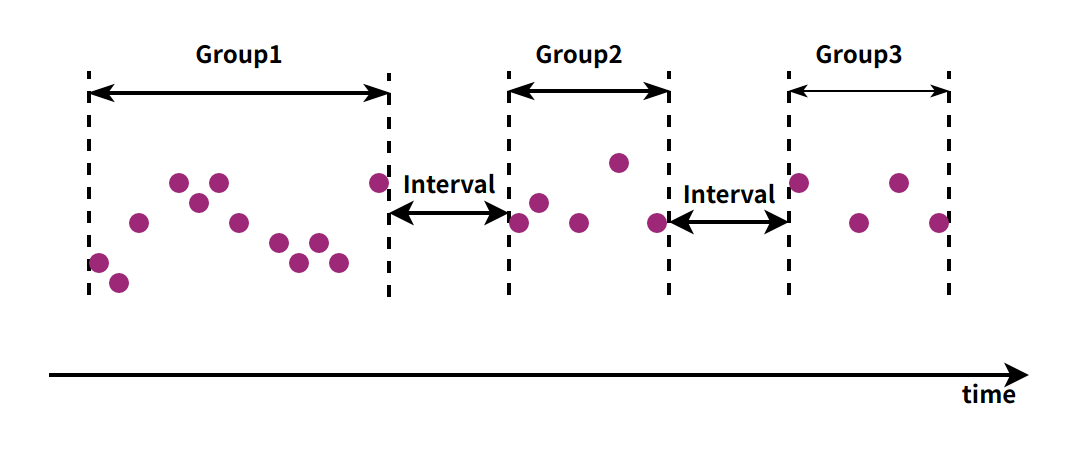
Illustration of Segmentation by Session Interval
GROUP BY SESSION(timeInterval)Method 4: Segmentation by Data Points
In certain scenarios, we may segment time-series data based on a specified number of consecutive data points, grouping a fixed number of continuous data points together.
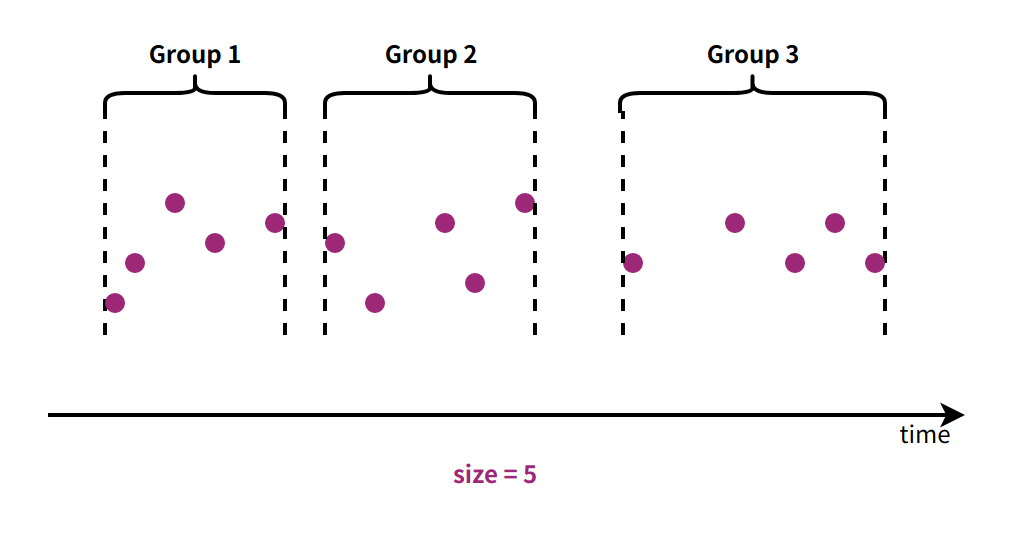
Illustration of Segmentation by Data Points
GROUP BY COUNT(controlExpression,size[,ignoreNull=true/false])Method 5: Condition-based Segmentation by Data Points
For sequential data, we can specify a condition to filter the data rows. Consecutive data points that meet the condition are grouped into segments. For instance, we can segment every three data points where a certain condition is true.
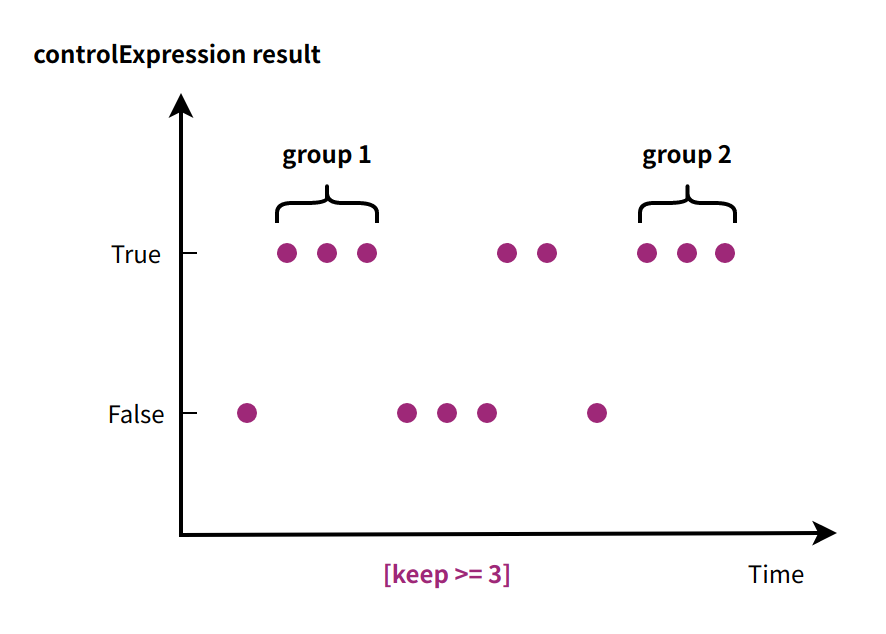
Illustration of Condition-based Segmentation by Data Points
GROUP BY CONDITION(predictExpression[keep >/>=/=/<=/<]threshold[,ignoreNull=true/false])predictExpression: an expression that returns a boolean value, used to filter data rows
keep: specifies the number of rows that satisfy the
predictExpressioncondition to be included in the time segmentignoreNull: determines how to handle rows when
predictExpressionevaluates to be null. IfignoreNullis true, such rows are skipped; otherwise, a new segment is created.
Summary
This article elaborates the five specialized segmentation methods available in IoTDB for time-series data. Unlike traditional relational algebra used in relational databases, which operates on unordered sets, these segmentation methods leverage the inherent sequential nature of time-series data. The provided syntax allows you to efficiently address various queries related to time-series data. In addition to these segmentation methods, IoTDB offers a general segmentation framework. We encourage interested users and contributors to join us and contribute to the development of diverse segmentation implementations.


