

Presenter: Dr. Julian Feinauer, CEO of pragmatic industries GmbH
Thank you very much for a nice introduction, and thanks for having me here. It's a great honor for me to speak in front of you. I will try to speak slowly and clearly that hopefully everybody can follow.
I am from Germany and I was asked to talk a bit about the German industry. We heard many use cases of Apache IoTDB, and all of them I think are from China, where IoTDB is quite popular already. I will share 2 concrete use cases that we have done in Germany.
So what do I want to talk about? First, I will talk shortly about digitization in Germany. It's very impressive for me to see how companies in China handle things, and I will talk a bit about how things usually go in Germany in the industry. Then I will shortly present the framework, the Open MAchine Platform that we are developing to help integrate IoTDB in applications. And then I have 2 use cases, one about fuel cell application at German railway, a cooperation, and one called Smart Core, which is an application at automotive foundry.
01 Digitalization in Germany
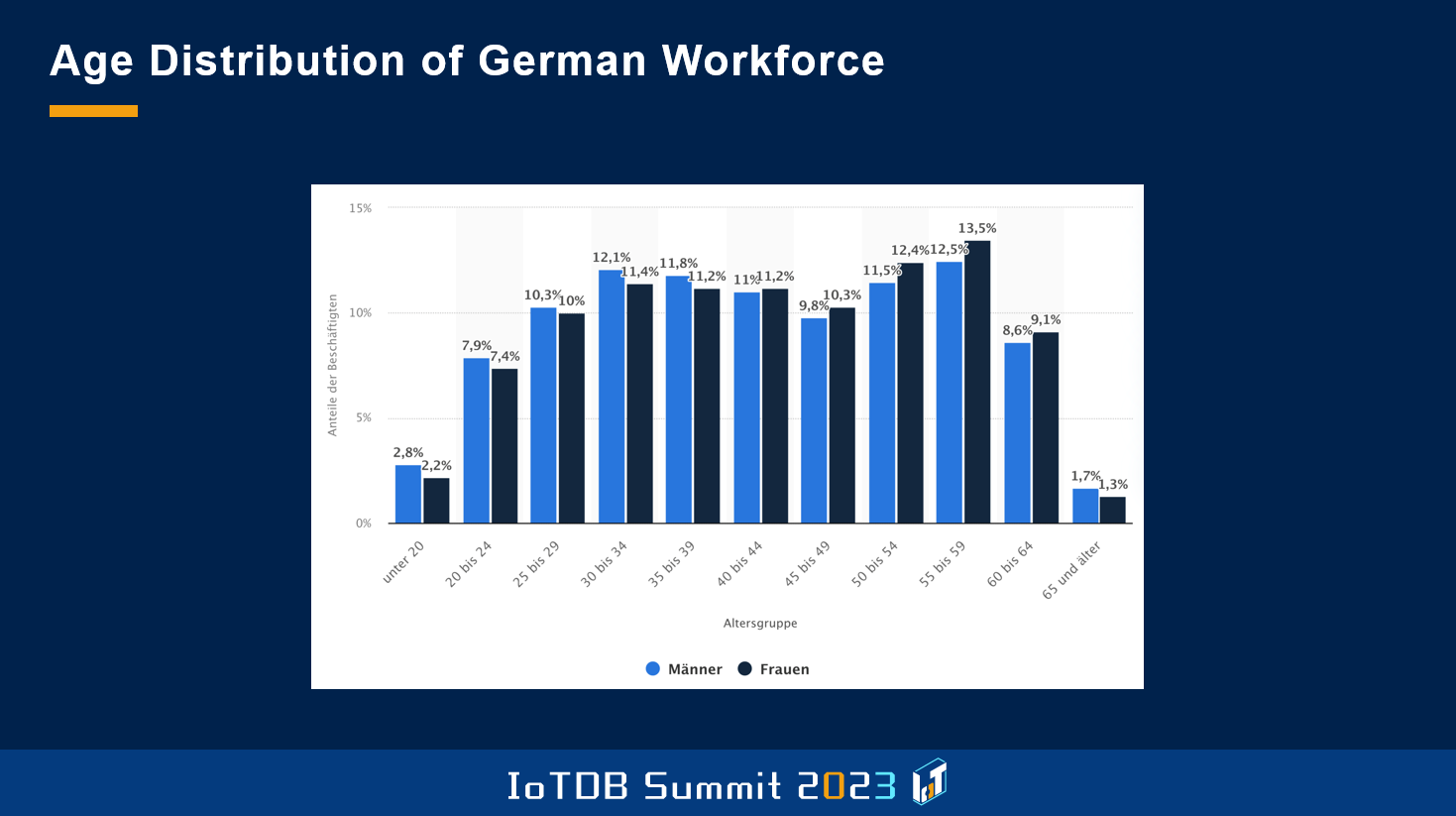
So where are we at in Germany? This is the age distribution of the German workforce, and as you see, it's screwed a bit towards the right. So the average age of a German worker is 45 years, which on the other hand means that those people usually are not super IT-experienced, which is kind of a burden for us to introduce new technologies.
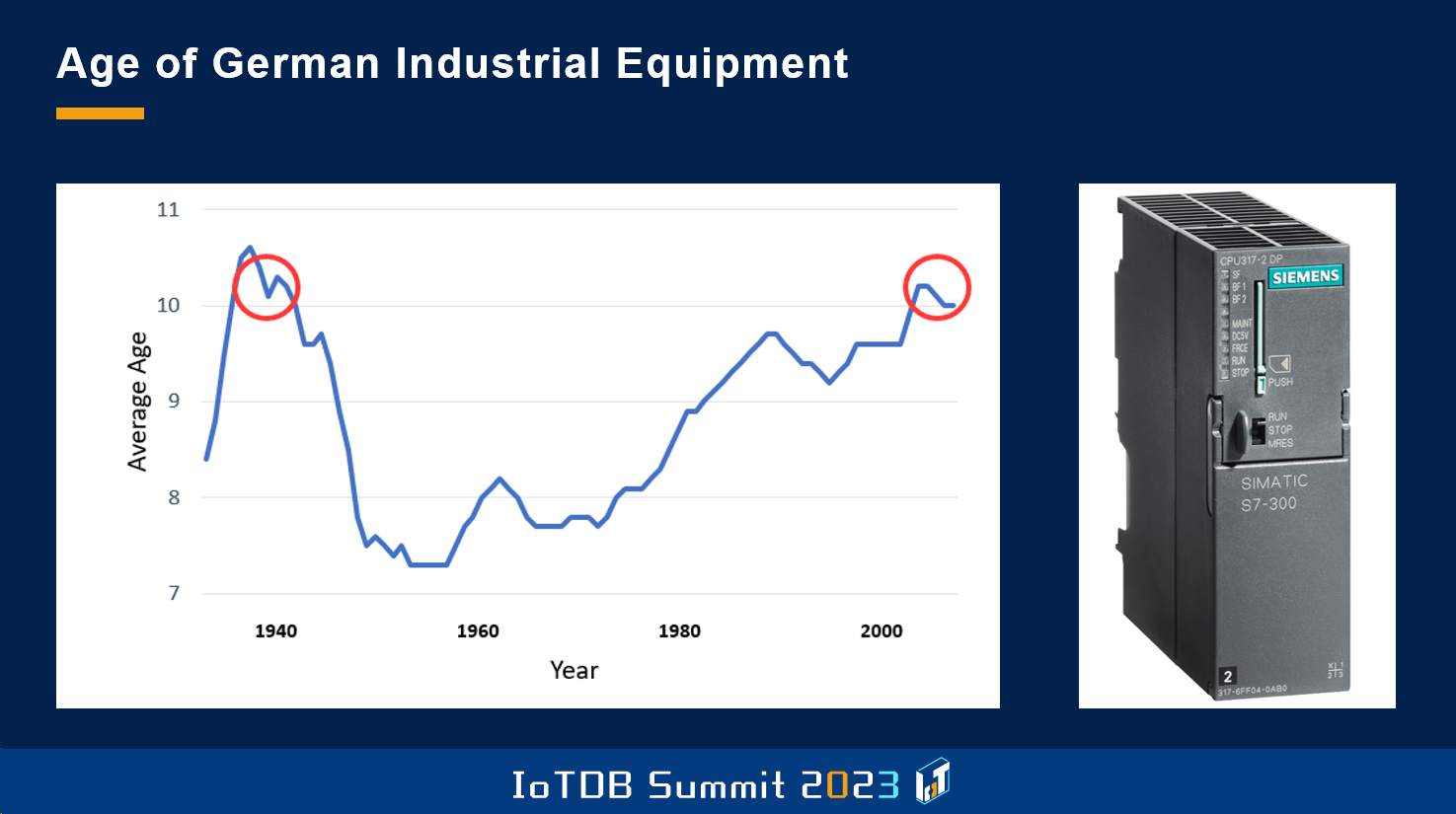
The second slide here is the age of the typical German machines in our plants. The average age of the machinery in German plants is over 11 years, so our assets are quite old, which has the downside that the control systems in those machines are very old. So this is a typical example, Siemens S7-300 device, which is very common in those machines. And it's very hard to interfere with these devices and to collect data from those machines.
The last aspect, for me, it was really interesting to see how many use cases in Chinese industry really focus on the data in depth, because a lot of companies in Germany don't have designated data scientists or people that are able to work with the raw data. So we usually have to aggregate the data quite a bit, so that the operators on the machines or the leaders of the shifts or the managers of the plant get the information out. This is nothing that typically German companies to bind themselves. So these are typical examples of the results we have to provide, which is just some numbers about throughput, efficiency of the factory, and things like this.

02 Building Industrial Applications
This leads me to the next point. So we do not focus so much on the raw data, and sometimes we don't have that much data. For us, it's more important to have a nice integration in the sense of a full stack, so that we are able to provide our customers and these companies with exactly what I said, from the data collection up to calculated metrics and KPIs that they are interested in to run their plant more efficiently.
Usually, when you develop these kinds of solutions, many of you might notice, then you need very basic things. You need user management, asset management, then of course, data management. For time series data, we need some kind of analytics system or calculation of metrics. And as I said, it's quite important for us to have a nice visualization which is suited not only for experts but for regular people that do not look at these kinds of chances daily.

Because we are probably now in the domain of classical application development, the developers dealing with IoTDB oftentimes are no database experts. They are regular developers, web developers, backend developers, etc. And as Django is quite popular in this area, one of the first things we did was to develop a framework called Django_IoTDB, which makes it very easy to integrate IoTDB with Django, so that you don't need to be an expert in IoTDB and the query language.
So we have an abstraction, which makes it quite easy to fetch data without the need to fully understand the syntax with all its details, how does the "group by" work, and things like this. So this makes it way easier, more accessible for developers to write applications based on IoTDB.

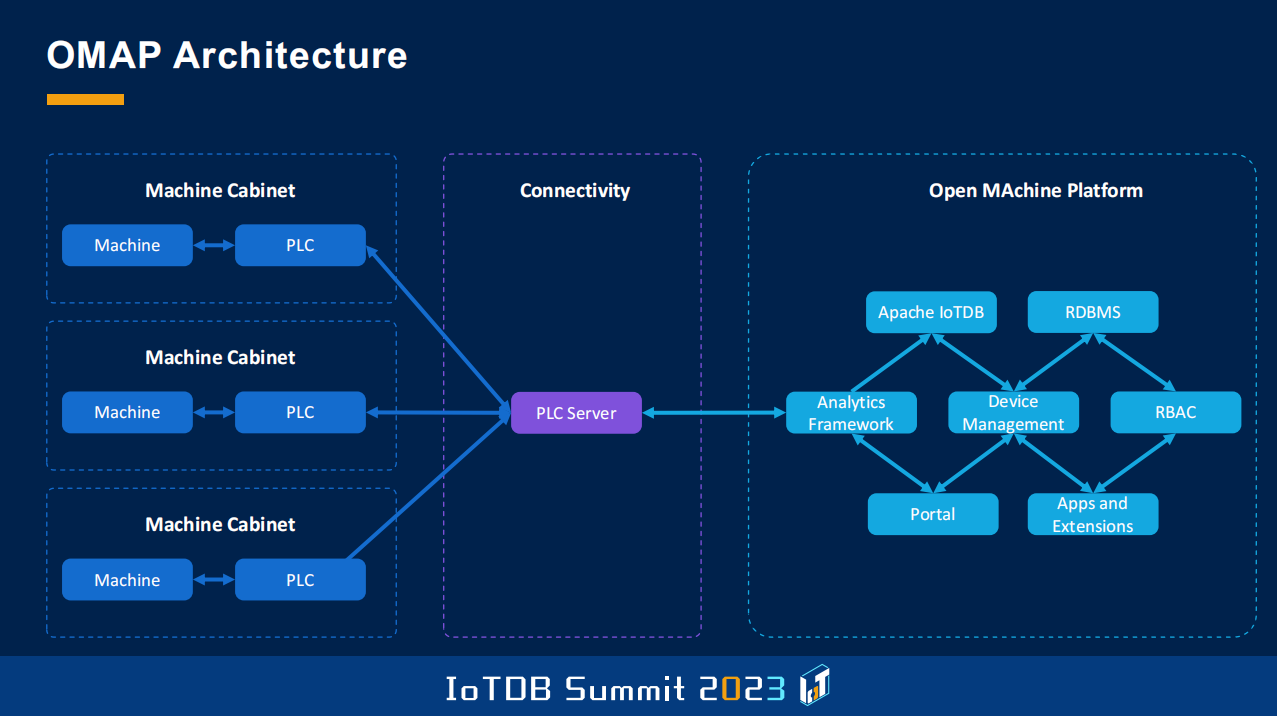
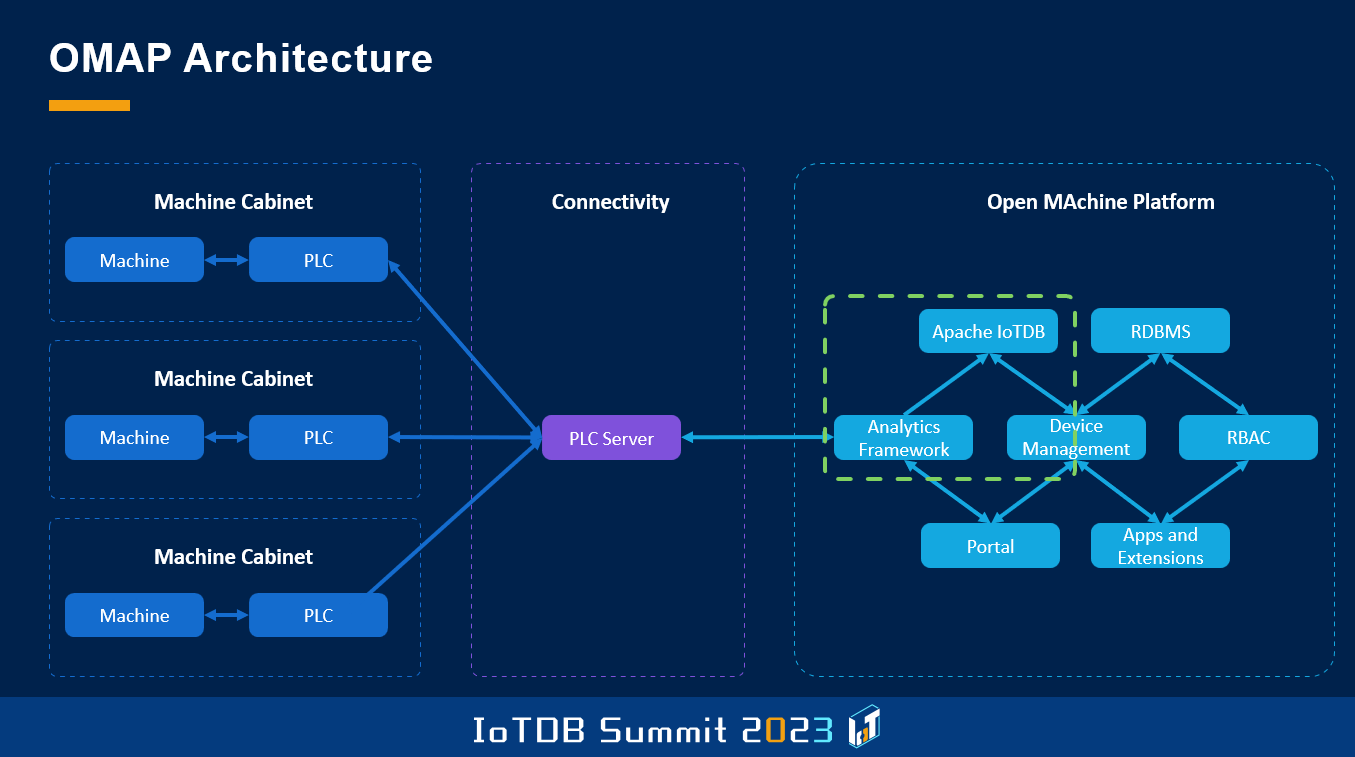
Another thing that we have developed is a framework, we call the Open MAchine Platform, which solves exactly the problem I've talked about earlier, that we need a certain set of preconditions, user management, asset management, all these things. So this framework basically serves as the baseline to start off for the kind of project I've talked about.

Here you see a bit of the architecture. What is very important for us is the thing called PLC server, which is based on another open-source project, Apache PLC4X, which is right at this time presented at the other room, which we used to gather data from those different machines. And then on the right side, you see the structure. It's based on several modules. Very important for us are things like Role-Based Access Controls, device management, also analytics. And then we have this part here, which is Apps and Extentions.
So basically when we started to develop a solution or other users of this framework, as it is open source, started to develop a solution, you get all this basically for free, and then you start with referring to what you're interested in for your specific domain or your specific field of application.
03 Use Case 1: BZ-NEA
And now I move over to the first example, which is based on the architecture I've just shown, which is a project called BZ-NEA with the German railway company.
The Deutsche Bahn is roughly similar, I guess, to China Railway Corporation. This is a government-owned entity which takes care of everything related to trains and infrastructures, passenger transport, freight transport, and all kinds of infrastructure management for train stations, for the rails, everything.

And they started, 2 years ago, a project BZ-NEA, where they want to replace the backup power generators that are currently run by fossil fuels with fuel cells. In many areas in the German train system and their epic switches, the areas are very rural, then there are some backup power generators which, in case of problem with the energy system, will power the switches and ensure that the train system is still working the way it's expected to do. And as we move towards carbon neutrality, the goal is to replace these backup generators with fuel cells.

This is an example of how such a generator looks like. This is just an example in a very rural area, that's a necessary action.

As some of you might know, fuel cells are quite a complex technology compared to regular combustion engines, which we used since more than one hundred years. So we have to manage different kinds of media, and we have to keep taking care of many operation parameters, which makes it very important in this case of a good monitoring.
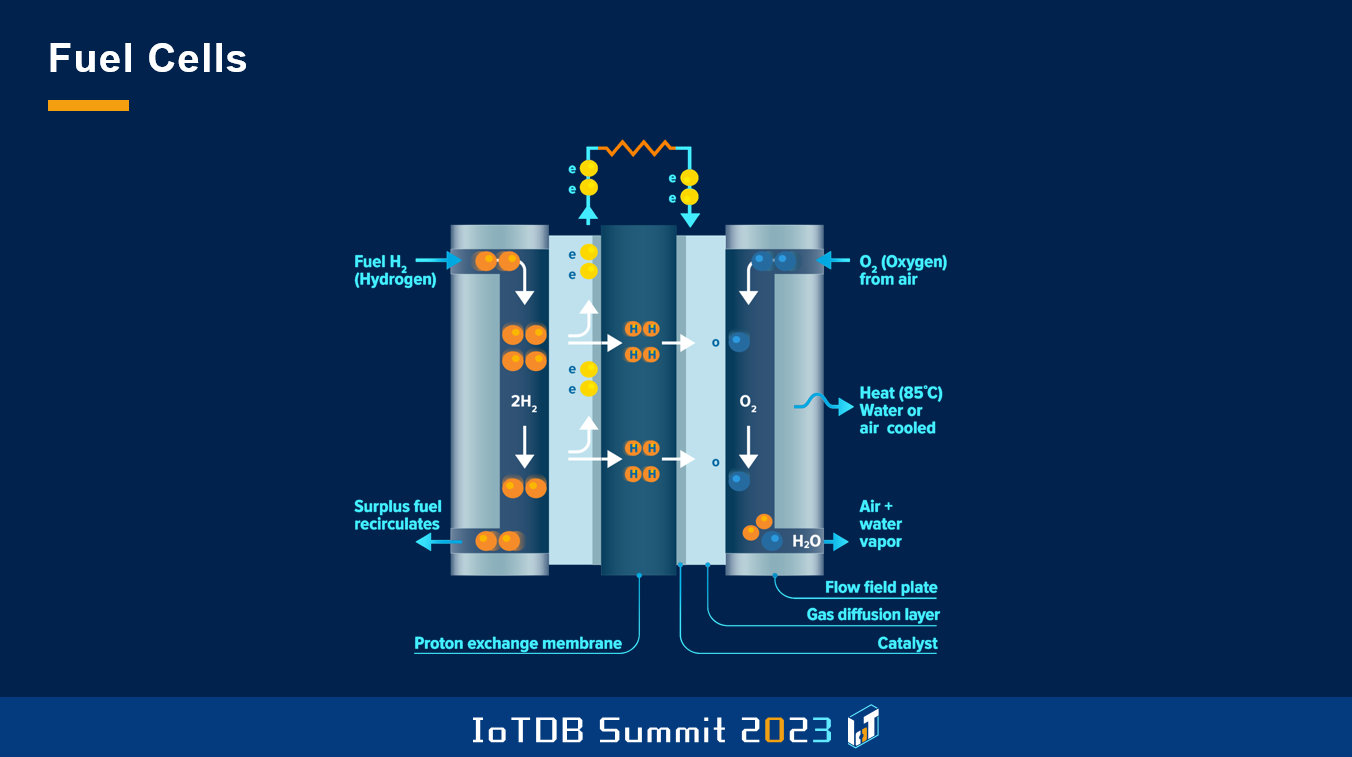
This is an example, and this looks at least way more complex than a regular combustion engine-based backup generator.

And before I go into the details of the solution, there's another thing in Germany. I mean, you might know that in Germany we have many regulations regarding data protection, GDPR, but there's also another kind of regulation which is important here, which is called KRITIS. KRITIS is a term which roughly translated to critical infrastructure, so with very special regulations for all software that is used in critical infrastructure. And the German train system is considered such an area, considered critical infrastructure. So we have special requirements regarding security that we have to make.

This is an example or this is the diagram of how the system looks like. You might notice that it looks quite similar to what I've shown earlier. Besides the PLC4X was replaced by an MQTT broker because in this case, all those stations sent the data by themselves directly from PLCs, from all over Germany. On the right side we have a connector which ingests the data directly into Apache IoTDB, and the major difference that you can see here basically, is there's a connection between Apache IoTDB and the role-based access control module.
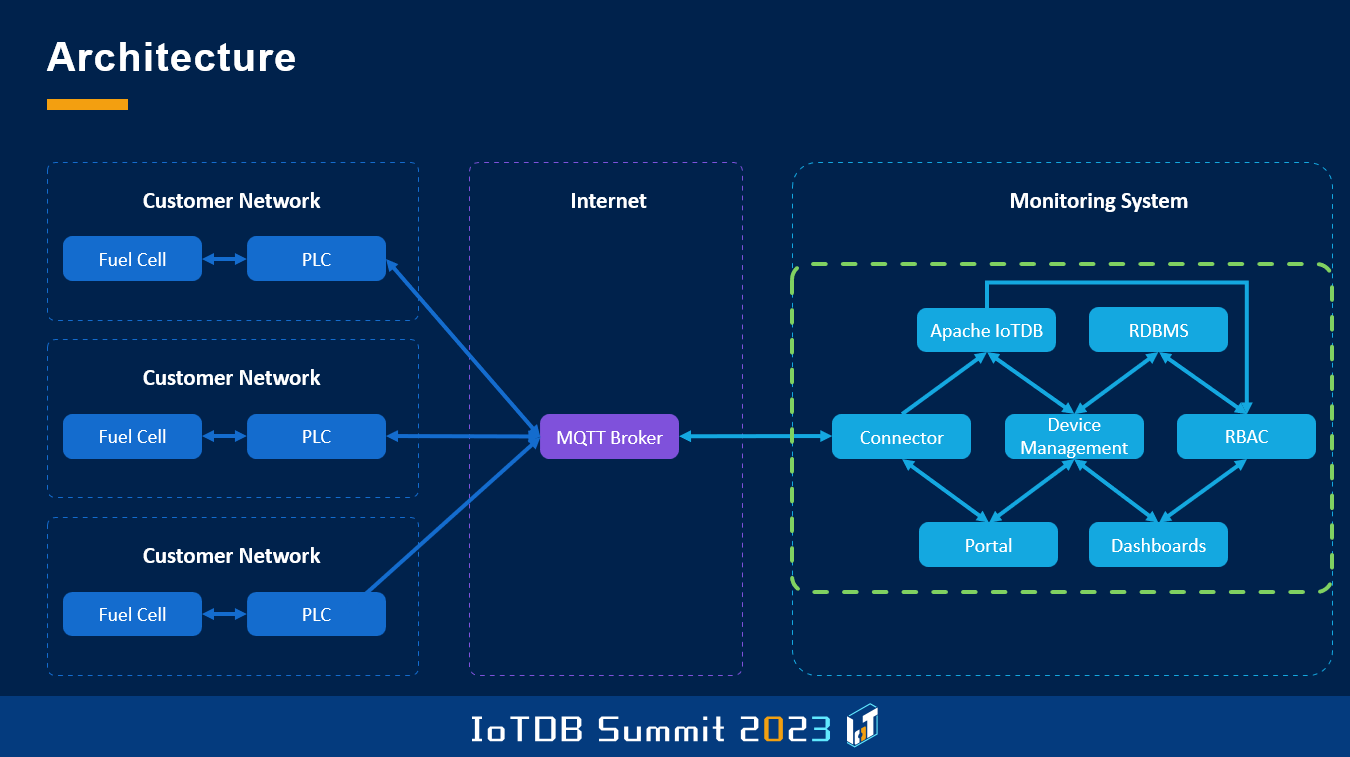
Of course, the front end basically is pretty similar to many applications we have seen today. So we ingest data, and we digest data or display data in several different ways. But due to the special kind of regulations we have, we cannot only use user management in the front end, which then queries the backend, but we have to provide a user management down to the database level basically.
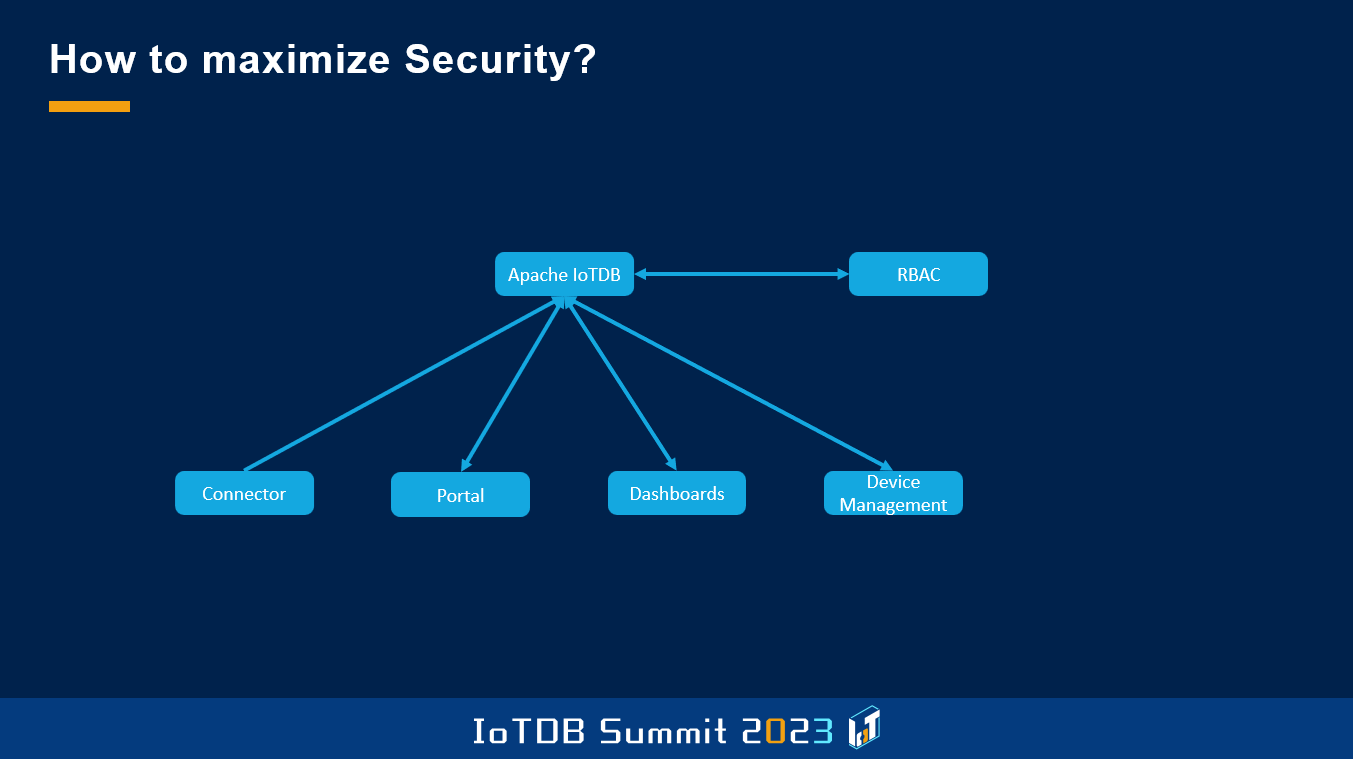
In IoTDB there's a module, I don't know how known or common this is. There's a framework which is called pluggable authorizations, so you can provide your own implementation for the authorization. So whenever an operation is performed in IoTDB, it might be a read or insert operation, then this module is checked to see if the user that sent a request has appropriate permissions for this device or this time series. It defaults to a file-system-based solution, but there's an implementation we did which is called OpenIdTokenAuthorizer.
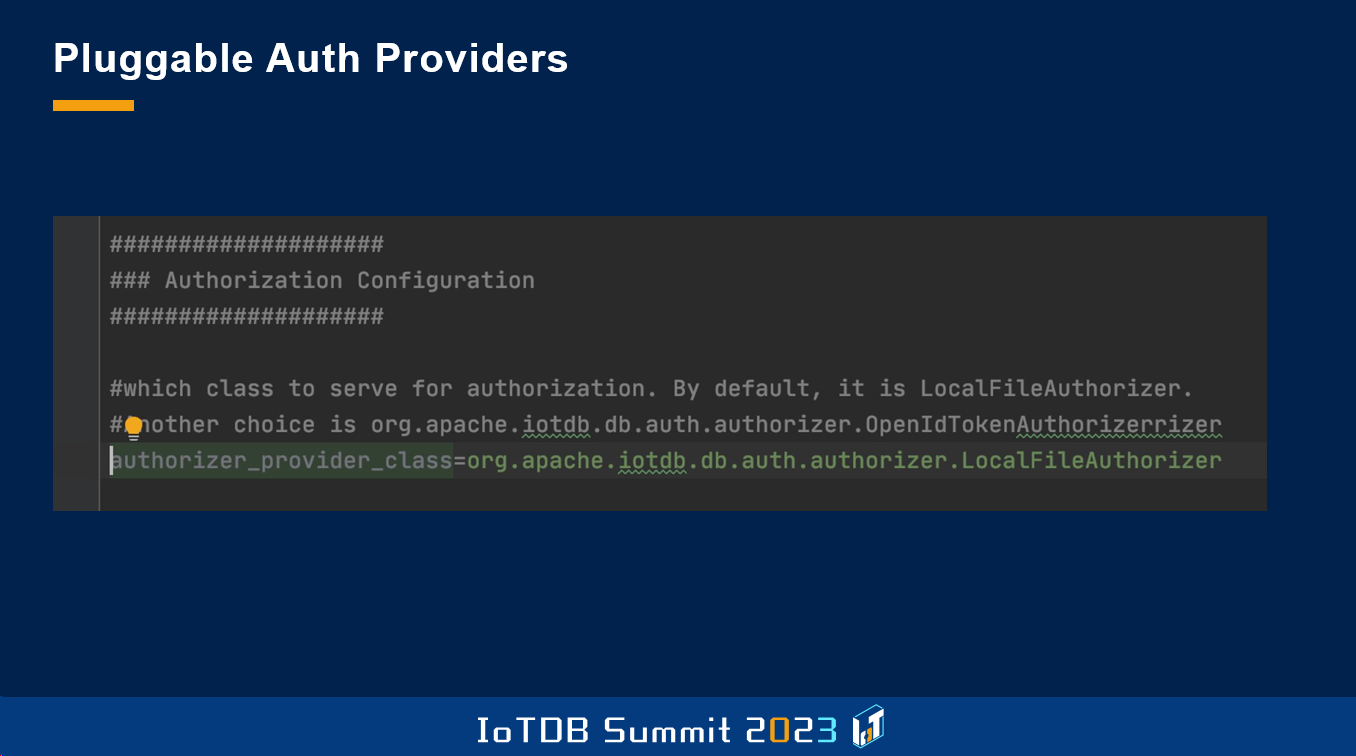
This is an example of implementation, which means that if a request comes from the front end, it has an OpenID Token or JSON Web Token. Then we pass this token also to the database. And then on the database level, you see here, we have some code which takes the token, identifies the user, and then checks the rights for this user to see if the requested user is appropriate or not. This is a nice possibility for us to really enforce these very strict regulations with very little effort that we need to do.

04 Use Case 2: Smart Core
Now I'll go over the second use case I want to present, which is called Smart Core, which takes place in a foundry. I think this use case might be interesting because it's from the German automotive industry, which is usually an industry that many people look at what they do or how they do things.
In this project, it's about one of the foundries where motor blocks are produced, for an 8-cylinder block. In each foundry, usually there's a part of a foundry which is called a core shop. This is the place where so-called sand cores are made, I will go into details a bit later. The parts that are produced as motor blocks are very complex and have very complex inner structures for cooling liquids or cables that go for it and stuff like this. And those parts can only be produced efficiently with the help of sand cores.

This is an example of such sand core, which are placed inside the part during the molding process. Then after the molding process, the sand goes away and then you have the holes in it. This is a standard procedure for everybody who knows low-pressure casting.

This is a very interesting process for us because it's a very complex process. In one single foundry line, we have up to 10 of those machines, which are called core shooting machines, which basically produce sand cores, and those machines have over 200 sensors.
The processes that happen in this kind of machines during the shooting process are physical and chemical processes, like chemical reactions but also high physical influence, like temperature and pressure. And those process happens in several timescales, from microseconds when the sand is shot in the toolbox, up to several seconds or even several hours when the sand is treated afterwards and in a cooling process.
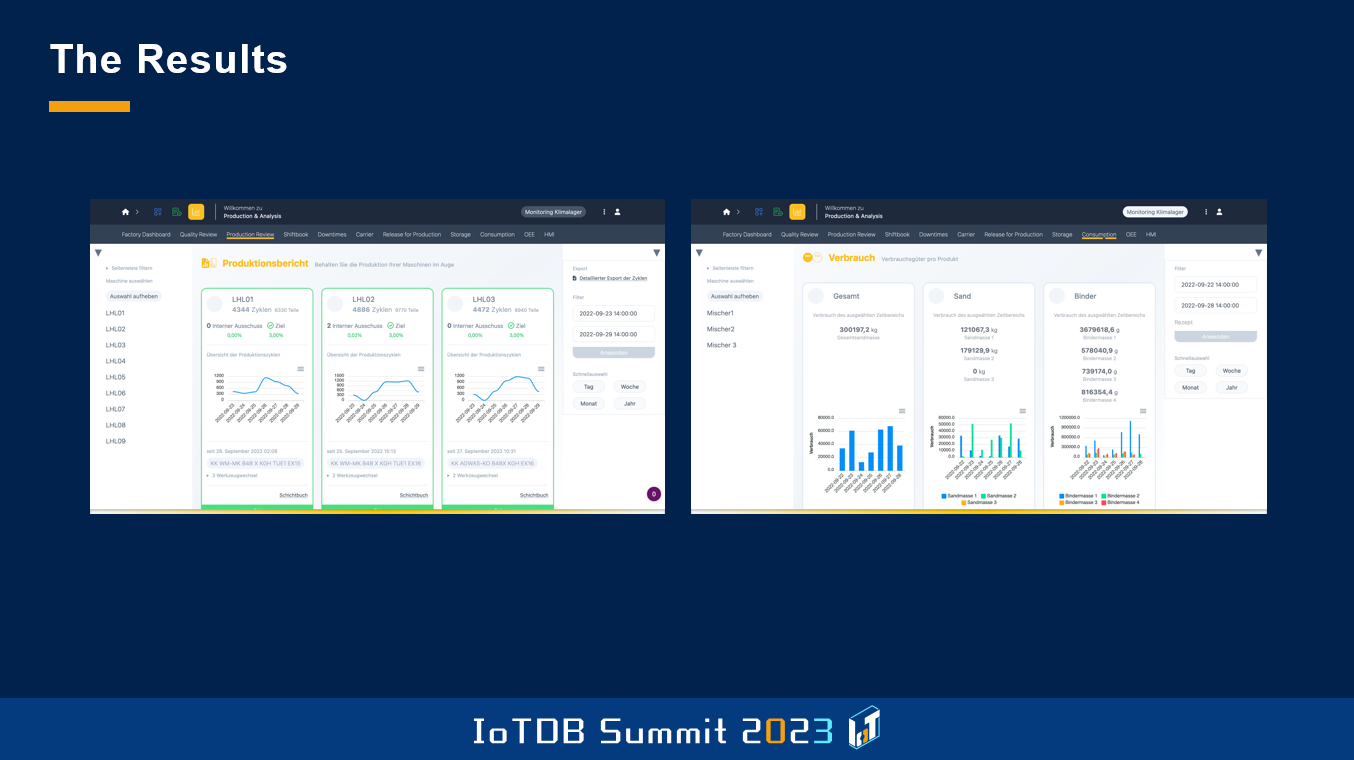
What we do here in this process is a central aggregation of all those time series, and then we use those raw sensor values to do aggregations, to provide metrics which help the people to run the factory more efficiently.

The architecture is, this is a picture you've seen before, the architecture is again based on the open MAchine platform. You have the PLC server, and we have an analytics framework which takes all the data we get from the PLCs. That's the necessary calculations to provide the kind of metrics that the customers need. It's a pretty standard IoTDB application, I would say.
Perhaps the most interesting part is happening in this area of the graph. Currently, we use Apache Flink as a stream processing framework, which is, I think, a pretty common pattern. But with the recent developments in Apache IoTDB, we are trying to migrate to an approach which is based on user-defined functions, continuous queries, and triggers, which would then push all analytics on the time series inside the database, and we could eliminate one part of our application.
This is a picture I've shown you before. Basically, this is the result of the analytics we do. Based on the information we get from the sensors, from the PLCs, we calculate metrics like productivity, quality-related metrics. We also generate several reports about the manufacturing process which I use for quality inspection, quality control.
In another aspect, which is quite important in the automotive industries, is pretty much all about production costs. Production costs is a crucial part in efficient manufacturing of cars, so they do pretty extensive calculations. And during this car shooting processor are several media that you use. You use water, you use compressed air, use energy, use sand, and use some chemicals, additives that they are called. Up to now, they just did global calculation of how much material they used over a week, how much parts they produced, and this is what they've done.
Now, we have the possibility to drill down those values basically on every single car shooting process. One part or one type of core is more likely to fail, more likely to break, because it's more brittle, or perhaps more complex. Then, of course, it will consume way more sand, because some of those cars have to be thrown away. This is a module which is quite important because we on a daily basis generate all those reports to say which order, which part, which sand core consumed how much energy, media, and so on, which is then used for pretty strict calculation about the costs of the manufacturing process.
Another aspect we do here is from the parameters we read from the machine, we know things like which toolboxes are equipped on the machine. We know the quality of the sand cores, we know the exact treatment of the sand cores, so we can use the system also to control processes that happened later. For example, we automatically generate orders for SAP, for the ERP system, and also for the warehouse without the need to have any other integration layer, just out of the data, because we know what kind of cores, which quality they are, so we can automatically tell our warehouse where to store them and then where to provide them later on.
05 Summary
This brings me to my summary. Sadly, I would say the adoption of the digitalization in Germany is still slow, compared to what I see in other countries, and what I've seen today, in the last day here in China. Due to various reasons that I've talked about, perhaps also mentality thing, but it really is also related to the fact that our industry has a long tradition, which is a good thing, but on the other hand this means that our assets are sometimes a bit older, which makes it harder to integrate them into these processes.
And another thing is, as I've told you, that the German companies, even the automotive area, are not yet at the point where they have their own teams, which do the data analytics by themselves, but are more focused on very classical plant management, which imposes the burden of us. If we want to introduce them to IoTDB, then we cannot only provide them a database, say "Hey, this is a good database. You can store your data in it", but we have to do the full stack in the sense that we have to come up with a complete solution from data collection up to evaluation of the metrics.
And as I've also said, the applications are not too data-heavy because we cannot collect all data from all machines, especially not from old machines. On the other hand, the granularity of data we need for these kinds of analytics is not that high, so we're certainly not pushing IoTDB to its limits with these kinds of applications.
And as I've also said, the integration is very, very important. So we also created those frameworks to help other companies build their own solution based on IoTDB, without having the same boilerplate to be written over and over again.
And another aspect which I really want to emphasize because it's important for us is, there is the possibility to extend IoTDB in a way which makes it feasible for basically every application here, in this case, for a critical infrastructure application in Germany. And another factor which helps us in this case is the nature that IoTDB is open source, of course.
So basically this sums up my talk. Thank you!

Author
| Dr. Julian Feinauer CEO of pragmatic industries GmbH Mathematician and Open Source Evangelist | |



