

It gives me great pleasure to be here. This is the first time I'm attending an IoTDB event.
My involvement goes a while ago when Xiangdong was doing his PhD thesis work, which is the starting point for this IoTDB. There was this event in 2014, previewed IoTDB in Hangzhou. There was a big data summit that was organized at Tsinghua, and I was given the responsibility to invite a bunch of people from outside China. So this picture includes some of the people that you're gonna hear from, and Jianmin Wang was the PhD adviser of Xiangdong when I met them for the first time. I've been coming to Tsinghua since 2004, but 2014 is when I got engaged with the School of Software. Back to that point, I used to be visiting D.C. And here you see in 2016 again I came, and that's when I took this individual picture with Xiangdong. I could only find the group picture before that, but you're gonna hear more things from some of the people in that group photo.
And I also want to acknowledge that it's an important achievement. As far as I know, this project, when it became an Apache Incubation Project, it was the first one submitted by a Chinese university that then graduated to the Top-Level Project status, and so that's a big accomplishment. Congratulations in particular to Xiangdong and all the others who have since then contributed to this, not just from China, but also from Germany and other places. So you all should treat this as a big deal accomplishment by the Chinese community which initiated this project.

In terms of the rest of the presentation, I'll go into various topics related to databases in general, and also a little bit on IoT and IoT databases. So you know there have been various developments across the last many years that you all will be aware of, both in the hardware space and in the software space. That includes AI, cloud emergence, and hybrid cloud as well as full-blown public cloud. So there is still scope for on-prem databases and usage of data in a very restricted way rather than everything being moved to the public cloud. Also, issues with LLMs that you will keep hearing about and their application to databases and such.
And then there are public policies that are emerging. Some of them are already lost, others are about to become lost, which will have implications on how various companies operate, especially in the West, thanks to HIPAA regulation, GDPR, and new acts that are being proposed to regulate AI, for instance. So all of these things will definitely need to be taken into account in the design of systems.

So I caught some information from different analysts that are there, Gartner, IDC, and people like that. And this picture shows the emerging technologies and trends as Gartner has predicted relative to this year going forward, and they give you various pieces of information. You'll see certain things that are of relevance to the topic of this conference, which has to do with, for instance, edge computer vision and edge AI, and you also have hyperscale edge computing. I let you look at these sorts of charts, which have too much detail, at your leisure, after the conference, when you gain access to the slides.
But the important thing is to know about what these analyses are saying because users of database systems get influenced a great deal by what these guys have to say. In a sense, the Chinese companies have to make their publicity and all that become better to inform these analysts and such people that have influence, at least outside of China in a big way. And if the companies here want to expand their markets to outside of China, they better be paying attention, and this includes technical people. Even programmer-type people should be aware of these things. I've been a technical person all my life, but I still had to pay attention to these sorts of things. I never took up management in IBM. The thirty-eight and a half years that I worked at IBM research, in the birthplace of relational database, in the place from which SQL came, which is the IBM research lab in San Jose, California.

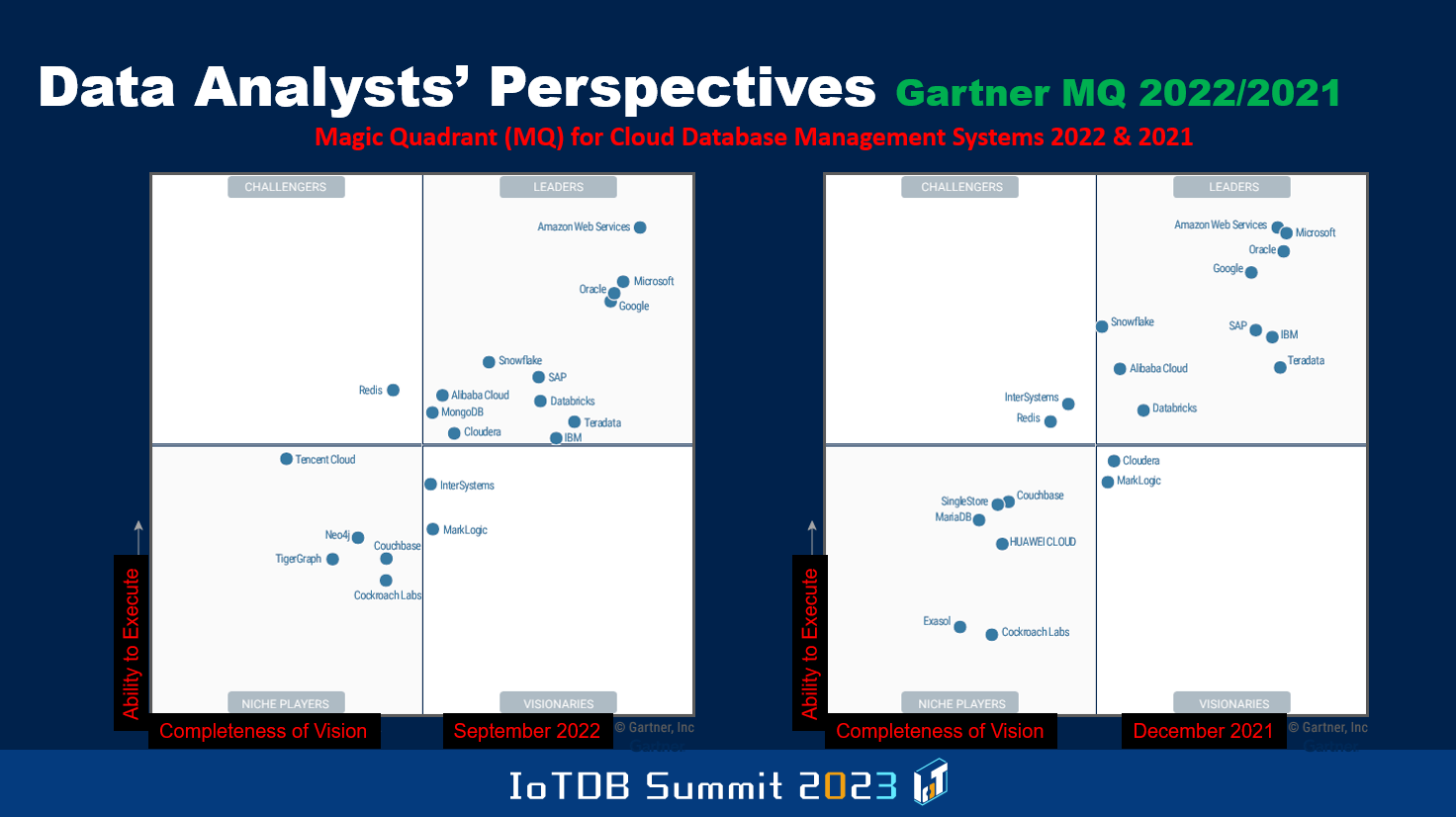
So in terms of positioning different vendors out there, Gartner produces every so often what they call a magic quadrant, where the x-axis has to do with completeness of vision, narrow or expanded, particular company vision is, with respect to an area. What you are seeing here relates to cloud database management systems. It's 2022 as well as 2021, positioning of different vendors. The y-axis has to do with the ability to execute. Somebody might have good vision, but they are unable to realize the vision in terms of implementation and producing products that are reliable and so on.
The ideal position you want to be in is the top right corner and as you can see here, even between December 2021 and September 2022, some vendor positions changed because they keep producing these kinds of graphs every so often, Gartner guys. And you'll also see a few Chinese companies showing up in this, for instance, you see Alibaba Cloud over there, and you also see Huawei Cloud here. It's important to be cognizant of these sorts of things.
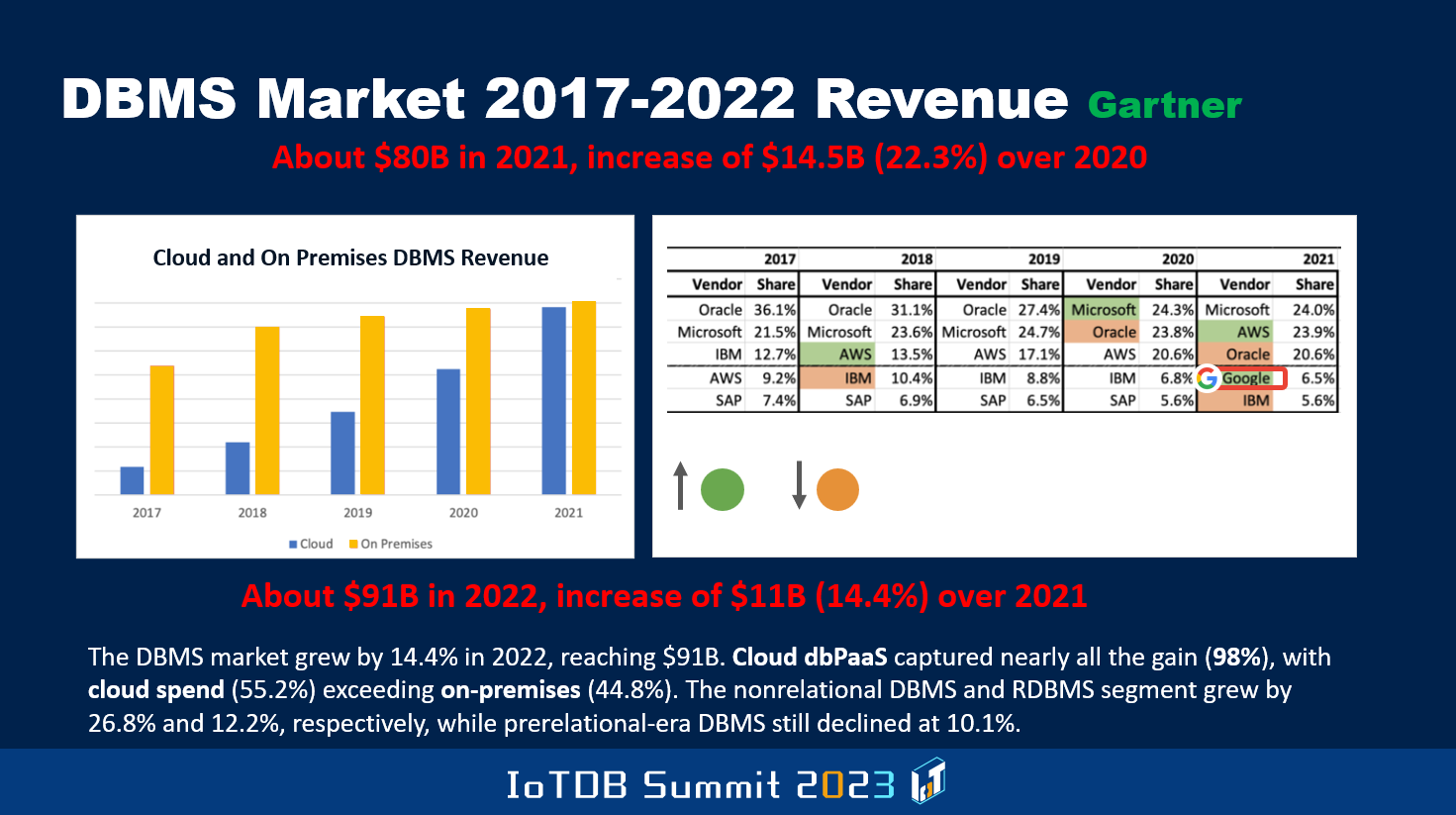
This one, Gartner has shown the estimates they have of how much money was made from 2017 to 2022 in the overall database space, and then they split it up between on-prem versus cloud. And as you can see over time, the proportion of the overall revenue that's attributable to cloud has been increasing. The overall market is increasing, but the proportion that cloud revenue has contributed is becoming more and more, and as you'll see at the bottom, in 2022, it actually exceeded. It was 55.2% of the revenue in 2022 was attributable to cloud database revenue compared to on-prem, but you do see that in 2022, the market didn't grow as much as it grew compared to 2020 to 2021. The overall market they estimated to be $91B last year. Some of this is highly subjective, and so between Gartner and IDC, you'll notice that there are differences in these numbers.
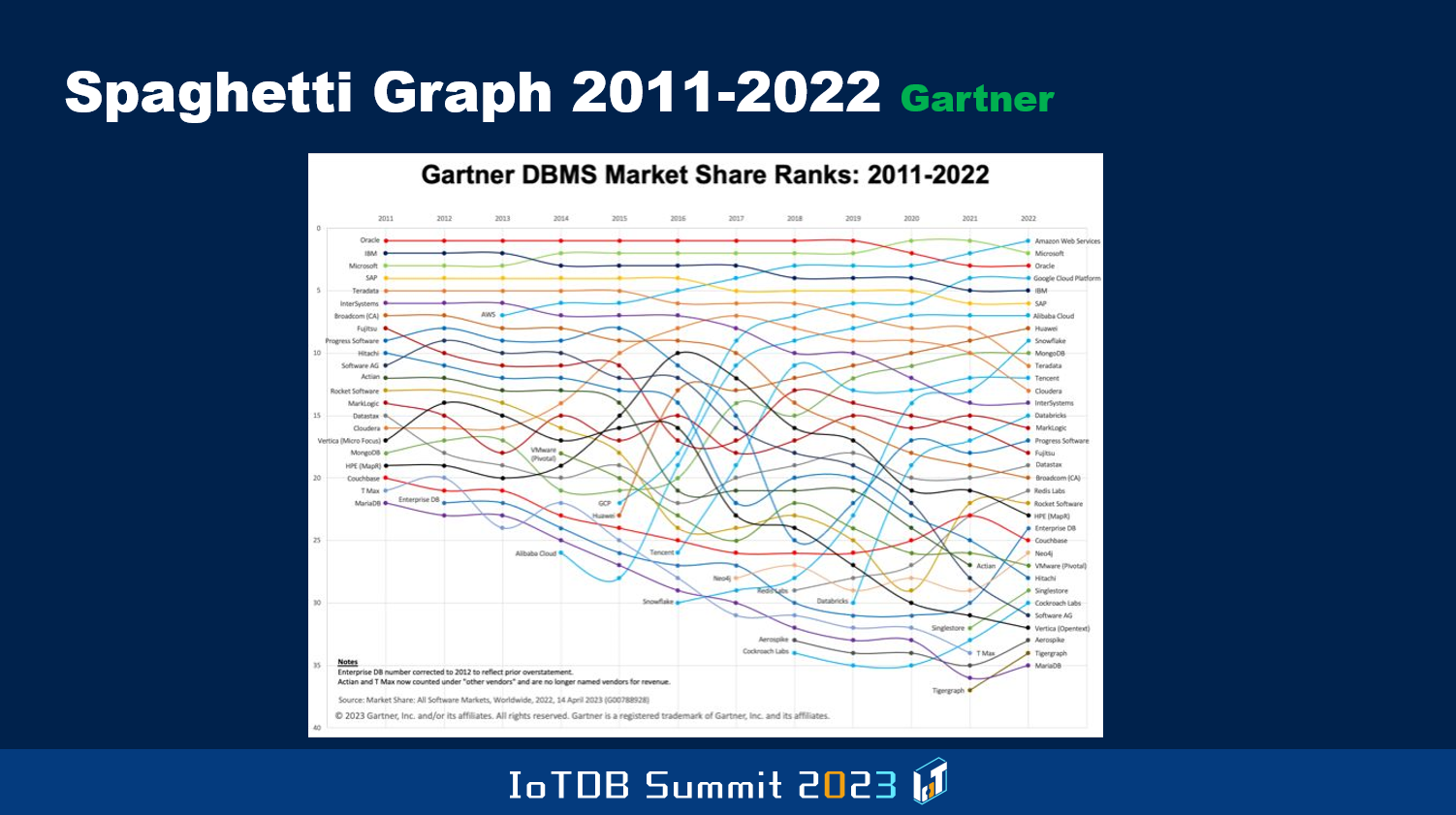
This shows you from 2011 to 2022, the positioning of the different vendors. In the previous chart, I don't know if you saw, there's the positioning of the top 5 vendors from 2017 to 2021, and Oracle used to be number one in 2017. By the time you go to 2021, it's Microsoft that becomes number one. And later in the next chart, you will see that Microsoft got replaced by AWS. The list of players by 2011, Oracle, IBM, Microsoft, SAP, Teradata were the top five. Then if you go to 2022, it's Amazon, Microsoft, Oracle, Google, and then IBM, and then SAP.
This is called the spaghetti chart because it looks like spaghetti over time, how some new players came that were not there in 2011, and how they gradually improved. Or some players like even IBM went down. And again, these kinds of numbers are not like algorithmically produced, so between different vendors, you'll see differences.
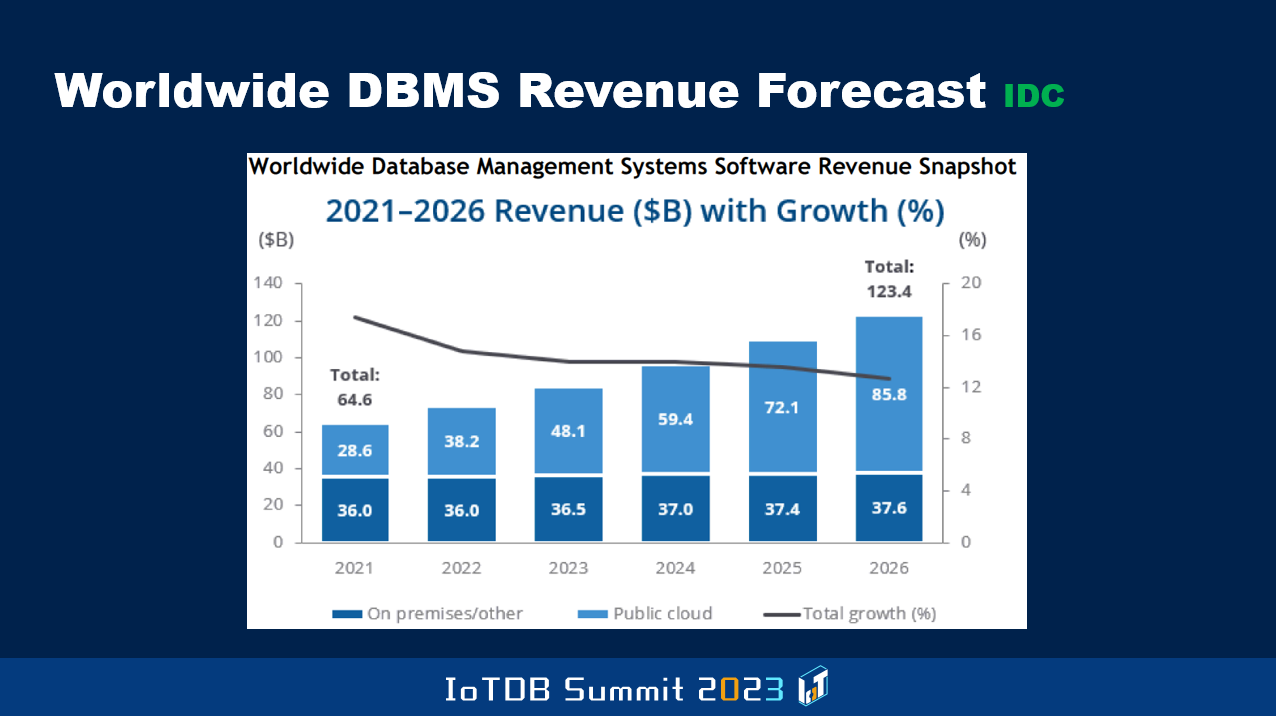
For instance, this is a chart that shows what the IDC guys estimated to be the 2021 overall market size, and that's 64.6. Whereas Gartner had estimated that to be $80B, so it's a huge difference in numbers. Because of the subjectivity involved, these things don't always sync up between the different analysts. But they are estimating that by 2026, IDC guys, that the market will become $123B, and that they are also saying that growth will come down a bit, but still there will be growth. As the Gartner number showed, even here, the percentage attributable to the cloud part will keep increasing so much so that in 2026, they estimate that it will be $85B of cloud revenue and only $37B of on-prem revenue.
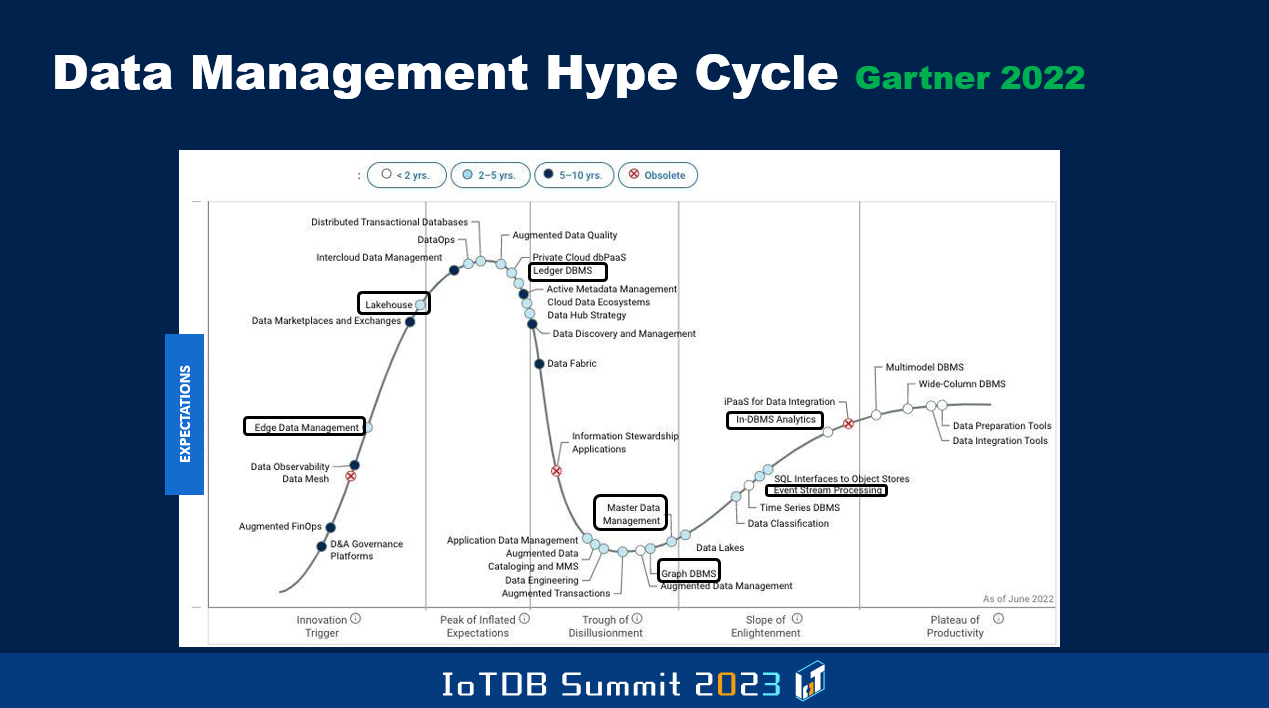
And Gartner regularly produces, what they call the Hype graph, where on different topics they do this, and this particular one is the data management Hype Cycle, and this was produced in June 2022, more than a year ago. Here they talk about how new ideas come in and gradually become hot and there'll be lots of expectations generated by the Hype. But then they don't deliver the goods, and so there is the trough of disillusionment where this curve goes to the bottom. And then gradually some of the unfulfilled promises will, at least to some extent, get fulfilled, and that's when there'll be a plateau of stability. But certain topics disappear before they even reach that mature stage, and others take longer time to reach the maturity and so on, so it's also good to know about some of these sorts of things.
And I've highlighted a few things. So in the context of IoT, edge data management is still in this climbing phase, right? Whereas in-DBMS analytics and event stream processing, they are in the last stages of becoming mature and then becoming stable. That means that there won't be too much innovation within that particular kind of topic. So for instance, wide-column DBMSs are in that more mature state, things like that.
In particular, within the subspace of analytics and BI, they've produced a graph, rather than the previous one, which was the overall database area. And here you see even more detailed way of looking at the space with respect to analytics and BI. So here you will also notice things like event stream processing, then edge analytics that's coming down from the height of hype, to getting into the mode where people might become disappointed because you're not fulfilling all the expectations you set up when you hyped a lot about it and so on. And predictive analytics is in this more stable state towards the end.
And there are time periods that are associated with it. For certain topics, they expect maturity to happen in a short time. For some others, they expect maturity to happen after a longer time and so on. So there is a legend at the bottom, because the color coding of the dots in that curve are also different. Not all of them have the same color coding.

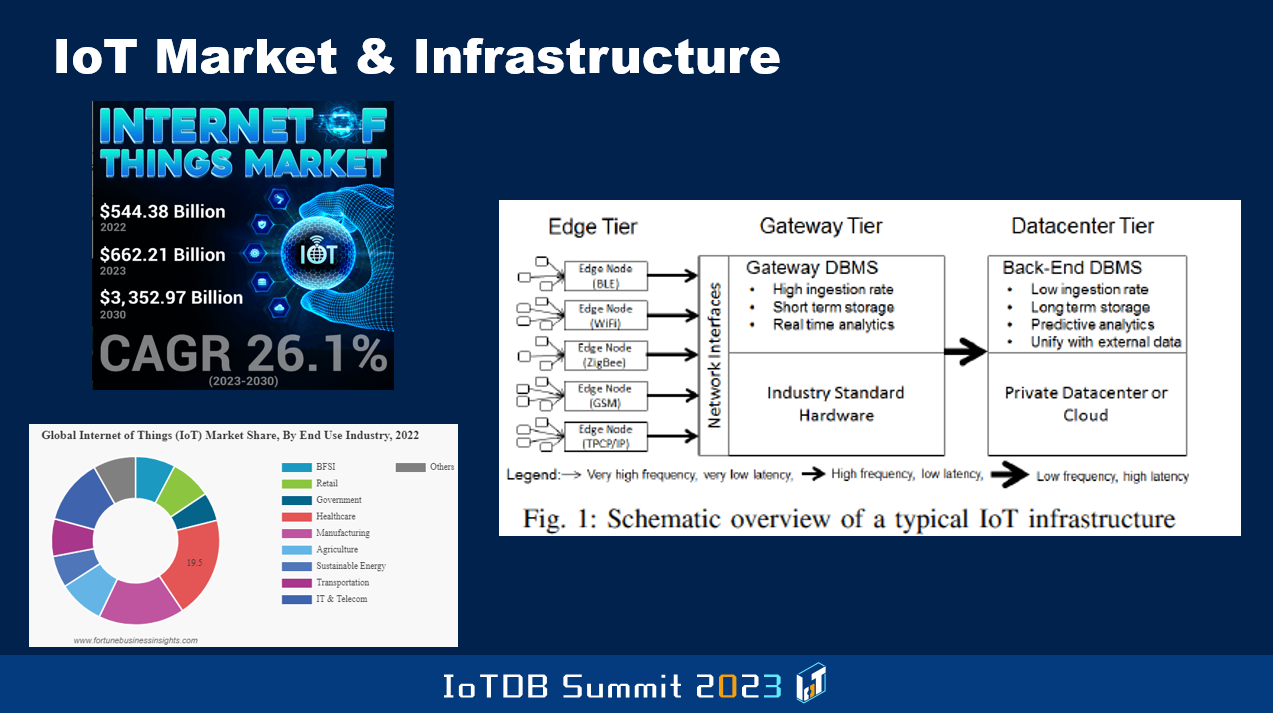
Now let's look at the IoT market specifically. So some entity called Fortune Business Insights, they produce these graphs. And so they're estimating the Internet of Things market last year to have been, believe it or not, half a trillion USD, $544B. And they expect by 2030, that size to be $3.3T. That's a lot of money to be made. Of course, this is the overall IoT market. A subset of which will be the IoT database market and hopefully you know, you guys, Timecho company will reap a whole bunch of that money as revenue.
And as part of this, they also look at this circle with different colors. What are all the different use cases that they have surveyed and found out are the ones that are in the IoT space. So those are things like government, healthcare, manufacturing, agriculture. The previous speakers mentioned some of these things, right? And later on today you're gonna hear from different users of Apache IoTDB who are in some of these spaces, transportation, sustainable energy, and so on.
And then you see, on the right figure, which comes from a benchmark that was developed and published first in 2017. It's the Transaction Processing Performance Council's IoT Benchmark. It's called TPCx-IoT and they talk about the edge tier, which then connects to the gateway tier, and then you have a backend data center which is for longer-term storage of the data. The goal is to make the devices, the Internet of Things devices be able to communicate effectively and in a proper way to the gateway tier. And that's where stuff like IoTDB will be running. And the client side that runs on the devices might not be as powerful and so on, because of the restrictions of the resources that are available. I'm sure in the later talks, you're gonna hear more about all this.
And what's the focus of this Benchmark? They have chosen to look at the manufacturing arena, power generation, and transmission kind of use case. And so you see some pictures here that represent that use case, that's the focus of this benchmark.
And just yesterday I heard the presentation by a PhD student in the School of Software, who is now evaluating with respect to this benchmark, how well IoTDB is performing. And he plans to improve because there are already some published numbers that are public, that other vendors, I've forgotten the name of the other products that are out there. One of them I was not even aware of until a few days ago. The other one I'm more aware of, Cloudera and so on. They've published numbers, and so that's now the target for the improvements to be made in IoTDB.
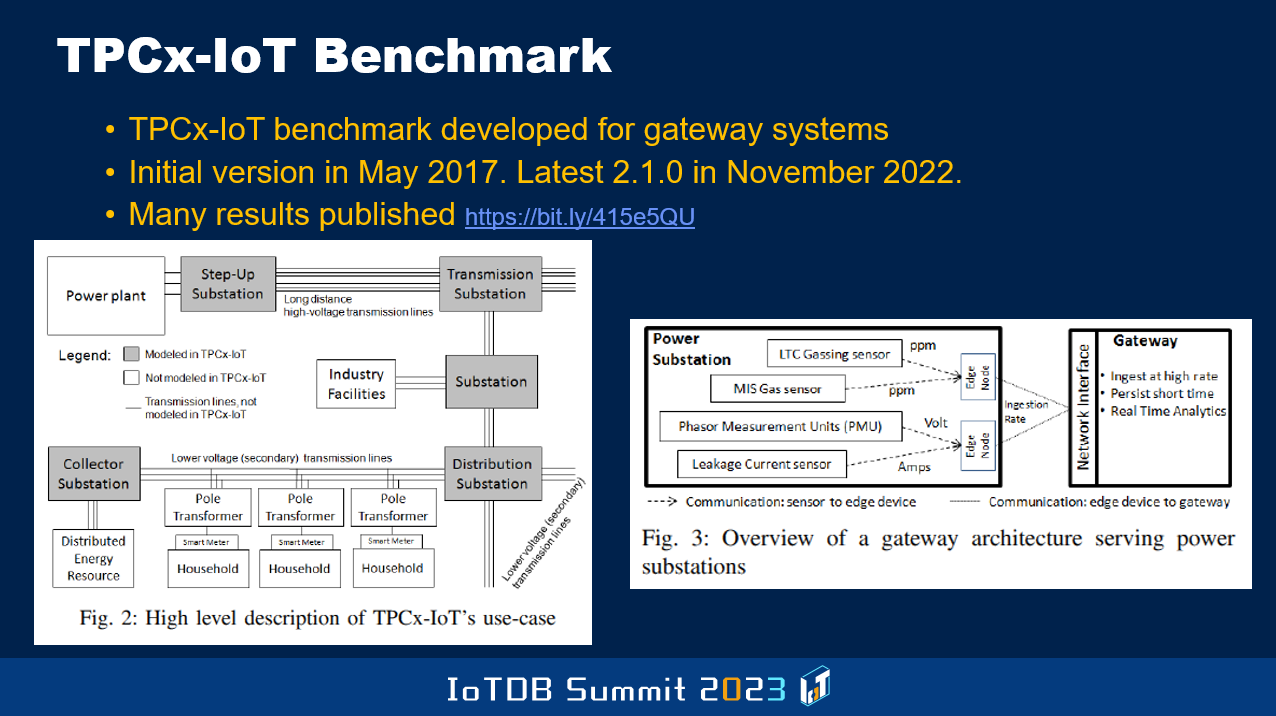
And it turns out this Benchmark was a result of, you know leveraging some earlier benchmark that Yahoo guys developed, called YCSB, Yahoo Client Server Benchmark. And so this shows you what certain details about this Benchmark, what they are measuring. Like a typical TPCx Benchmark, it not only looks at transaction rate, but it also looks at price performance, how many dollars do you need to spend to get a certain rate of transaction throughput.
What you'll notice is that this whole space is not entirely new. Even though products are being labeled as IoT databases now, the whole space has been around for a long time in the form of stream processing, event processing systems, and such. They didn't necessarily do that in the context of the kinds of real-life use cases that a few will be currently focused on, but they've been done more in research prototypes and things like that.
And even triggers and such that were introduced decades ago in the SQL language had to do with reacting to real-time events. There was even a sub-discipline within the database area called real-time databases that we worked on thirty years ago, forty years ago. But now something like IoTDB is bringing together these different things that happened in a sort-of separate ways and never got put together in a serious way, into a single system, even a research system. That's the difference. And SQL language also has evolved over time with the temporal SQL constructs and such, and also window functions were introduced in SQL quite a while ago. These are the sorts of things time series support, have been around for a while, but in terms of actually leveraging them in industrial context and such. It's industry 4.0 and such things also are the motivators behind what's going on.

Here is some list of reasons why one would want to do analytics at the edge. Sometimes has to do with the sovereignty issues. Some countries will say the information about their people or products, or whatever machinery and such, cannot be shipped to data centers outside of the physical boundaries of that country. So the cloud that you are using might be such that, it doesn't have the data center inside your country. But by doing the processing at the edge within your country, and only sending aggregate information that hides detailed information from being sent, you will be able to sometimes satisfy these sovereignty requirements. Regulations, as well as even GDPR, in a more general sense, force some of these sorts of things to be done.
And also of course, the connectivity might not be good between the edge device and the data storage places and such. So for such reasons also, you might want to do more of the processing. But it's a tradeoff because the edge device, if it doesn't have enough power and compute capabilities and such, you might not be able to do very sophisticated things. But the current thinking, and I think MingSheng probably is gonna talk about, doing even machine learning at the edge and things like that.
So there are various things that you can think about in the space. Of course, one of the important ones is if the edge device needs to get some result back, if the result can be produced in the edge itself, or at least in a faster fashion by cashing a lot of information there, that can also improve the response time.

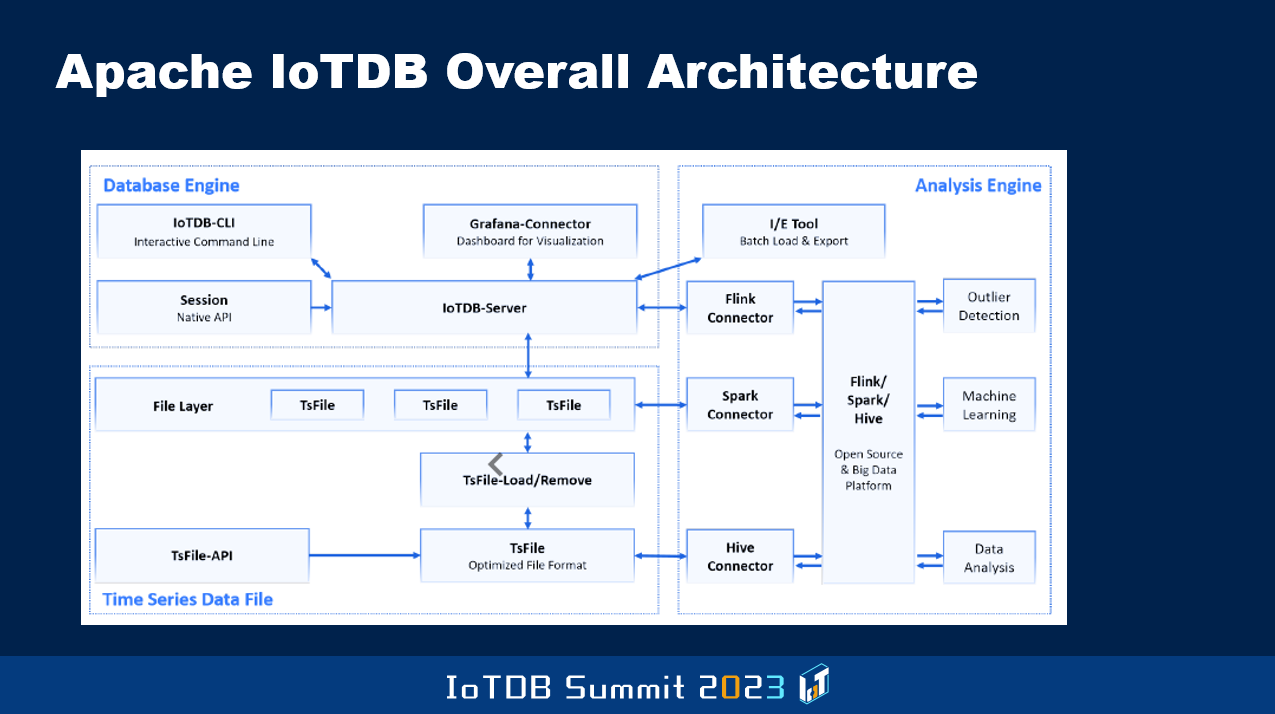
So this is a picture that probably will be shown by somebody else. That just shows you how you have the database engine, and then the analysis engine in Apache IoTDB. It's the overall architecture. They came up with the new file format called the TsFile, in which they stored the data efficiently with compression and such things. So I let others give you more of the detailed descriptions of the IoTDB server, the IoTDB client, and various other things that are there, and how they are evolving these things, how the data is loaded efficiently. Even yesterday, I heard a presentation on some of this.
But in general, beyond all this specific to IoT kind of environment, there's a great deal of momentum behind graph databases now. I've listed a bunch of things that are going on. Traditional graph-oriented query languages, as well as additions to SQL with graph-oriented primitives. So there's always been this tradeoff between native object-oriented database systems versus object-relational database systems. In a similar way, even in the graph arena, last year SIGMOD had a paper where they talked about SQL/PGQ and GQL. This all has to do with navigational versus declarative way of doing things and so on. Even Alibaba has got something called GraphScope.

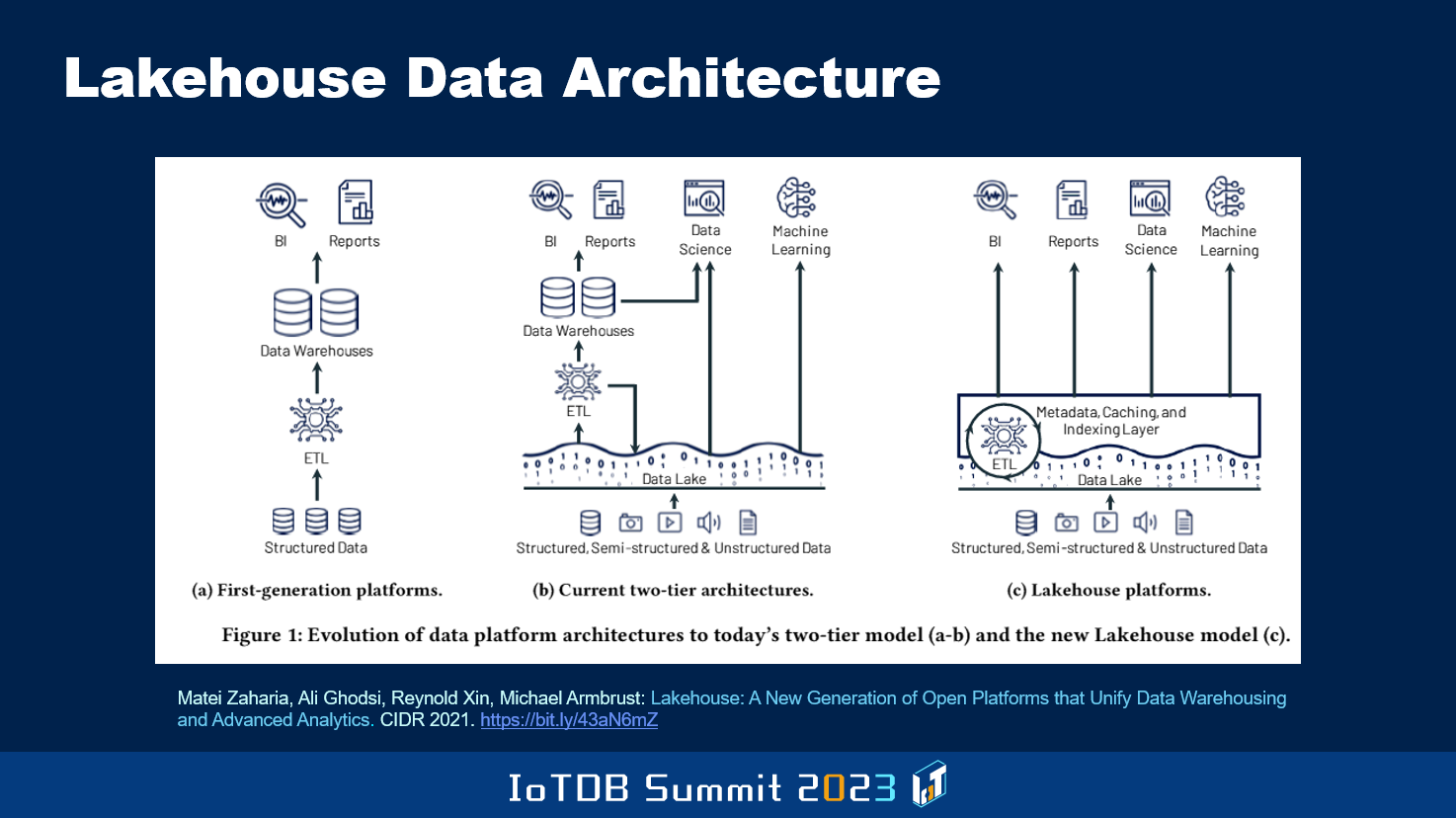
The area that's focus these days is this whole business of the event from structured data to unstructured and semi-structured with data lakes and such. But then they found that for the data lake data to be able to be processed in the traditional way, in which structured data was processed, you have to extract our unstructured data out of the data lake, and then have to use things like what you see up here, BI, Reports and so on, and machine learning included. So the latest thinking that the guys behind Spark have come up with, this is Databricks, is the notion of lakehouse where they are trying to push into the data lake itself some of the stuff that previously had to be accomplished by moving the data to more structured DBMS kind of environment.
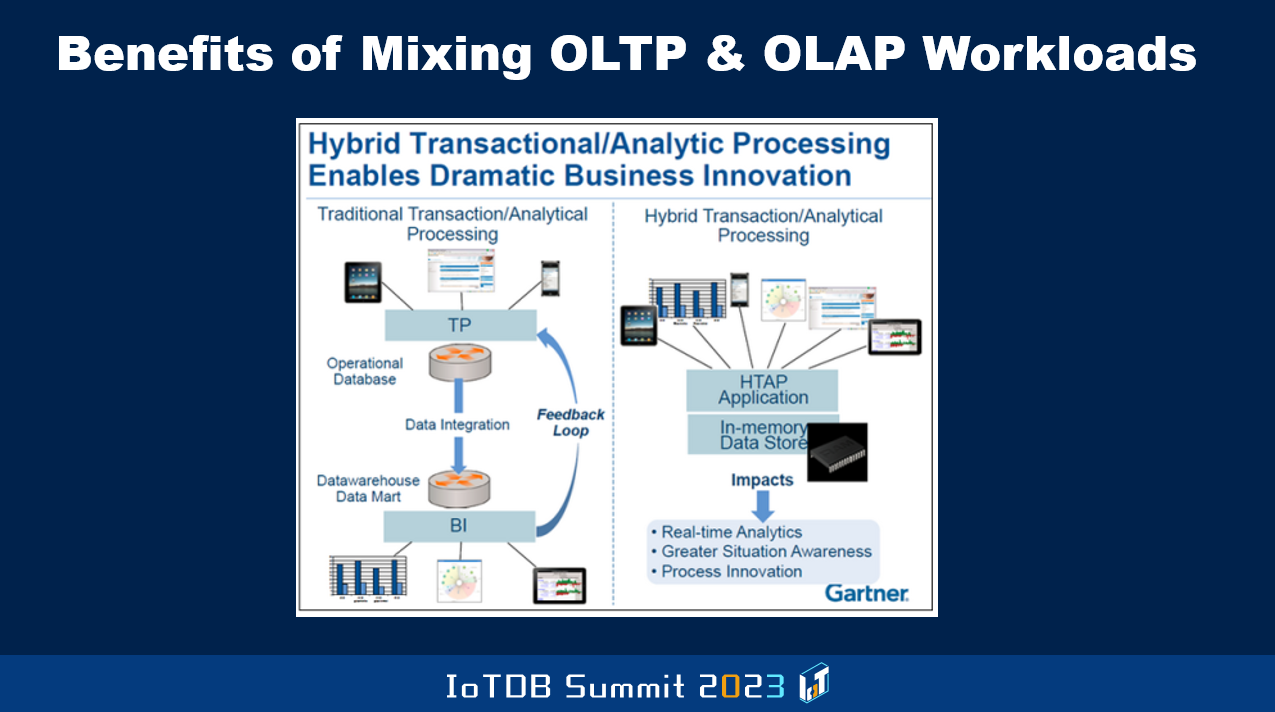
Also, the other thing that's happened is that traditionally, we used to talk about OLTP system being separate from the warehouse system. And periodically data from the OLTP, as new data comes in or existing data gets modified will get moved to the warehouse. But this meant that if the analytics are done on the warehouse, it's based on older data than the latest data that's in the OLTP system. It's all a function of how quickly you move the data, and there's a cost associated with it.
So the modern thinking is what's called the hybrid transactional and analytic processing system, where within the same single database you do OLTP transactions as well as these long-running kind of analysis type, OLAP kind of workloads. This introduces lots of complications for the guys like me, who are algorithms people that are sitting inside the balls of the DBMS, trying to figure out how to do concurrency-controlled recovery, storage management, indexing, and so on.
And so OLTP is best handled with the data stored in row format, but OLAP is handled best when the data is in columnar format. Now, if you're going to combine these workloads in the same system, what the heck do you do? But some of the modern application requirements are demanding that the two be combined, and so that's why this is an area that's full of innovation and scope for PhD thesises and papers to be written and new systems to be built. And new kinds of data formats and transforming from row version to columnar version periodically in a batched way. And such are the kinds of ideas that have been developed in a number of products that I don't have the time to go through.
And I have now a few more things here. The rest of the charts talk about general trends as well as specific trends within the database area. So this general trend has to do with the evolution of on-prem to cloud. There are some databases that have undergone this kind of transformation in particular, for instance, how PostgreSQL and MySQL got evolved by Amazon through the Aurora project, and Google also has done something like that called AlloyDB, and also the Microsoft guys have evolved SQL Server in this fashion.
But then there are new database systems that have come out, that are born in the cloud kind of database systems, natively supporting the cloud. And then there are various companies that have become very active, in particular the Chinese companies. Relative to the past, are now publishing like crazy. Not just in the industry tracks of important conferences, but even in the research tracks. And so I keep telling the people in Silicon Valley where I've lived for four decades, "Guys, pay attention to what's happening elsewhere. Don't keep looking at your neighbors and thinking whatever is happening in Silicon Valley is all that matters. Before you know it, these other guys might take all the area."
And so in that sense, it's a good thing for competition to be there, and this kind of technology development to happen. And I'm glad many of these things are happening, where even more and more academics like Jianmin and his students are getting involved in the startups in this country right? Which wasn't the case for the longest time. And this is true even for Europe and America and so on.

There are more trends about storage, how the notion of disaggregated storage has become very popular in the cloud environment, where the storage layer is separate from the compute layer dynamically, the compute layer nodes can be assigned or de-assigned based on workloads and so on. So this put a monkey wrench into the traditional database architecture that I and others worked on for decades. And this is where I was earlier describing how some companies, like Microsoft and Google and Amazon have done some very different kind of things, and I don't have the time to go through the details.

And of course, there are also things happening in ML space. Leveraging ML within the DBMS itself to make its various things happen more or less automatically, rather than human DBAs and such having to get involved.

Analytics is another area I mentioned already. Lakehouse, there's a new query engine that Databricks guys have developed, called Photon, to deal with the lakehouse architecture that I mentioned before.

And then in the distributed database area, also there's a lot of open source activities. This gentleman spoke about the importance of open source and all that earlier, and so FoundationDB is something that Apple acquired and then open-sourced that system. And then there are also companies like CockroachDB and so on.

Then cloud DBMS. As I said, there are many of them. Some of them born in the cloud, some of them transform versions of the on-prem DBMSes. There are more details here, but I have to stop now, so I'll just flip through the slides.

There is the OLTP kind of databases.

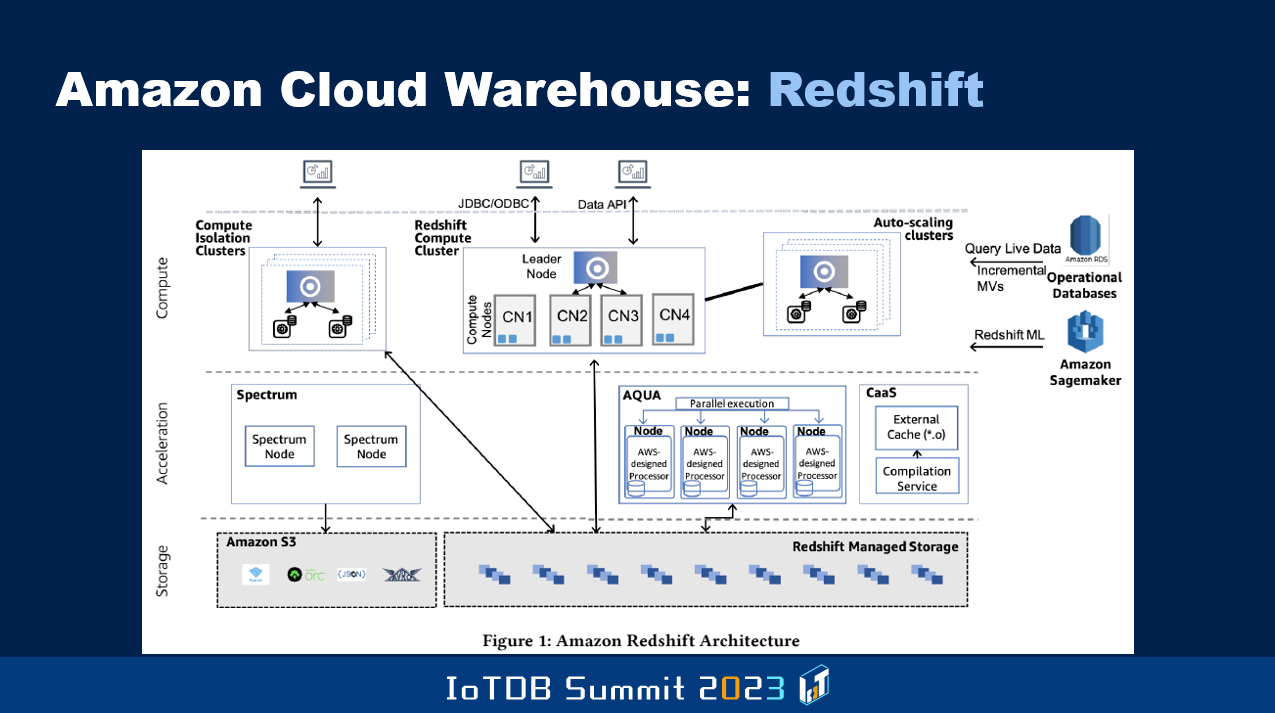
And then there is warehouse of Amazon, Redshift.
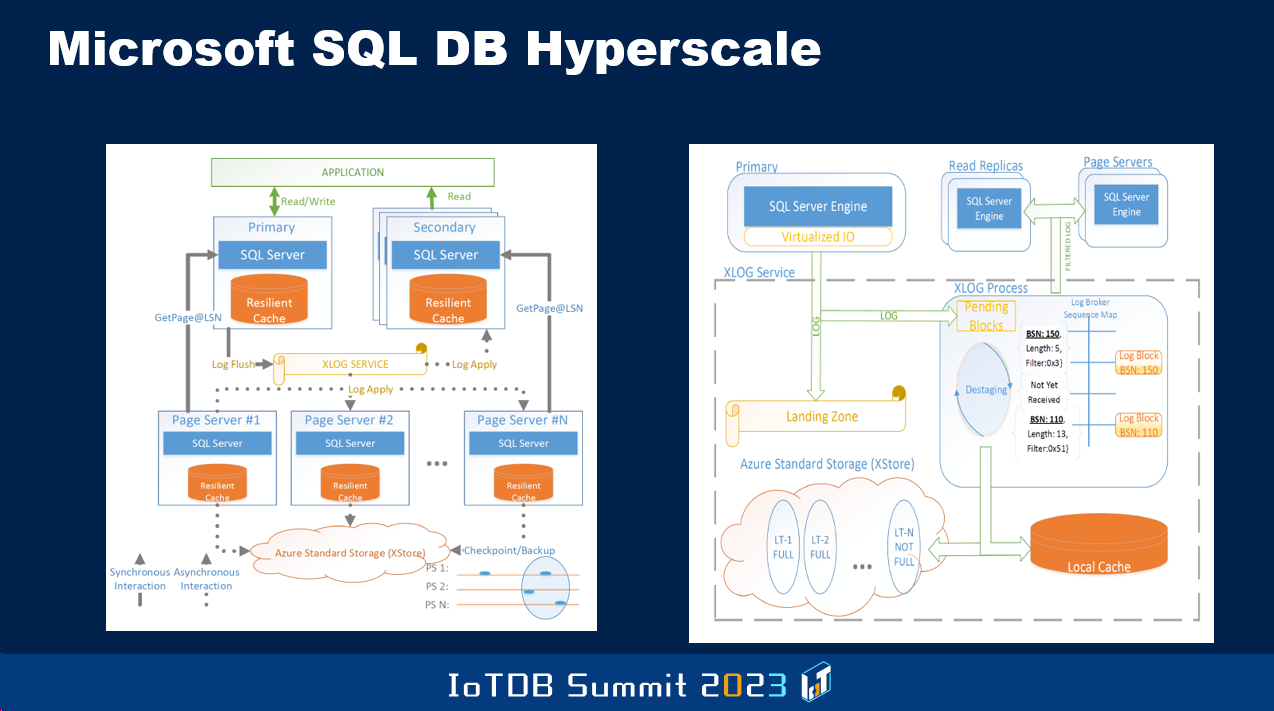
And then Microsoft SQL Server, as I told you being evolved. But a lot of these guys have a restriction, that you have only one node which can do read/right, the other nodes, compute nodes, can only do read. This is all age-old stuff you know. I worked on the late nineties, shared this architecture in the on-prem world, where multiple nodes can simultaneously have read/write capability. Oracle also with its Oracle Parallel Server to approach this. Those ideas need to be incorporated in the cloud DBMSes.
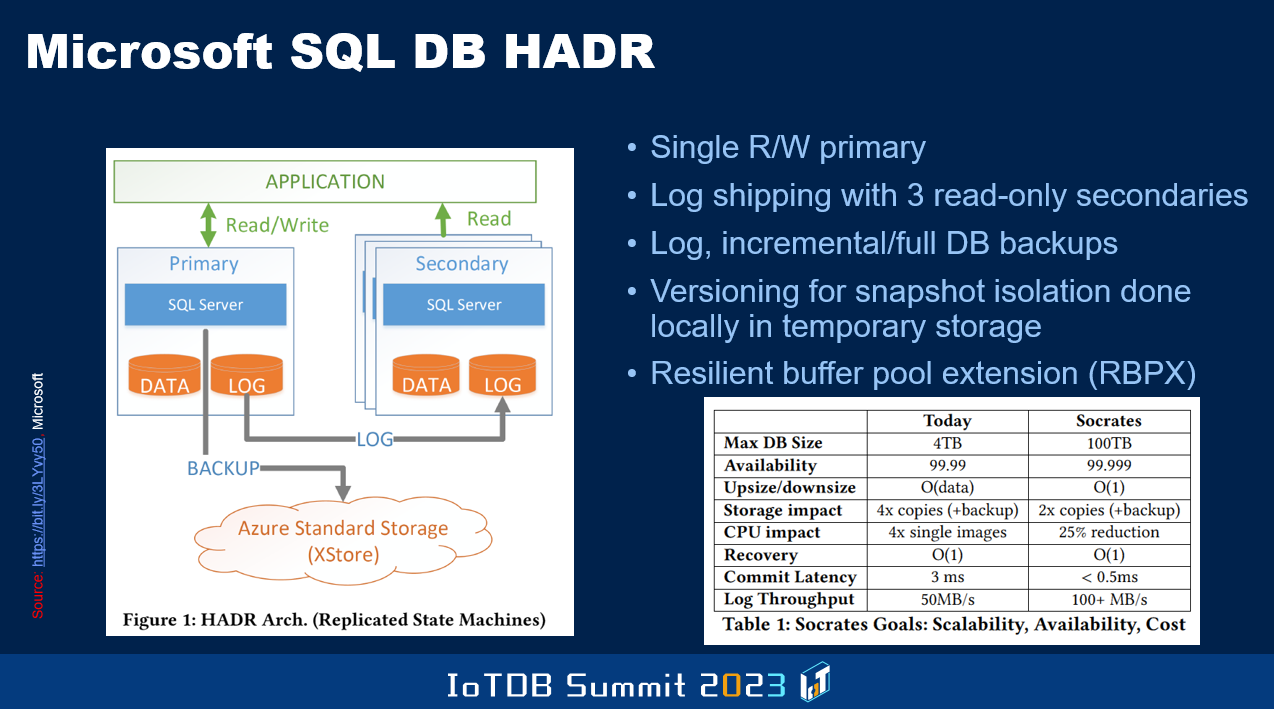
And improvements have to be made, so that you are not bound by the capacity of a single node with respect to the read/write workflow. Today that's a restriction, and also it's an availability bottleneck. If that node crashes, somebody else will take a while before they are able to take on the responsibility to allow for rights.
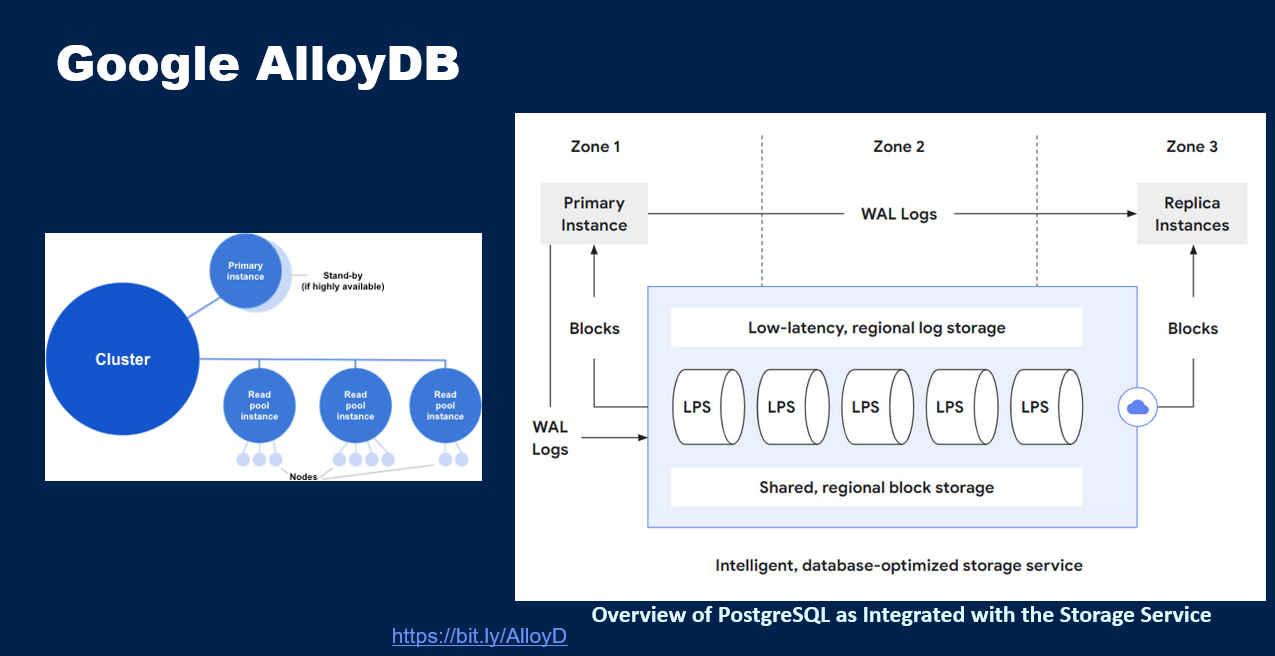
So these are the sorts of topics. And Google's AlloyDB is a super duper version compared to the Aurora PostgreSQL that Amazon guys developed, because it's a HTAP system.
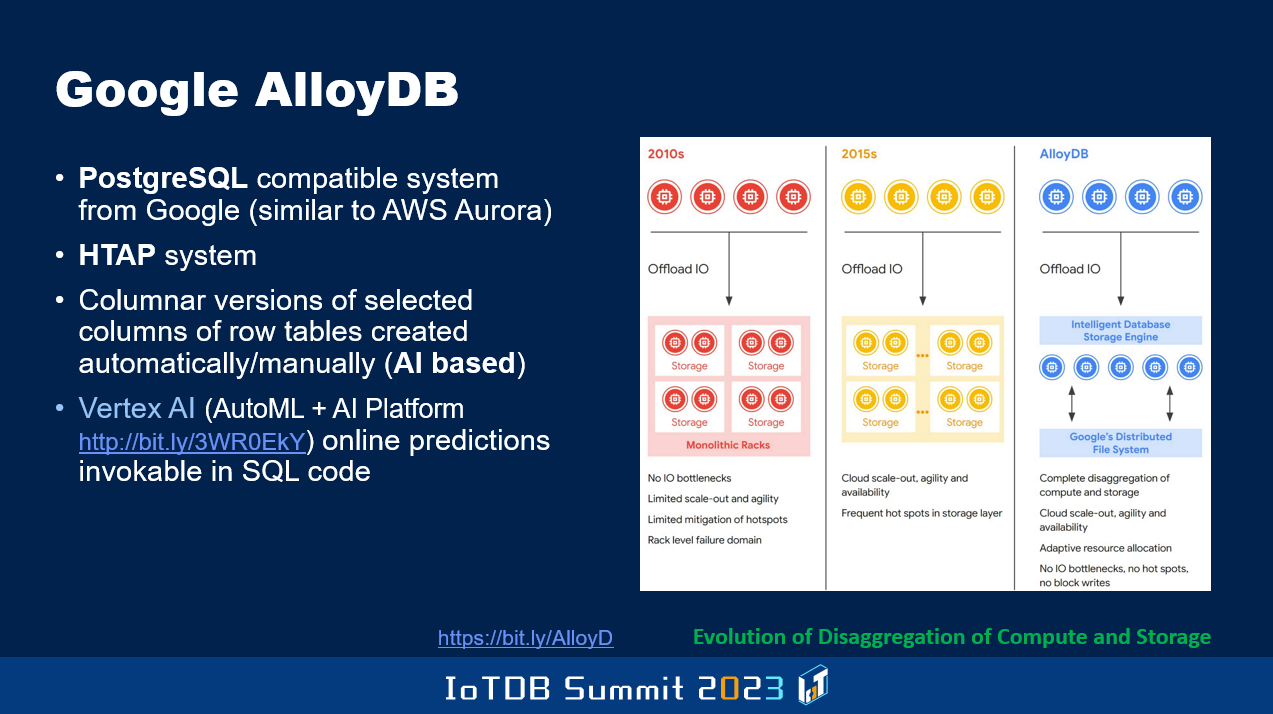
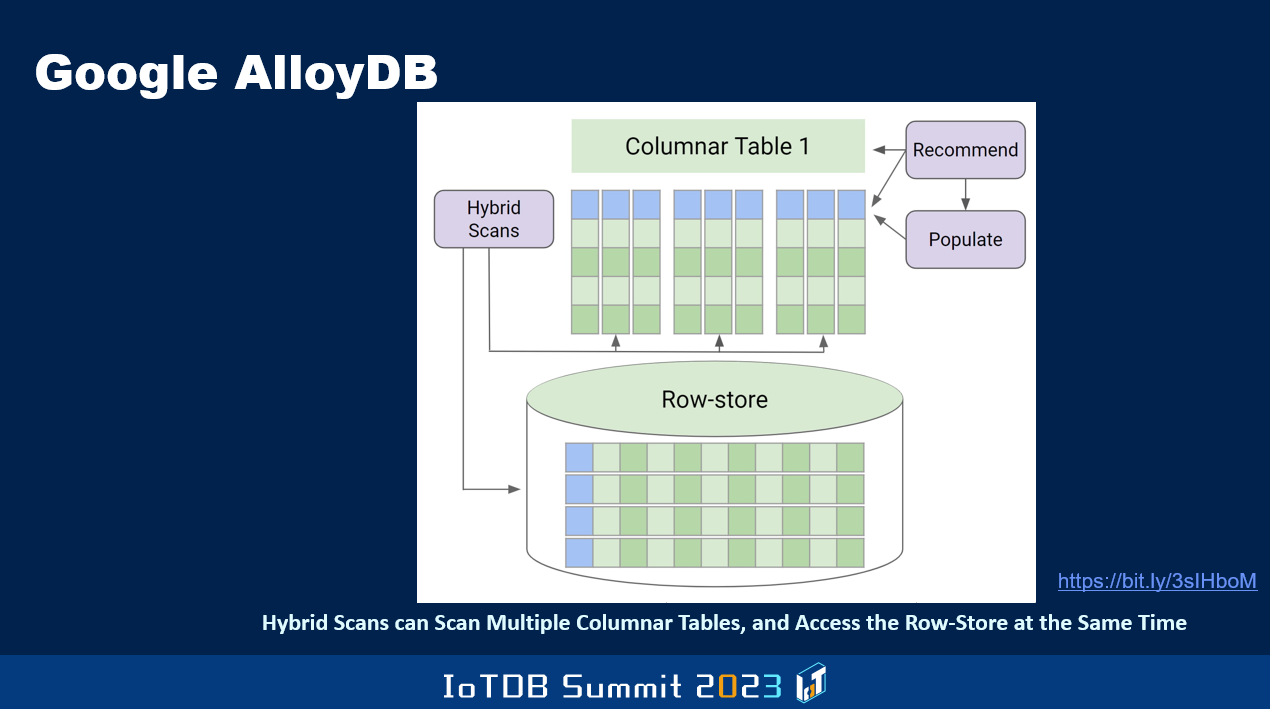
Not only row version, and a columnar version of some of the data can also be kept in order to make OLAP do better. And in fact, they leverage AI to know, dynamically by monitoring the workload and performance and so on, which of the columns of a given table might be beneficial for query performance to be maintained in a columnar way. This is very different from Oracle, where they said the DBA has to say for which row-oriented tables in addition to the row-oriented version, also maintain in memory columnar version of the whole table, all the columns. And if the system crashes, since it's only in memory, it will disappear and you have to recreate it when you come back. Whereas these guys are also focused on invoking AI functions from within a SQL query, so the data doesn't have to be dragged out of the DBMS before you are able to do machine learning and so on, so their Vertex AI calls can be made from within the DBMS.
Anyway, there's more of this kind of stuff. In summary, I tell technical people don't think that only if you are in the research world, you should be writing papers. But even as a product person, there are many reasons why it's a good idea to write papers because that will make your thinking clearer, and also you will be able to become an evangelist for your company's system so that others will be able to know about its goodness, and maybe even bad things. It's important to also talk about the negatives. And then they can do a more intelligent comparison of different kinds of products.
For instance, for a long time Google guys, the middleware they produced, was used only by their own product areas. Youtube, search, Android and so on. And as a result, these people didn't bother to give talks outside. Suddenly, when Google Cloud came, a subset of these middleware systems they chose to make available to try to make money with customers, being people that use Google Cloud, suddenly their product features that might have been bad, performance, standard compliance, availability of a whole tool ecosystem, all became visible. We know more about some of the other guys' products because they wrote papers, and their technical people had an external presence, and they interacted with other product people as well as research people. And so I sort of advise, even the Timecho people, to think about this, as I mentioned it the other day.
That's it, thank you.

Speaker
| Dr. Chandrasekaran Mohan Distinguished Professor of Science, Hong Kong Baptist University, China Distinguished Visiting Professor, Tsinghua University, China Member, Board of Governors, Digital University Kerala, India Member, United States National Academy of Engineering (NAE) Foreign Fellow, Indian National Academy of Engineering (INAE) ACM & IEEE Fellow | |



