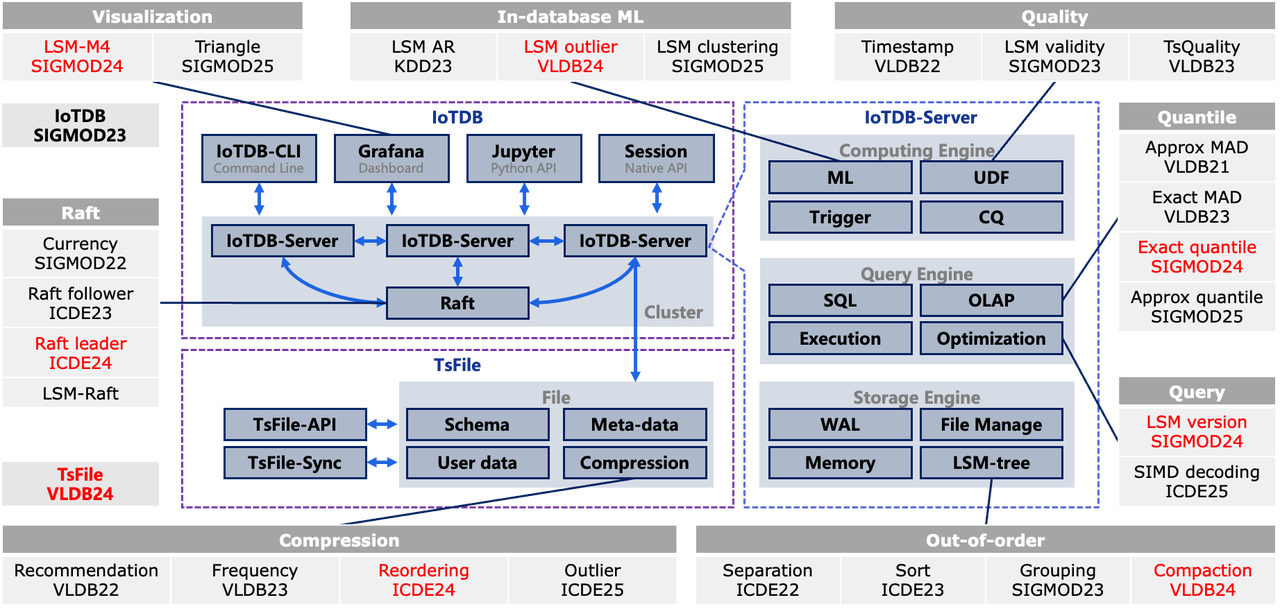
In 2024, remarkable academic milestones were realized in the domain of the time-series database IoTDB, with scholars and developers dedicated to IoTDB publishing eight papers in CCF-A international database conferences. These contributions span areas such as storage, engines, query optimization, and data analysis, showcasing technical advancements that bolster IoT applications.
In the area of storage, efficient data storage and querying were made possible with Apache TsFile, a file format specifically designed for IoT time-series data through optimized data organization and indexing structures. Additionally, the REGER method enhances regression encoding by reordering time-series data points, aiming to reduce storage costs.
In the engine domain, critical challenges in high-throughput IoT scenarios were effectively resolved using IoTDB. The Multi-Column Compaction (MCC) strategy effectively mitigates space amplification in LSM-tree architectures. Meanwhile, systematic tuning of the Raft consensus protocol improves system performance for IoT workloads.
In the query optimization domain, a versioned time-series data model and related optimization techniques were presented in IoTDB. These advancements improve query efficiency for versioned data. Furthermore, a randomized summary method determines exact quantiles, providing an efficient solution for data analysis.
In data analysis, methods such as LSMOD for efficient outlier detection and M4-LSM for improving time-series data visualization were developed in IoTDB. These innovations enhance anomaly detection accuracy and visualization performance, supporting a broad range of IoT applications.
These innovative technologies provide robust support for IoT applications and hold promise for even greater impact in the future. They address current challenges in data management and pave the way for advancements in time-series databases, ensuring IoTDB remains at the forefront of the field.
Storage
🎯VLDB 2024: Apache TsFile: An IoT-native Time Series File Format
✍️First Author: Zhao Xin
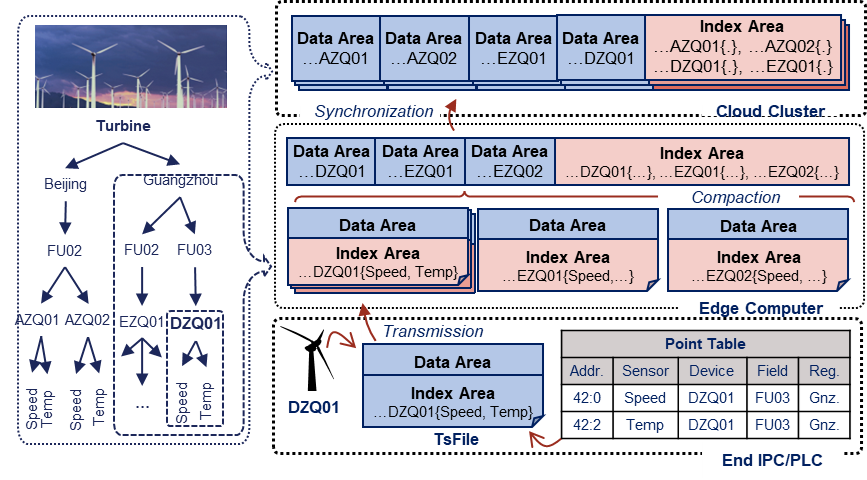
Apache TsFile is a file format specifically designed for IoT time-series data. Time-series data plays a pivotal role in IoT applications, capturing the states or measurements of devices at specific time intervals. However, traditional file formats often struggle with performance bottlenecks and storage inefficiencies when handling time-series data.
TsFile organizes data based on devices, with each device’s data segmented into chunks representing specific time intervals. This structure improves data compression efficiency and enhances data locality at both the device and file system levels. Additionally, TsFile incorporates a B-tree-based indexing mechanism, enabling rapid queries based on device ID, time range, or value range.
Performance comparisons reveal that TsFile surpasses traditional formats like Parquet and Arrow in storage efficiency, write speed, and query latency, particularly for large-scale IoT datasets. Overall, Apache TsFile provides a robust solution for efficient data organization, storage, and retrieval in IoT scenarios.
ICDE 2024: REGER: Reordering Time Series Data for Regression Encoding
First Author: Xiao Jinzhao
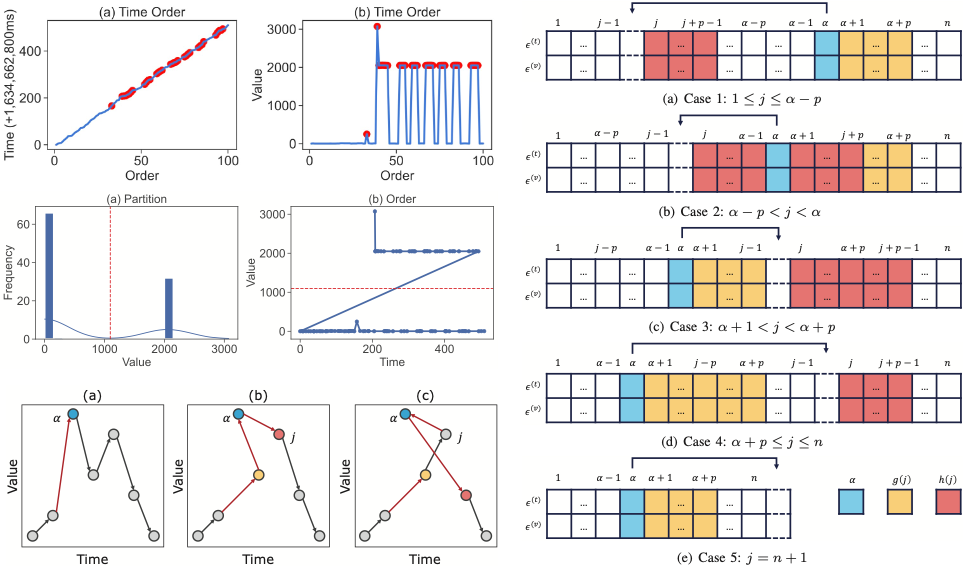
The REGER method optimizes time-series data storage through regression encoding with data reordering. Unlike conventional storage, where data points are arranged sequentially by timestamp, REGER reorders data points to reduce fluctuations and improve compression efficiency. This minimizes the residual space between predicted and actual values in regression models, leading to higher compression ratios.
Through iterative adjustments, REGER identifies an optimal ordering of data points to achieve better compression. Experiments demonstrate its effectiveness in reducing storage costs for large-scale time-series datasets, making it a valuable contribution to IoT data management.
DOI: 10.1109/ICDE60146.2024.00100
Engine
VLDB 2024: On Reducing Space Amplification with Multi-Column Compaction in Apache IoTDB
First Author: Fang Chenguang
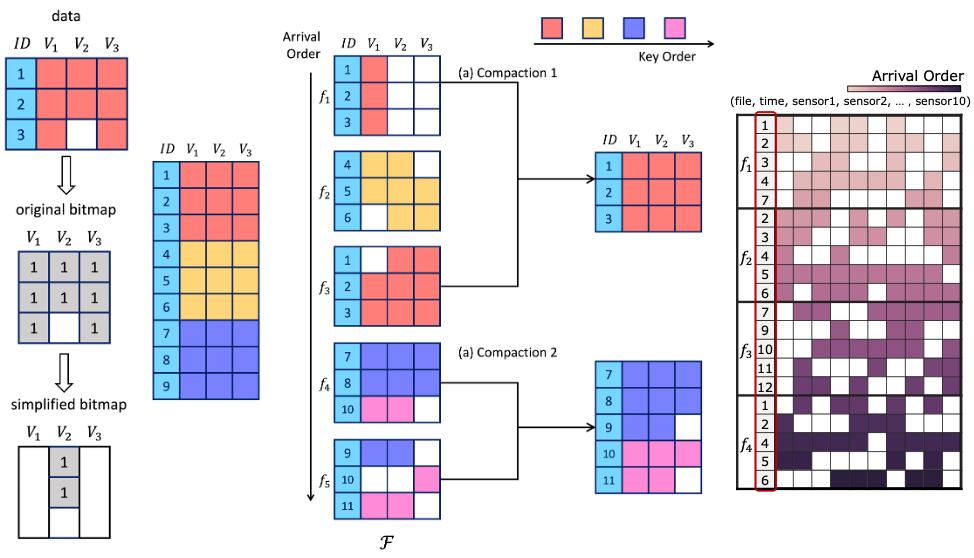
IoTDB leverages the LSM-tree architecture to handle high-throughput IoT scenarios. However, frequent data insertions and updates often exacerbate space amplification. To address this, the Multi-Column Compaction (MCC) strategy optimizes file selection during compaction by merging files with redundant keys and outdated values, significantly reducing storage costs.
MCC’s effectiveness is validated through experiments, showcasing reduced space amplification and improved query performance. This approach not only enhances IoTDB’s storage efficiency but also establishes its applicability to other LSM-tree-based databases.
ICDE 2024: On Tuning Raft for IoT Workload in Apache IoTDB First Author: Jiang Tian
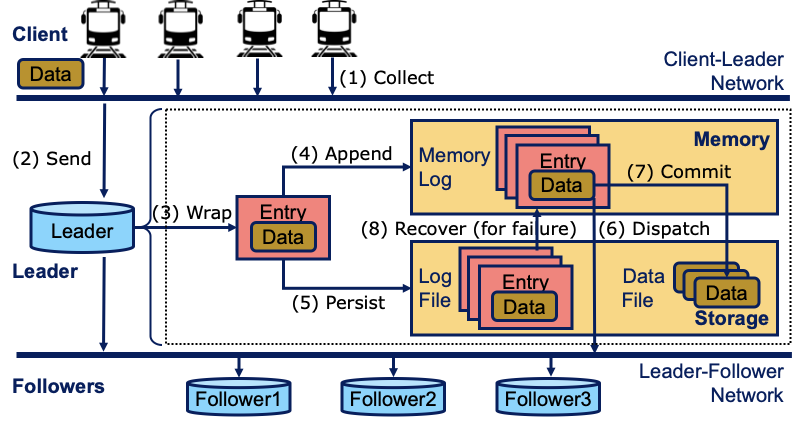
The Raft consensus algorithm is essential for ensuring reliability and fault tolerance in IoT databases. However, IoT workloads, characterized by high concurrency and fluctuating traffic, pose unique challenges, including synchronization overhead and inefficient resource use.
To address these issues, Raft was optimized for IoTDB through queue-based scheduling, pre-serialization, and specialized memory management, improving parallelism, write speeds, and memory efficiency. Additional enhancements, such as adaptive scheduler configuration and sample-based compression selection, further align Raft with IoT workload demands.
These optimizations significantly enhance throughput and responsiveness, making Raft better suited for high-performance IoT databases.
DOI: 10.1109/ICDE60146.2024.00399
Query Optimization
SIGMOD 2024: Optimizing Time Series Queries with Versions
First Author: Kang Rui
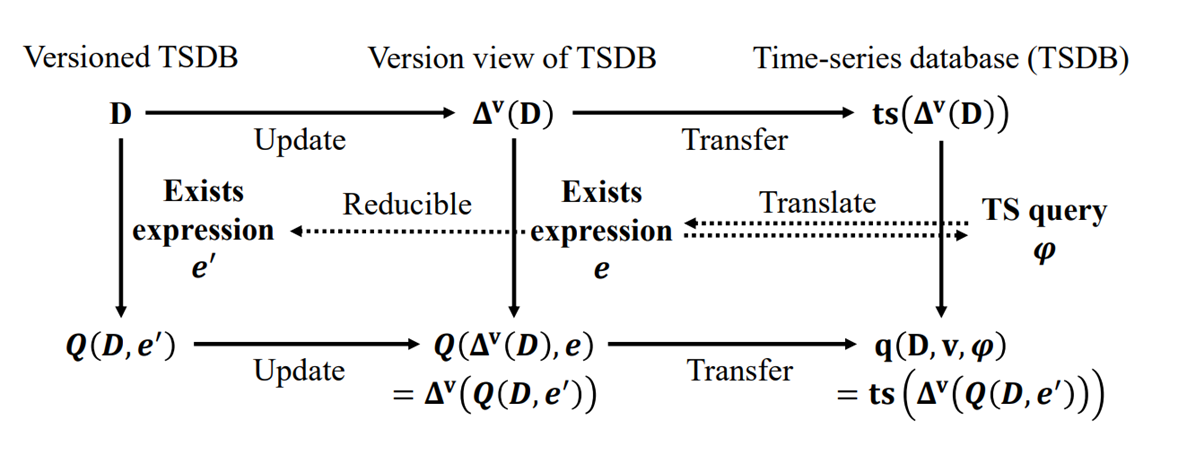
Time-series data is critical in industrial IoT, generated at high frequencies that challenge database durability and performance. While LSM-trees are widely used for IoT data storage, real-world datasets often involve multiple versions due to delays, duplicates, and errors, adding complexity.
To tackle this, a versioned time-series data model was introduced, enabling efficient merging of versioned data using branching mechanisms. Advanced query optimization techniques, such as fast point filtering and range filtering, further enhance accuracy and efficiency.
These innovations significantly improve the management and querying of multi-version data, providing robust support for large-scale IoT applications.
DOI: 10.1145/3654962
SIGMOD 2024: Determining Exact Quantiles with Randomized Summaries
First Author: Chen Ziling
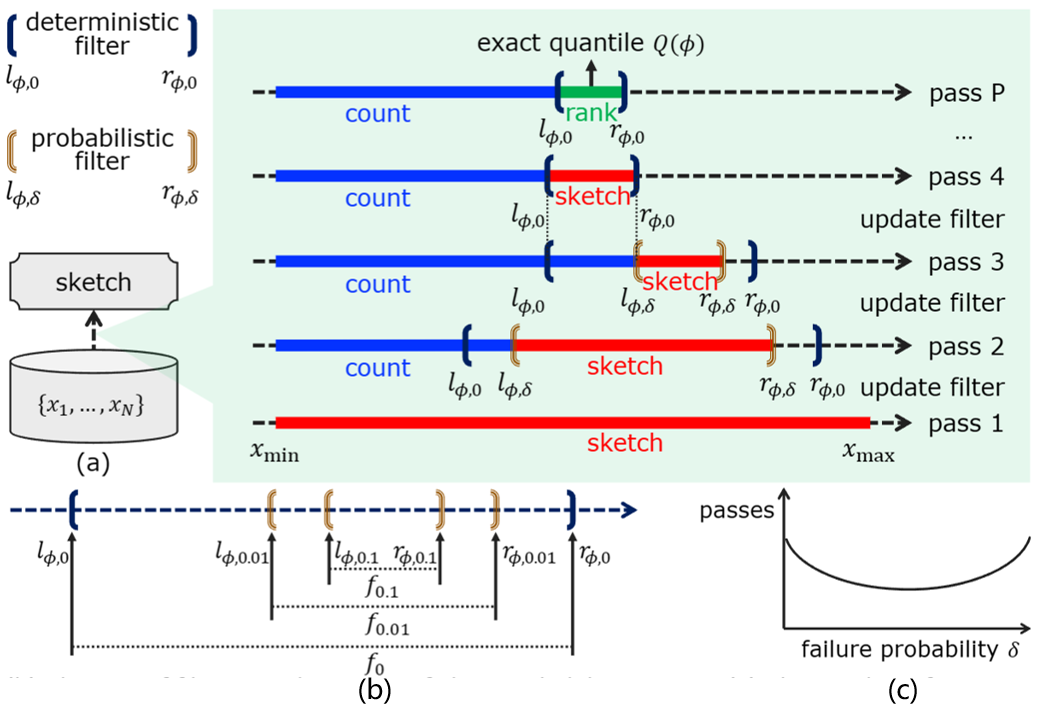
Quantiles are essential for understanding data distributions, but calculating them for large datasets is resource-intensive. A novel randomized summary method efficiently determines exact quantiles without full data sorting or loading.
By using probabilistic filters and iterative data passes, this approach achieves high accuracy with fewer iterations than traditional methods. It is scalable, memory-efficient, and supports parallel processing and multi-quantile computation, making it ideal for data analysis, mining, and machine learning.
DOI: 10.1145/3639280
Data Analysis
VLDB 2024: Distance-based Outlier Query Optimization in Apache IoTDB First Author: Su Yunxiang
Anomaly detection is vital for identifying rare patterns in time-series data, but delayed data common in IoT scenarios adds complexity.
The LSMOD method optimizes anomaly detection in Apache IoTDB by leveraging bucket statistics and boundary pruning, addressing the challenges of overlapping time ranges in delayed data. It enhances accuracy and efficiency without relying on simple aggregation of partial results.
LSMOD is a robust solution for real-time anomaly detection in IoT, climate monitoring, and other domains requiring efficient time-series analysis.
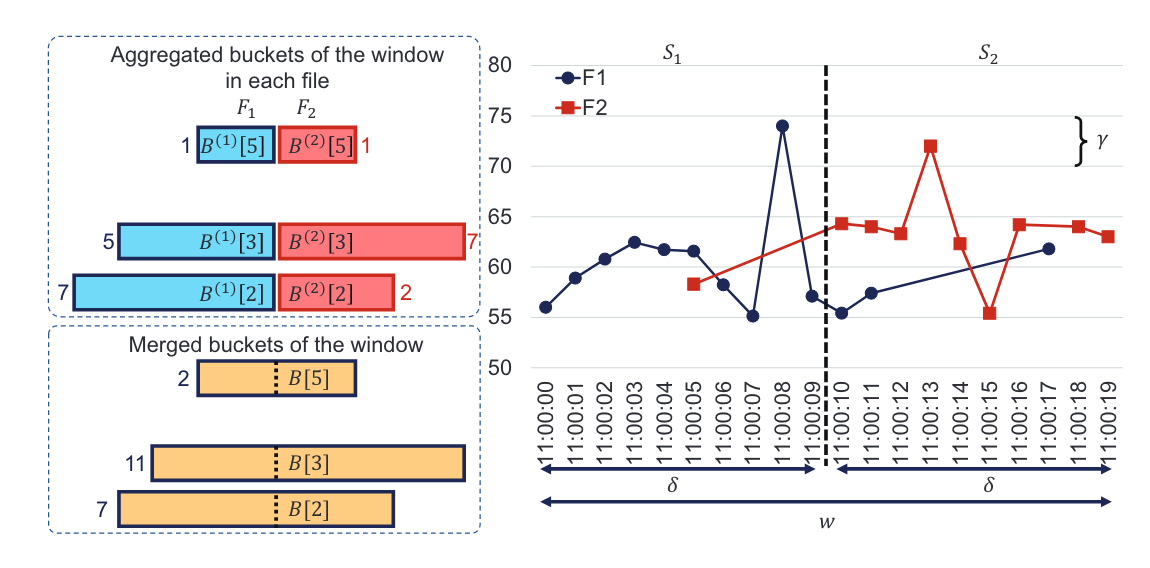
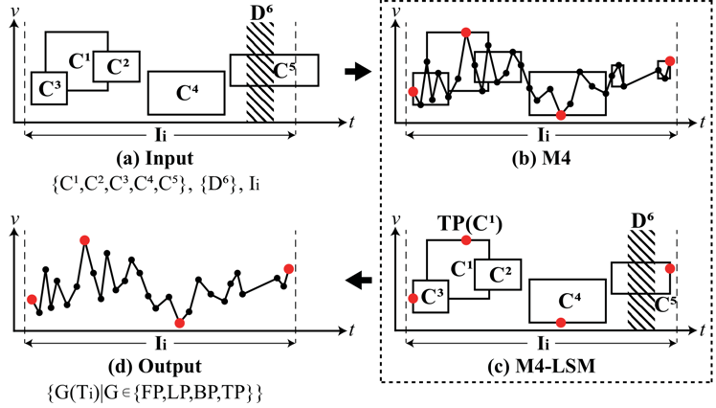
SIGMOD 2024: Time Series Representation for Visualization in Apache IoTDB
First Author: Rui Lei
Time-series data is critical across industries like finance, transportation, and meteorology, yet efficiently visualizing large-scale datasets remains challenging. M4-LSM, an innovative method in Apache IoTDB, combines the M4 representation technique with LSM-tree storage structures to address this issue.
The M4 representation generates two-tone line charts (e.g., black-and-white) while preserving key data features like trends and shapes. M4-LSM optimizes this process by utilizing LSM-tree metadata, avoiding unnecessary data loading and merging. It further introduces stride regression for locating relevant blocks and value regression for selecting critical points, enhancing both efficiency and precision.
Experiments show that M4-LSM significantly reduces query times while maintaining visualization accuracy, making it an effective solution for time-series data visualization.
DOI: 10.1145/3639290