

Industry-Leading
Time Series Database
For the IoT
Our mission is to revolutionize the field of big data by developing cutting-edge software solutions that empower enterprises to utilize the full potential of time-series data. From seamless data collection and storage to efficient querying, powerful analysis, and meaningful application, we strive to enable enterprises to extract maximum value from their data while minimizing costs.

Programming Example
Select your preferred programming language to view the corresponding source code
package org.apache.iotdb;
import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public class SessionExample {
private static Session session;
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
session =
new Session.Builder()
.host("172.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));
Tablet tablet = new Tablet("root.db.d1", schemaList, 10);
tablet.addTimestamp(0, 1);
tablet.addValue("s1", 0, 1.23f);
tablet.addValue("s2", 0, 1.23f);
tablet.addValue("s3", 0, 1.23f);
tablet.rowSize++;
session.insertTablet(tablet);
tablet.reset();
try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
}
session.close();
}
}from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tablet
ip = "127.0.0.1"
port = "6667"
username = "root"
password = "root"
session = Session(ip, port, username, password)
session.open(False)
measurements = ["s_01", "s_02", "s_03", "s_04", "s_05", "s_06"]
data_types = [
TSDataType.BOOLEAN,
TSDataType.INT32,
TSDataType.INT64,
TSDataType.FLOAT,
TSDataType.DOUBLE,
TSDataType.TEXT,
]
values = [
[False, 10, 11, 1.1, 10011.1, "test01"],
[True, 100, 11111, 1.25, 101.0, "test02"],
[False, 100, 1, 188.1, 688.25, "test03"],
[True, 0, 0, 0, 6.25, "test04"],
]
timestamps = [1, 2, 3, 4]
tablet = Tablet(
"root.db.d_03", measurements, data_types, values, timestamps
)
session.insert_tablet(tablet)
with session.execute_statement(
"select ** from root.db"
) as session_data_set:
while session_data_set.has_next():
print(session_data_set.next())
session.close()#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
int main(int argc, char **argv) {
Session *session = new Session("127.0.0.1", 6667, "root", "root");
session->open();
std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;
schemas.push_back({"s0", TSDataType::INT64});
schemas.push_back({"s1", TSDataType::INT64});
schemas.push_back({"s2", TSDataType::INT64});
int64_t val = 0;
Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);
tablet.rowSize++;
tablet.timestamps[0] = 0;
val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);
session->insertTablet(tablet);
tablet.reset();
std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");
while (res->hasNext()) {
std::cout << res->next()->toString() << std::endl;
}
res.reset();
session->close();
delete session;
return 0;
}package main
import (
"fmt"
"log"
"github.com/apache/iotdb-client-go/client"
)
func main() {
config := &client.Config{
Host: "127.0.0.1",
Port: "6667",
UserName: "root",
Password: "root",
}
session := client.NewSession(config)
if err := session.Open(false, 0); err != nil {
log.Fatal(err)
}
defer session.Close() // close session at end of main()
rowCount := 3
tablet, err := client.NewTablet("root.db.d1", []*client.MeasurementSchema{
{
Measurement: "restart_count",
DataType: client.INT32,
Encoding: client.RLE,
Compressor: client.SNAPPY,
}, {
Measurement: "price",
DataType: client.DOUBLE,
Encoding: client.GORILLA,
Compressor: client.SNAPPY,
}, {
Measurement: "description",
DataType: client.TEXT,
Encoding: client.PLAIN,
Compressor: client.SNAPPY,
},
}, rowCount)
if err != nil {
fmt.Errorf("Tablet create error:", err)
return
}
timestampList := []int64{0, 1, 2}
valuesInt32List := []int32{5, -99999, 123456}
valuesDoubleList := []float64{-0.001, 10e5, 54321.0}
valuesTextList := []string{"test1", "test2", "test3"}
for row := 0; row < rowCount; row++ {
tablet.SetTimestamp(timestampList[row], row)
tablet.SetValueAt(valuesInt32List[row], 0, row)
tablet.SetValueAt(valuesDoubleList[row], 1, row)
tablet.SetValueAt(valuesTextList[row], 2, row)
}
session.InsertTablet(tablet, false)
var timeoutInMs int64
timeoutInMs = 1000
sql := "select ** from root.db"
dataset, err := session.ExecuteQueryStatement(sql, &timeoutInMs)
defer dataset.Close()
if err == nil {
for next, err := dataset.Next(); err == nil && next; next, err = dataset.Next() {
record, _ := dataset.GetRowRecord()
fields := record.GetFields()
for _, field := range fields {
fmt.Print(field.GetValue(), "\t")
}
fmt.Println()
}
} else {
log.Println(err)
}
}Java
Python
C++
Go
-
Tens of Millions pts/s


Supports ingesting tens of millions of points per second on each node
-
100:1 Compression


Achieves over 10:1 lossless and up to 100:1 lossy compression
-
Millisecond Queries


Enables millisecond-level query response for terabyte-scale data
-
Billions of Tags

Handles tens of thousands of tags per device and billions across devices
Best Practices in the Industry
Addressing scenarios ranging from thousands to billions of data points
CRRC Qingdao Sifang
Contributed to an intelligent O&M system for urban rail vehicles. Deployed on 300 trains, each with 3,200 tags, for real-time monitoring, fault and trend analysis. Decreased data sampling time by 60%, reduced number of servers by 87%, reduced monthly data increment's storage space by 95%, handling 414B+ data points daily.


China National Nuclear Power
Deployed in nuclear power plants for critical equipment reliability. Handles big data storage, preprocessing, real-time failure monitoring. The platform supports 30+ servers and 1,000+ containers, serves 40K+ users, and stores 100TB+ data, achieving 99.99% reliability, second-level scheduling and deployment.


State Grid Corporation of China
Contributed to SGCC's precise power control terminals, IoT platforms, real-time measurement centers. Efficiently collects, caches, aggregates energy data. Manages millions of daily data increments, billions of points cumulatively. Supports concurrent access to devices, real-time writing of millions of data points per second.


Bosch Rexroth
Available on the ctrlX AUTOMATION platform for real-time data retrieval and historical time series management. Allows ingesting high data volumes on low-resource hardware. Integrated into various ctrlX CORE models, enabling data processing and synchronization between edge and central sides in industrial production with limited resources.


Changan Automobile
Applied as time series data solution for a huge fleet of smart connected vehicles. Currently linked to 570K+ vehicles with 80M+ tags, ingesting 1.5B+ points/sec. Boosted diagnostic queries from minutes to milliseconds with identical hardware.

Hunan Datang Xianyi Technology
Contributed to new energy time series data application system for 60 power plants within the Datang Group. Handles 1.7B+ data points daily at each plant, with total data points storage of 30T. Reduces O&M costs by 95%, offers custom functions, robust queries for analysis needs.

JD.com
Deployed in multiple sectors: digital energy, warehouses, smart homes, fueling digital homes, smart cities and energy innovation. Handles 50M+ tags per project, enabling high-throughput writing, millisecond-level queries, 5+ years data storage and millions of records per second via cloud-edge collaboration.


AVICAS Generic
Contributed to developing a cloud system, allowing data collection, processing, and exchange between onboard devices, production data storage, and cloud-based business systems. Provides efficient real-time data acquisition, storage, and querying solutions, leading to significant hardware storage cost savings.


Baosteel
Contributed to developing a remote intelligent maintenance platform. Currently manages 200B+ data points per time series, attains a writing speed of 30M+ points per second, a lossless compression ratio of 10:1, and ensures consistent real-time high-frequency data writing with millisecond ganularity.

Taiji Computer
Enhanced a remote analysis platform for 4 power plants with 11 generator units. Manages 80K+ tags, covering wind turbines, boilers, and power transmission devices. Achieved nanosecond data collection frequencies, cutting operational costs by 95%. Offers advanced data processing like Fourier transformation and wavelets.


China Meteorological Administration
Contributed to MICAPS4 meteorological forecast system development, storing real-time data from 100K national-level observation stations. Improved real-time data processing significantly, extended storage duration, and access capabilities within the system.

MCC CISDI Group
Engaged in essential data development and governance for the Soil-Water-Cloud industrial internet platform. Manages 30K+ devices, 250K+ tags, writes 1.5B+ records daily. Achieved a 132% point increase in writing, 50% better compression, and 100% faster queries. Supports 2+ years data storage, real-time visualization via Timecho Workbench.


Huawei
Collaborated in developing the MRS time-series database, improving consistency, scalability and introducing enterprise-grade attributes including security, transmission, encryption, reliability, and operations. Contributed to diverse enterprises' digital transformation and intelligent advancement.


Talkweb
Applied in building the Talkweb IoT system, establishing a three-tier platform for enterprises, factories, and production lines, enabling streamlined device management. Contributed to a 20% production cycle time reduction, 25% higher device utilization, a 25% boost in production efficiency and a 10% reduction of energy costs per unit output.

Alibaba Cloud
Contributed to the development of Alibaba Cloud's MaxCompute big data platform. Enhanced MPP architecture, cluster testing, cloud-edge synchronization, and query engines, providing advanced IoT data solutions for enterprises. Achieved 99.8% bandwidth reduction and 98% lower query latency compared to the original solution.

BONC
Contributed to Cloudiip Industrial Internet platform, spanning 20 sectors including metallurgy, electric power, and chemicals. Provides robust, real-time, and concurrent big data writing, slashing storage expenses by 90%. Enables historical and real-time data queries, analytics, and cloud-based industrial data integration.

Yonyou Software
Applied in building YonBIP Manufacturing Cloud, delivering post-sales solutions for diverse sectors: command center & safety monitoring in steel industry, production & equipment monitoring in chemicals and manufacturing industries, onboard operation & tracking systems in smart connected vehicles, etc.


Guantong Futures Brokerage
Developed a real-time tick data platform for futures markets. Stores 20 years of historical tick data from several stock-exchanges (SHFE, CFFEX, DCE, CZCE), covering 67+ futures and 1B+ daily data points. Ensures reliable system operation and rapid data retrieval.

Celebrated by Academia and Industry
Drawing global contributors to co-create an open-source community

C. Mohan
IBM Fellow, Member of US National Academy of Engineering
IoTDB has attained Apache Top-Level project status at a time of confluence of database, IoT, and AI technologies in conjunction with a wider adoption of Industry 4.0 and automation approaches to further enable remote work and increased efficiencies.

Xujia Liu
Head of Digital Innovation Center at CNNP
IoTDB's UDF (User-Defined Function) capability supports online preprocessing of time series data. After connecting a large number of measurement points for trend judgment and rule-based inference algorithms, it enables rolling trend analysis and achieves minute-level fault prediction. It significantly improves efficiency in terms of network transmission, low latency, and computational efficiency.

Li Huang
IT Supervisor at Changan Automobile Research Institute
Changan Automobile utilizes the high IO engine model of IoTDB, achieving millisecond-level returns for both single-car time range queries and single-car full-time series latest point queries. Compared to maintaining two sets of query solutions as before, the overall architecture complexity is significantly reduced.

Gang Liu
IoT Technology Leader at JD Technology
IoTDB has implemented a dedicated model for IoT scenarios, supporting a hierarchical structure where a single node can manage millions of devices or tens of millions of time series. The underlying TsFile, with a low-schema structure, enables plug-and-play effects at the edge. The distributed version of IoTDB achieves real-time data acquisition and aggregation calculations, realizing hierarchical storage management.

Shaofeng Xu
Chief Engineer at Baowu IEM
Apache IoTDB efficiently and stably supports the high-throughput and multi-frequency writing of massive time series data, covering the downsampling analysis of data throughout the entire lifespan of devices that spans up to ten years. It also meets the requirements of various data aggregation analysis queries and trend analysis models, saving us a significant amount of servers.

Chao Wang
R&D Manager of Huawei Cloud MRS-TSDB
IoTDB is open in terms of protocols and supports a SQL interface for convenient development and ease of use. It offers seamless integration with big data systems like Spark, HDFS, Hive, etc., enabling full utilization of the computational power of big data components.

Ruibo Li
Head of Alibaba Cloud's MaxCompute Ecosystem
Over the past two years, we have maintained close cooperation with the IoTDB community. Apache IoTDB, with its advanced architecture, superior performance, open and friendly community, has become our preferred choice for big data + IoT solutions.

Jian Bai
Alibaba Cloud Expert, Apache IoTDB Committer
IoTDB is a top-level Apache project and 100% open source. It has comprehensive documentation and an active community, licensed under the Apache 2.0 open-source license, which is highly business-friendly. Technically, IoTDB has a robust architecture with a built-in large-scale parallel processing framework, allowing scalable expansion. It exhibits excellent performance with high data compression ratio, low write latency, and low resource requirements, making it suitable for edge IoT data processing.

Julian Feinauer
CEO of pragmatic industries GmbH
In typical German application scenarios with limited available network bandwidth, IoTDB achieves out-of-the-box usability and compression ratios down to 20% of the original size, thanks to its highly compressed TsFile data transmission. This improvement results in approximately 5x performance gain.

Chao Wang
Head of Distributed Database Division at BONC
Apache IoTDB is an open, high-performance, and feature-rich database. It has a flexible core framework, strong extensibility, a thriving ecosystem, and can integrate with various big data platforms. It can write 20 million points per second on a single node, with query latency controllable within milliseconds. It supports multiple functionalities such as trigger writeback, continuous querying, cloud-edge synchronization, making it suitable for various business scenarios.
 2023-10-08
2023-10-08
Optimizing (I)IoT Performance: The Apache IoTDB Solution for Data Challenges
Apache IoTDB is a fascinating project, solving many complex problems easily by simple design choices. However, this flexibility does not come with hidden costs with respect to performance or complexity.
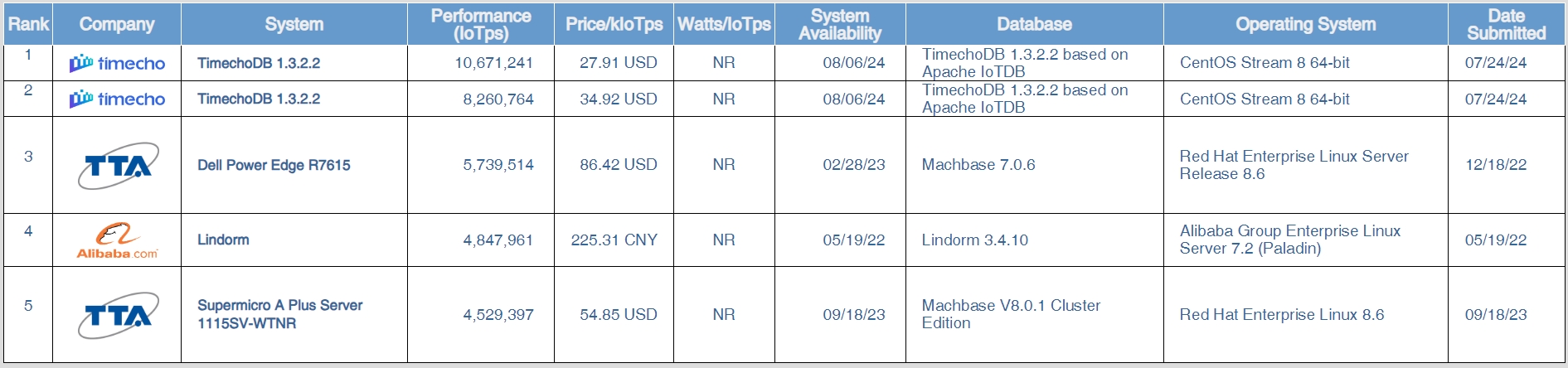
Apache IoTDB at the Core: New Records in TPCx-IoT Benchmarking
2024-09-10On August 6th, 2024, the Transaction Processing Performance Council (TPC) released TPCx-IoT benchmark results, highlighting TimechoDB (based on Apache

Three Different Deployment Forms of Apache IoTDB
2024-08-22Currently, Apache IoTDB supports three deployment forms—standalone deployment, cluster deployment, and dual-active deployment. This article will revea

Mastering Memory Settings for Apache IoTDB Clusters
2024-08-15Apache IoTDB is a comprehensive data management engine designed for the collection, storage, and analysis of time series data. The performance and sta


