

In the article Apache IoTDB: 7 Features for Embedded-Edge-Cloud Sync, we introduced the functionalities and advantages of IoTDB's embedded-edge-cloud synchronization technology. This powerful solution helps enterprises achieve efficient and reliable one-stop management of edge-cloud data in multi-level time-series data management scenarios.
IoTDB provides users with an efficient data synchronization solution through concise and flexible SQL operations and intuitive configuration methods. With just a few simple SQL commands, users can set up and launch IoTDB's edge-cloud synchronization tasks, enabling seamless data flow between endpoints, edges, and the cloud.
Today, we’ll delve into five common use cases of IoTDB edge-cloud synchronization and explore how easy it is to implement them.
Scenario 1: Basic Data Synchronization
Modes:
Full Data Synchronization: Transfers all data from one IoTDB instance to another, ensuring high availability and security. It is particularly useful in scenarios like data backup, disaster recovery, and data migration.
Range Data Synchronization: Transfers data for specific time ranges or measurement points from one IoTDB instance to another. This is commonly used for selective data backup and recovery.
IoTDB enables full or range data synchronization with a single SQL command, eliminating the need for third-party tools and simplifying data migration. Additionally, IoTDB's internal optimizations minimize CPU and memory usage, ensuring minimal disruption to cluster operations during migration.

The specific SQL statement for the full data synchronization task is as follows:
CREATE PIPE A2B
WITH SINK (
'node-urls' = '127.0.0.1:6668,127.0.0.1:6669'
)node-urls refers to the target node addresses for data synchronization, and it can accept multiple addresses. In this example, the full data synchronization task A2B is configured with two target nodes: 127.0.0.1:6668 and 127.0.0.1:6669. In this case, the sender A will evenly split and send data to the two target nodes.
The specific SQL statement for the range data synchronization task is as follows:
CREATE PIPE A2B
WITH SOURCE (
'path'= 'root.EnergyGroup.WindFarm.**',
'start-time' = '2024.08.01T08:00:00+00:00',
'end-time' = '2024.09.01T08:00:00+00:00'
)
WITH SINK (
'node-urls'='127.0.0.1:6668'
)The path field specifies the measurement points to synchronize, while start-time and end-time define the time range.
Scenario 2: Data Downsampling Synchronization
This feature synchronizes data from one IoTDB instance to another while downsampling high-frequency data into lower-frequency data. It is commonly used in hierarchical data aggregation scenarios (e.g., factory → regional → central) to reduce storage pressure and improve processing efficiency.
In IoTDB, this functionality can be achieved by creating a data synchronization task with downsampling rules.
CREATE PIPE a2b
WITH PROCESSOR (
'processor' = 'changing-value-sampling-processor'
)
WITH SINK (
'node-urls' = '127.0.0.1:6668'
)In this case, the processor needs to be configured as a data downsampling processing plugin. The enterprise-grade TimechoDB can directly use the built-in plugin changing-value-sampling-processor (or the trend change downsampling based on the Swinging Door Algorithm, swinging-door-trending-sampling-processor, or time-window-based downsampling, tumbling-time-sampling-processor). This plugin is used to detect value changes in the data stream, allowing the data synchronization pipeline to synchronize data only when value changes occur, thereby reducing the amount of data transmitted. In the open-source version, users can implement the logic themselves and import the plugin into IoTDB for use.
Scenario 3: Cascaded Data Synchronization
This mode supports chaining data synchronization tasks across multiple nodes, ensuring data consistency and coherence in scenarios such as station-to-station data linkage.
In the IoTDB system, multiple synchronization tasks can be set up on the chain to achieve cascaded data synchronization: each synchronization task is responsible for transferring data from the current node to the next node, thus implementing a cascaded transfer mode such as A->B->C.

To build a three-level synchronization as shown in the diagram A->B->C, the following needs to be executed on Node A:
create pipe A2B
with sink (
'node-urls'='127.0.0.1:6668'
)On Node B:
create pipe B2C
with sink (
'forwarding-pipe-requests' = 'true',
'node-urls'='127.0.0.1:6669'
)The forwarding-pipe-requests parameter enables data received from Node A to be forwarded to Node C.
Scenario 4: Bidirectional Data Synchronization
This feature mirrors data between two IoTDB instances in real time, ensuring data consistency. It is widely used in dual-active deployments, disaster recovery, and backups.

To achieve bidirectional data synchronization between instances A and B, execute the following SQL on Node A:
CREATE PIPE A2B
WITH SOURCE (
'forwarding-pipe-requests' = 'false',
)
WITH SINK (
'node-urls'='127.0.0.1:6668'
)On Node B:
CREATE PIPE B2A
WITH SOURCE (
'forwarding-pipe-requests' = 'false',
)
WITH SINK (
'node-urls'='127.0.0.1:6667'
)The forwarding-pipe-requests parameter is set to false to prevent infinite loops (TimechoDB feature).
Scenario 5: Cross-DMZ Data Synchronization
In high-security industries, cross-DMZ synchronization ensures secure data transfer between networks with different security levels, often using data diodes. In industries such as electricity, network security is crucial. Therefore, the entire system network is carefully divided into four zones with different security levels. Security Zone I is the production control zone, responsible for critical real-time control tasks; Security Zone II is the production non-control zone, providing auxiliary production support; Security Zone III is the production management zone, handling production management tasks; and Security Zone IV is the management information zone, focusing on administrative management and decision support.
Between Security Zone II and Security Zone III, the system interacts through a unidirectional data diode. The forward isolation mechanism allows high-security-level systems to send operational commands to lower-security-level systems, while reverse isolation allows lower-security-level systems to transmit data to higher-security-level systems. Although this isolation diode physically ensures the security of the production control zone, it also presents challenges for data synchronization between Security Zone II and Security Zone III.
IoTDB supports cross-DMZ synchronization with built-in plugins, adapting to data synchronization under models such as Syskeeper2000.
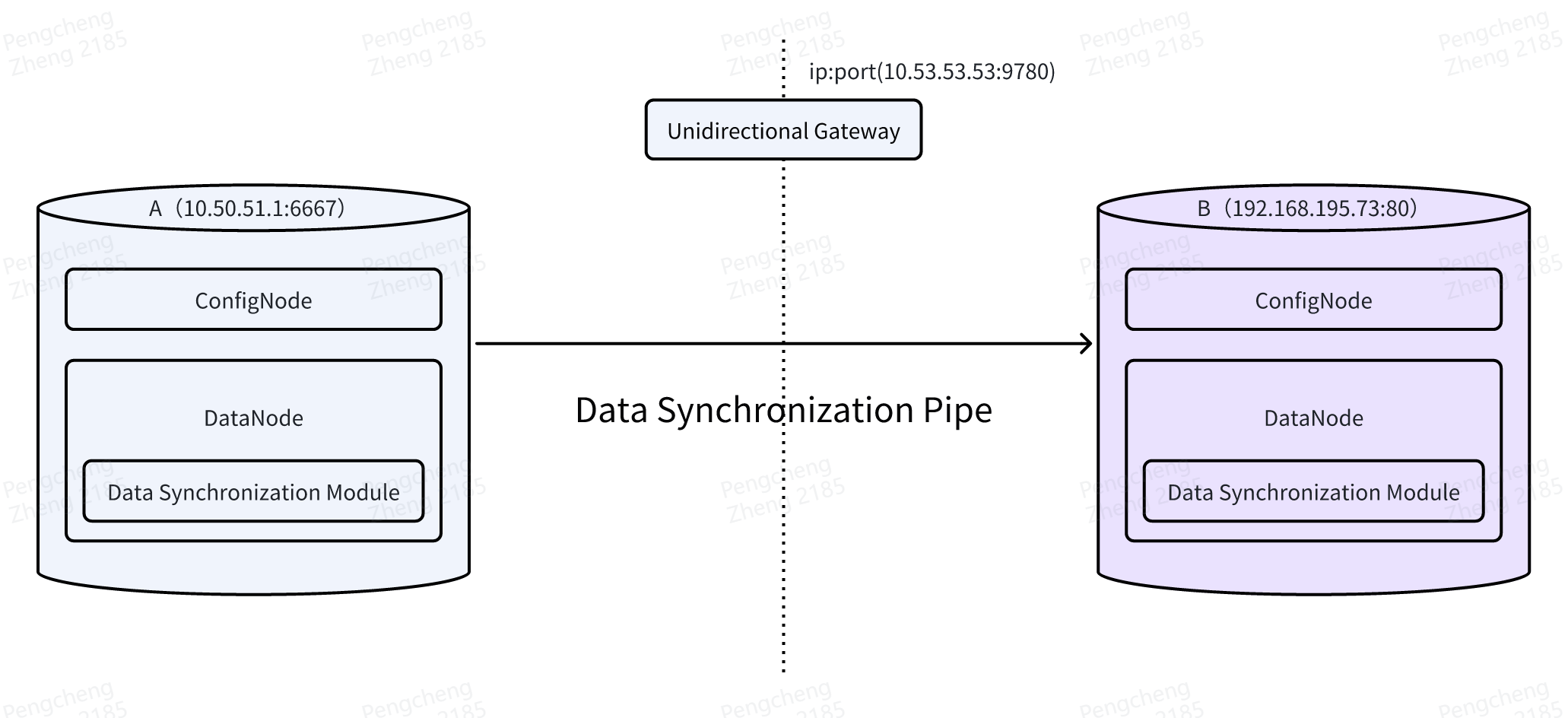
To achieve the data synchronization shown in the diagram, you can use the following SQL:
create pipe A2B
with sink (
'sink'='iotdb-air-gap-sink',
'sink.node-urls'='10.53.53.53:9780'
) The sink needs to be configured with a dedicated data diode processing plugin. In the enterprise-grade TimechoDB, you can directly use the built-in plugin iotdb-air-gap-sink, which is specifically designed for data transmission through a unidirectional data diode, ensuring the security and compliance of data transfer. In the open-source version, you can implement the logic yourself and import the plugin into IoTDB for use.
Conclusion
IoTDB’s edge-cloud synchronization capabilities offer unmatched flexibility and simplicity. All the operations described above can be executed with a single SQL command. Features like encryption, compression, and custom plugin development further enhance its utility for advanced use cases.
For detailed guidance, refer to the user manual. Start exploring IoTDB’s potential today!


