

Introduction
As we all know, when the business load of a database service increases, it's often necessary to expand the service resources. Generally, there are two ways to scale: vertical scaling and horizontal scaling.
Vertical scaling refers to increasing the capabilities of a single machine, such as adding more memory, hard drives, and more powerful processors. This method has a limitation: the hardware capabilities of a single machine have an upper limit. Horizontal scaling, on the other hand, involves adding more machines, distributing the data and processing requests across multiple machines. This method is more flexible because machines can be added indefinitely, with almost no upper limit. With the advent of the big data era, horizontal scaling has become increasingly popular due to its cost-effectiveness and flexibility, leading more systems to explore distributed solutions.
Why can distributed systems utilize the resources of multiple machines to improve the read and write performance of databases? The key lies in distributing data across multiple nodes, converting a single request's data access into multiple nodes accessing parts of the data. This involves two important designs: sharding and load balancing.
Data Sharding: Splitting a large volume of data into smaller parts, distributing them across multiple nodes to improve storage and query performance.
Load Balancing: Dynamically distributing data and workloads across the cluster, charing the load among all nodes, thereby improving overall cluster performance and stability.
Apache IoTDB is designed with specific sharding and load balancing strategies for scenarios where recent data operations are frequent and historical data operations are less frequent. This article delves into these key designs to help you understand and master IoTDB's sharding strategy, making more effective use of each machine's resources to enhance cluster performance.
Concepts and Principles
In IoTDB, sharding is referred to as RegionGroup, and both metadata and data are sharded (SchemaRegionGroup and DataRegionGroup).
Note:
Metadata mainly includes the definition information of time series, which describes the data.
Data primarily includes timestamps and measurement values, which change over time.
To facilitate understanding, this article will not consider the consistency issue between multiple replicas within a single RegionGroup. This will be detailed in the next blog post.
Metadata Sharding Principles
The metadata sharding logic in IoTDB is shown in the figure below:
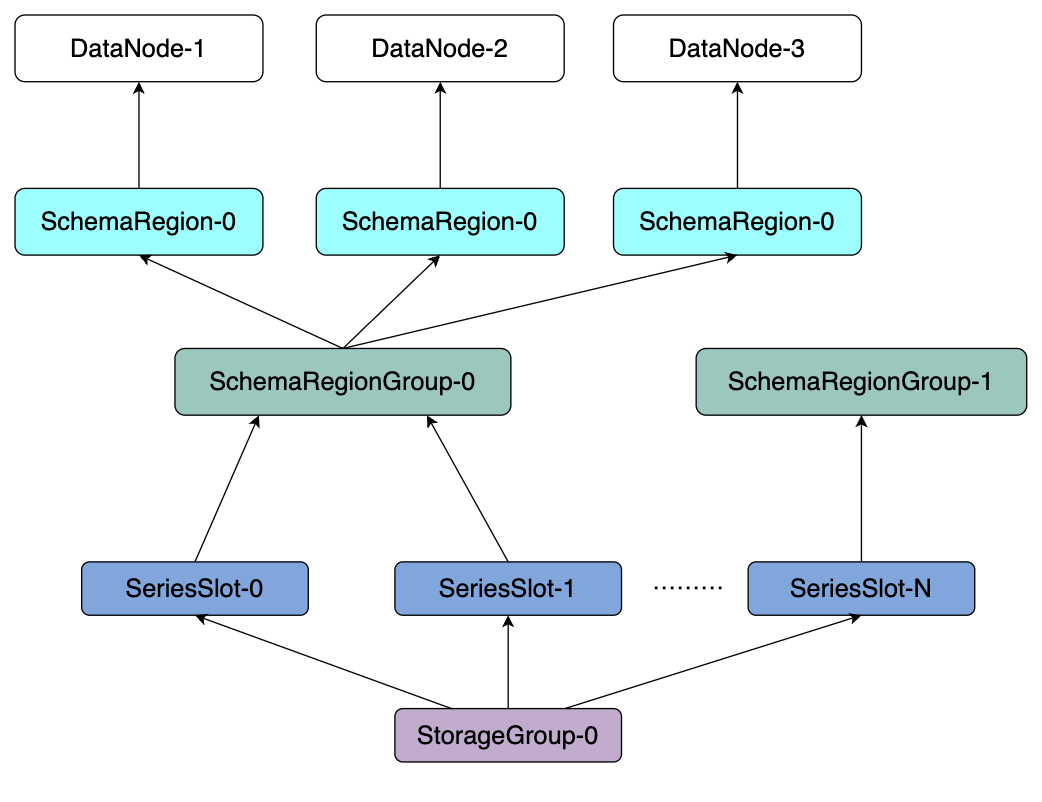
The core logic includes:
All metadata in a database is hashed into a specific series slot (SeriesSlot, default is 1000) based on the device name.
Different series slots are allocated to different SchemaRegionGroups based on a load balancing strategy.
Different SchemaRegionGroups are allocated to DataNodes based on a load balancing strategy.
A specific example of what happens when creating a series in an IoTDB cluster will help understand this. First, the user creates metadata by executing the SQL statement create timeseries root.db.d.s with datatype=boolean. When IoTDB receives this request:
It calculates the hash value of the device name, e.g.,
Hash(root.db.d) % 1000 = 2, indicating that the device should be in series slot 2.For series slot 2:
If it does not exist before, it will be assigned to the SchemaRegionGroup with the least series slots to ensure load balancing.
If it exists and has already been assigned to a SchemaRegionGroup, this allocation relationship remains unchanged.
The metadata is stored in the assigned SchemaRegionGroup, requiring a request to the DataNode that owns this SchemaRegionGroup.
With this scheme, all devices are evenly distributed across all SeriesSlots using a hash algorithm. The dual-layer mapping from SeriesSlot to SchemaRegionGroup and from SchemaRegionGroup to DataNode ensures even distribution via load balancing algorithms, allowing metadata read and write operations to utilize all nodes’ resources in parallel evenly.
Remarkably, this scheme maintains a fixed cost for routing information of shards regardless of the number of devices (whether thousands or billions), while specific metadata management can be distributed across the cluster. This gives Apache IoTDB extremely high scalability in handling large-scale time series metadata, supporting up to tens of billions of data points in tests.
Data Sharding Principles
The data sharding logic in IoTDB is illustrated in the figure below:
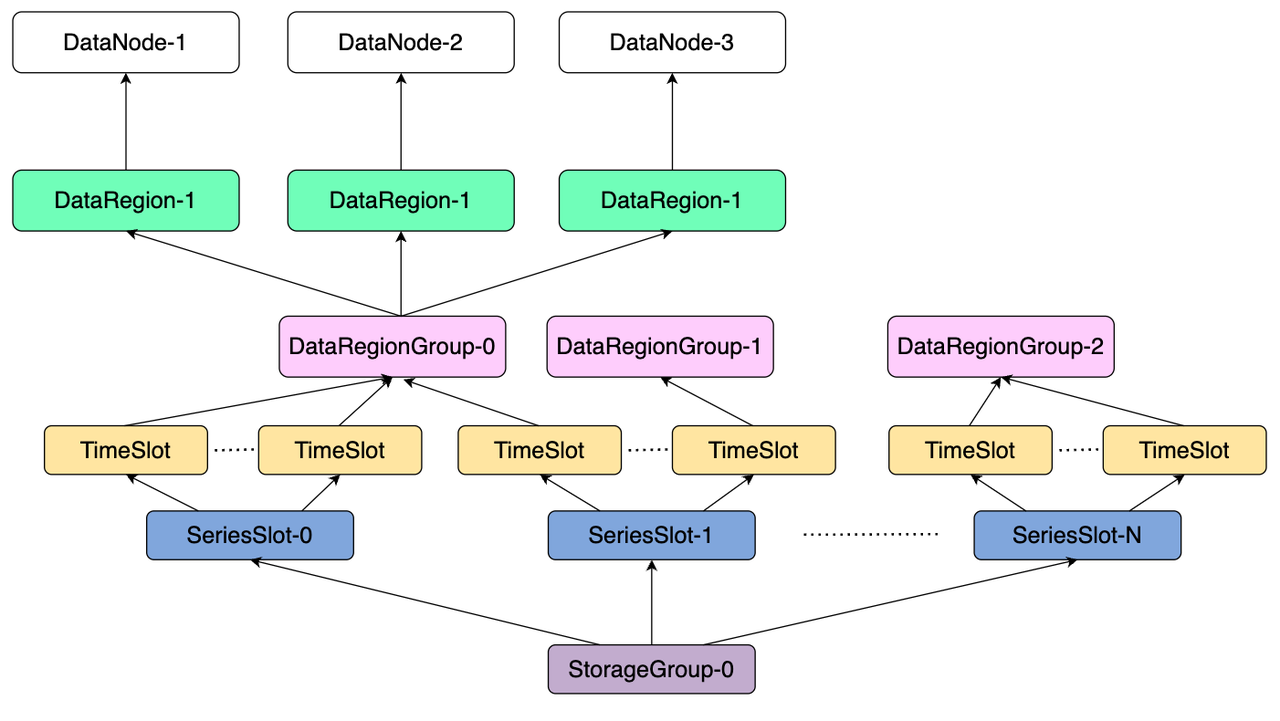
Compared to metadata sharding, data sharding introduces an additional time slot (TimeSlot), meaning:
All data in a database is first hashed into a specific series slot (SeriesSlot, default is 1000) based on the device name.
Then, based on the time range of the data (default one week per range), it is assigned to a specific time slot (TimeSlot).
A data segment determined by the series slot and time slot (DataPartition) is assigned to different DataRegionGroups based on the load.
Let’s take a specific example of what happens when inserting new data into an IoTDB cluster. When a user triggers data writing via the SQL statement insert into root.db.d(times) values(11):
Assume
Hash(root.db.d) % 1000 = 2, indicating the device should be in series slot 2. Then, time slicing of the timestamp 1 is performed:1 / 604800000 = 0, so it is assigned to time slot 0 (one week per interval, with 604800000 as the number of milliseconds in a week).For DataPartition-2-0:
If it does not exist before, it is assigned to the DataRegionGroup with the least DataPartitions to ensure load balancing.
If it exists and has already been assigned to a DataRegionGroup, this allocation relationship remains unchanged.
The data is written to the assigned DataRegionGroup, requiring a request to the DataNode that owns this DataRegionGroup.
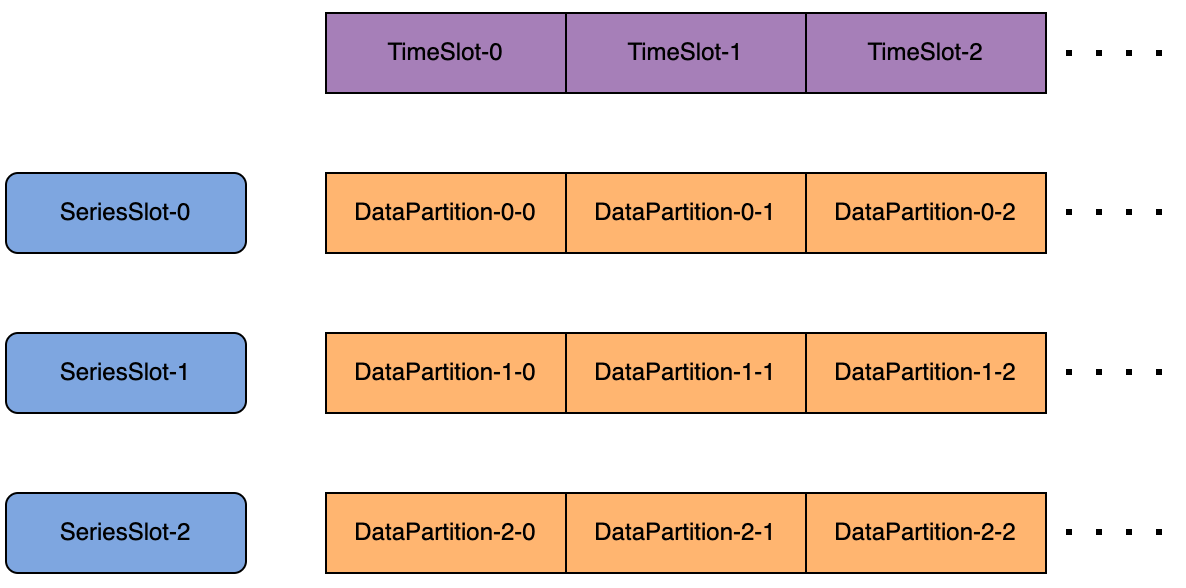
Through this scheme, read and write traffic for all devices is evenly distributed across all SeriesSlots using a hash algorithm, then calculated into TimeSlots and their corresponding DataPartitions. The dual-layer mapping from DataPartition to DataRegionGroup and from DataRegionGroup to DataNode ensures even distribution via load balancing algorithms, allowing data read and write operations to utilize all nodes’ resources in parallel evenly.
Notably, this scheme maintains a lightweight cost for routing information of shards regardless of the number of devices (whether thousands or billions) or the time span (1 year or 10 years). Specific time series data management can be distributed across the cluster, giving Apache IoTDB unmatched scalability in handling large-scale time series data, supporting up to petabyte-level time series data storage in tests.
Why Add Time Dimension to Data Sharding?
You might wonder why it is necessary to add a time dimension to data sharding, and what is wrong with keeping a device's data always on a single node. This stems from our in-depth consideration of the business characteristics of time series scenarios.
In a Share-Nothing architecture, scaling up inevitably involves moving large amounts of data to utilize new node resources. Data migration, no matter how throttled and optimized, impacts real-time read and write loads. So, is it possible to avoid data migration when scaling up in time series scenarios? This requires considering the characteristics of time series scenarios.
First, in traditional KV loads, we cannot predict whether the next request will write to a or z. However, in time series scenarios, like IoTDB’s strengths in IoT, real-time read and write traffic is often concentrated in recent time partitions, while read and write traffic in older time partitions gradually decreases. Secondly, compared to internet scenarios, time series scenarios have more predictable loads, generally not experiencing large fluctuations in a short period. Based on these considerations, Apache IoTDB was designed cleverly to avoid data migration during scaling and was applied in certain scenarios with positive feedback.
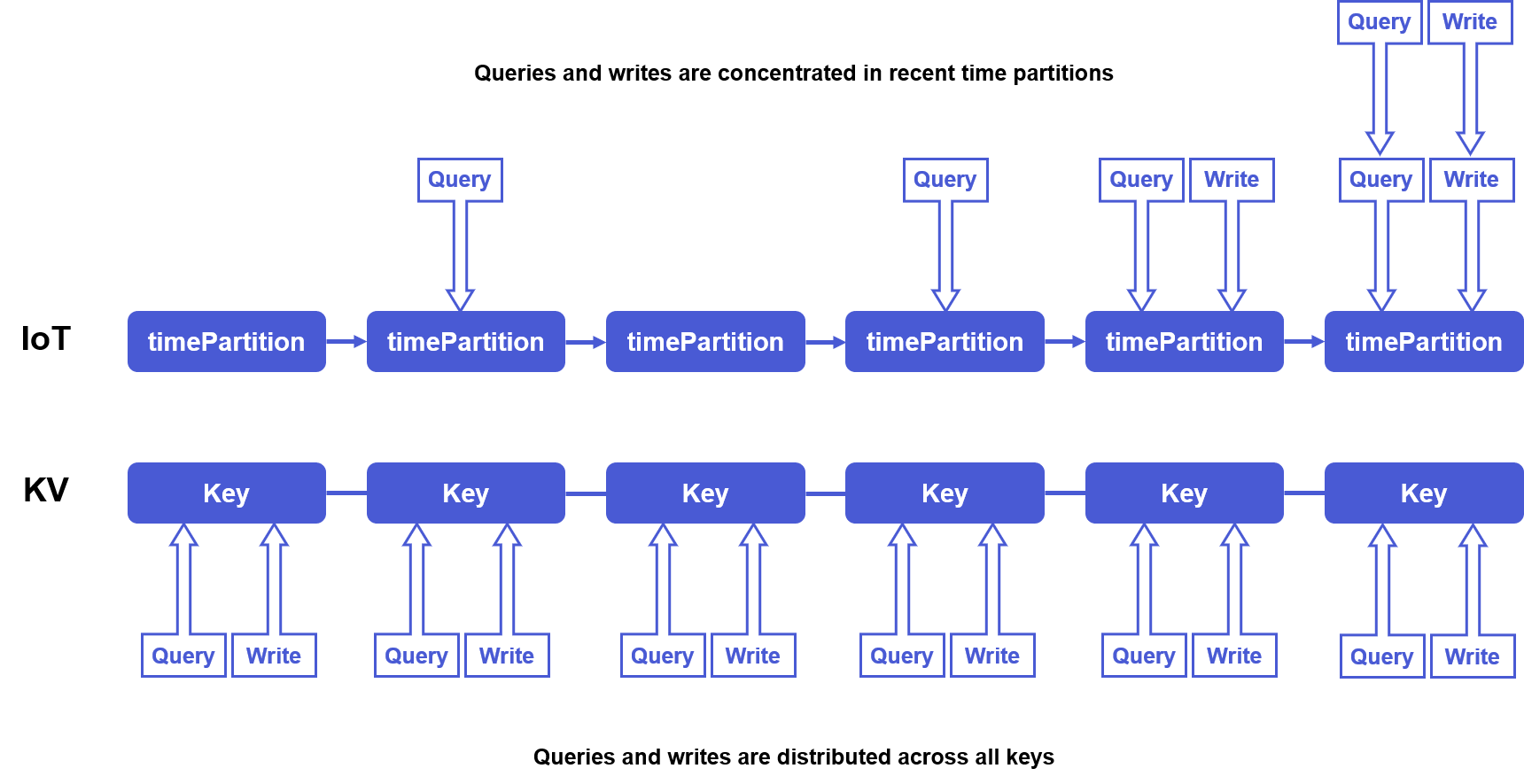
When IoTDB scales DataNode nodes, we can directly assign part of the DataPartition under new time slots to new DataRegionGroups created on new nodes. This way, even without moving data, computing resources can be balanced. At this point, the disk capacity of old and new nodes will differ, with old nodes having more disk capacity.
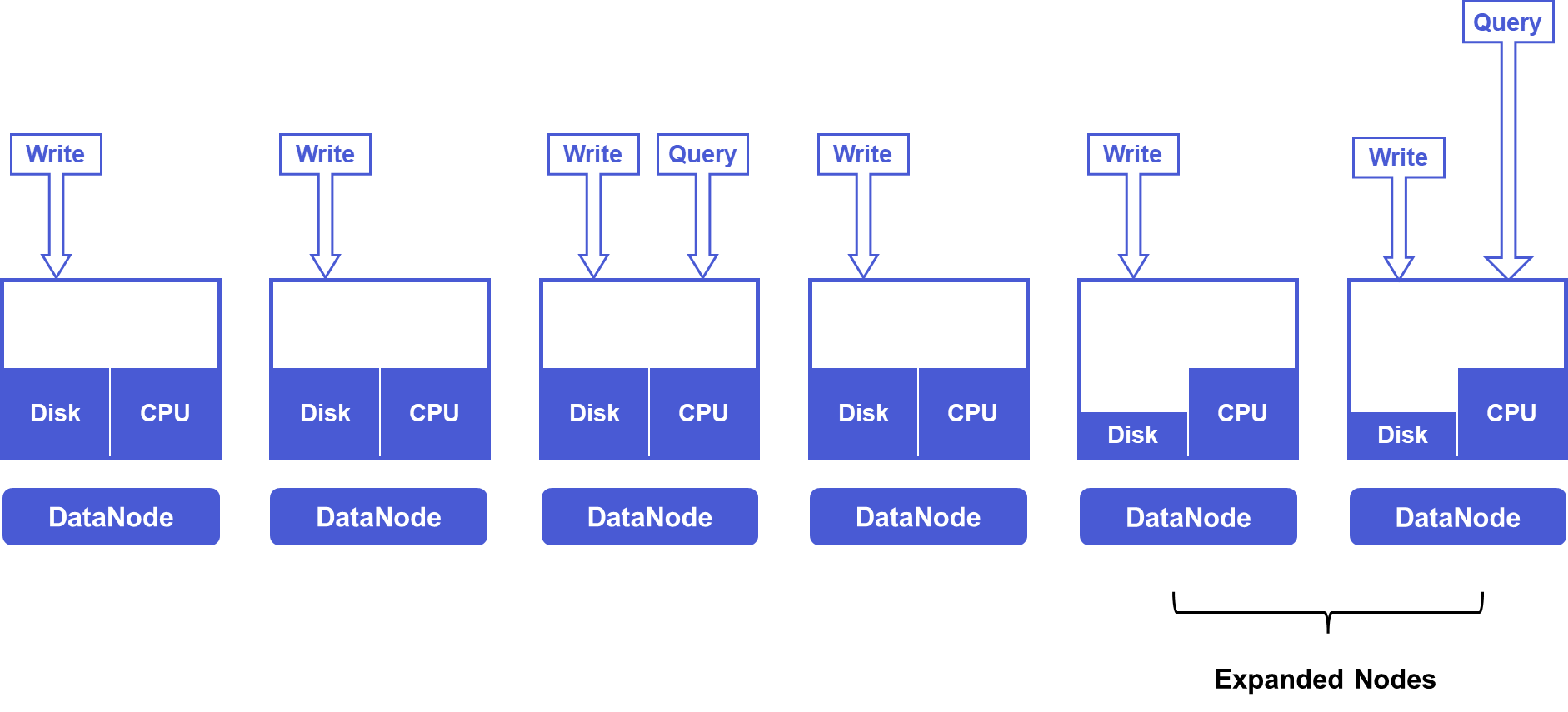
However, time series scenarios typically set a Time To Live (TTL) attribute. As time passes, outdated data on old nodes will be gradually deleted, while new data will gradually increase on new nodes. After a TTL cycle, storage and computing resources across all nodes will be balanced. Through a TTL cycle, we can achieve resource balance without moving data while utilizing new node resources.
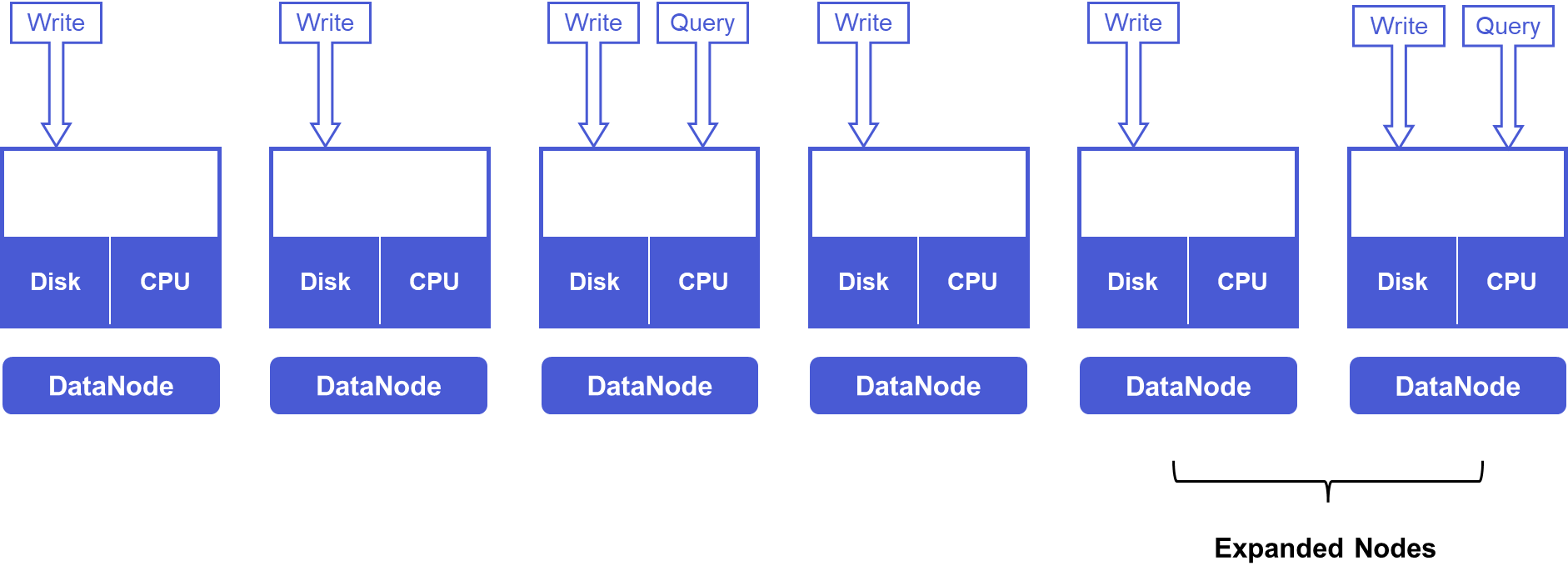
Of course, this optimization requires businesses to estimate and plan in advance to achieve scaling without data migration throughout the cycle. If the business does not plan well or is inconvenient to implement, IoTDB also provides Region migration instructions for operation and maintenance personnel to manually balance loads flexibly.
Sharding Example in Distributed Cluster
Now that we understand the logical concepts of data and sharding, let's see how it applies to actual nodes, using the 3C3D cluster (3 ConfigNodes and 3 DataNodes Cluster) mentioned in the previous article as an example. After adding the sharding strategy, the architecture is as follows:
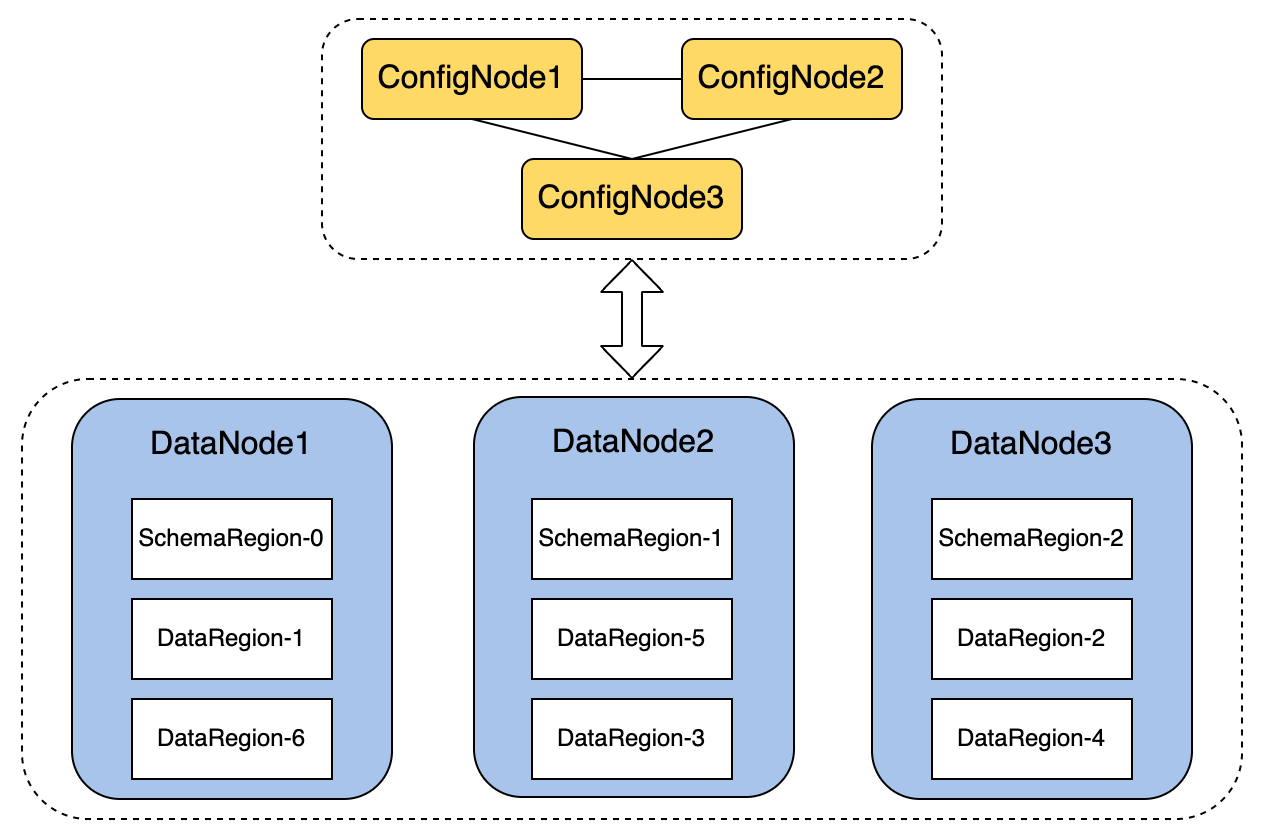
Each DN node manages multiple Regions (including SchemaRegion and DataRegion), determined by several parameters in iotdb-common.properties:
schema/data_region_group_extension_policy: Region extension pattern.CUSTOM: Each database directly createsdefault_schema/data_region_group_per_databaseSchemaRegionGroups/DataRegionGroups upon the first write and does not expand further.AUTO: Each database rapidly expands todefault_schema/data_region_group_per_databaseSchemaRegionGroups/DataRegionGroups during the initial increase in the number of devices. Later, it automatically expands based on cluster resource conditions, up toschema/data_region_per_data_nodeRegions per node.
default_schema/data_region_group_num_per_database: The number of RegionGroups per database.schema/data_region_per_data_node:The number of Regions per node, effective only when
schema/data_region_group_extension_policyisAUTO, determining the maximum number of Regions a single DataNode can hold when expanding Regions.If the current DN holds data from multiple databases, the number of Regions can exceed this value (as one database will have
default_schema/data_region_group_per_databaseRegions). If the number of Regions on this DN already exceeds this value, subsequent Region expansion will not trigger.
Common Operations
How to Check Sharding in the Database?
In IoTDB, you can check the current sharding status of the cluster using SQL statements.
IoTDB> show regions
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+
|RegionId| Type| Status|Database|SeriesSlotNum|TimeSlotNum|DataNodeId|RpcAddress|RpcPort|InternalAddress| Role| CreateTime|
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+
| 0|SchemaRegion|Running| root.db| 1| 0| 1| xxxxxxx| 6667| xxxxxxx|Leader|2024-05-27T14:38:16.654|
| 1| DataRegion|Running| root.db| 1| 1| 1| xxxxxxx| 6667| xxxxxxx|Leader|2024-05-27T16:33:30.359|
+--------+------------+-------+--------+-------------+-----------+----------+----------+-------+---------------+------+-----------------------+SeriesSlotNum=1 indicates that a single replica of SchemaRegionGroup 0 is assigned one SeriesSlot, located on DataNode 1. SeriesSlotNum=1 TimeSlotNum=1 indicates that a single replica of DataRegionGroup 0 is assigned one SeriesSlot and one TimeSlot, also located on DataNode 1.
How to Manually Load Balance?
In most cases, IoTDB's default sharding and load balancing strategy can ensure load balancing among all RegionGroups and DataNodes. However, in specific deployment and usage scenarios, if you observe unequal loads of CPU, IO, memory, etc., among different nodes, you can check the number of Regions, Leaders, and assigned SeriesSlots and TimeSlots on different DataNodes using the show regions command. If imbalances are found, consider manually performing Region migration operations to rebalance the cluster load.
How to Configure the Number of Shards?
Since each RegionGroup internally executes almost serially, the total number of RegionGroups in the cluster can generally be bound to the hardware resources of the nodes.
You can reasonably set the number of RegionGroups per database by setting the default_data_region_group_per_database and default_schema_region_group_per_database parameters in iotdb-common.properties.
In general, the total number of SchemaRegionGroups in an IoTDB cluster should match the number of nodes divided by the number of replicas. The total number of DataRegionGroups should match the total number of CPU cores in the cluster divided by the number of replicas. This setup can effectively utilize the parallel computing capabilities of the nodes in most cases.
Conclusion
Sharding and load balancing are crucial architectural designs in distributed systems. Apache IoTDB not only evenly maps each piece of data and metadata to RegionGroups, achieving logical sharding and load balancing among RegionGroups but also creatively achieves resource balance during scaling without migrating data by deeply considering time series scenarios.
This design effectively solves the performance bottlenecks and data migration costs faced by traditional systems during scaling, ensuring high efficiency and stability when handling large-scale IoT data. Additionally, this architecture can intelligently adjust based on data access frequency and patterns, further optimizing resource utilization and enhancing overall system performance and responsiveness.
Through this article, you have gained an in-depth understanding of IoTDB's sharding and load balancing strategies, mastered their advantages and operational techniques in practical applications, and are expected to use IoTDB to better handle complex IoT data management challenges.
In the next blog post, we will unveil the unique consensus module design of IoTDB.
Stay tuned!
Authors
This blog is a collective effort by several dedicated contributors from the Apache IoTDB community. We appreciate the valuable input and thorough reviews from our community members, ensuring the accuracy and quality of this publication.
For any questions or further discussions, please feel free to reach out to Xinyu Tan (tanxinyu@apache.org), senior software engineer at Timecho and one of the authors.
We look forward to hearing from you!


